Wirestock
Wirestock ist ein Marktplatz, der kreative Freelancer mit KI-Unternehmen verbindet und es Schöpfern ermöglicht, Geld zu verdienen, indem …
Wirestock ist ein Marktplatz, der kreative Freelancer mit KI-Unternehmen verbindet und es Schöpfern ermöglicht, Geld zu verdienen, indem sie hochwertige Bilder, Videos und Illustrationen für KI-Trainingsdatensätze beisteuern.
OneNine
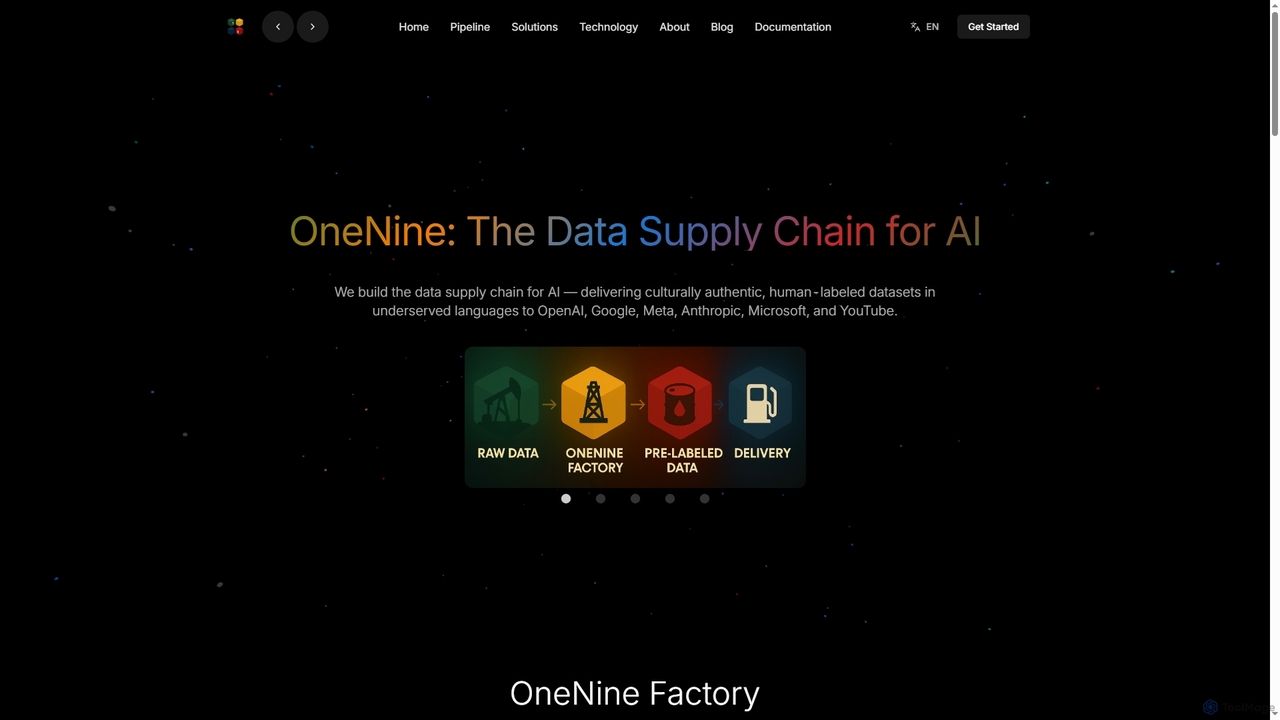
OneNine ist die Datenlieferkette für KI und spezialisiert auf die Bereitstellung hochwertiger, kulturell authentischer, von Menschen beschrifteter Datensätze …
OneNine ist die Datenlieferkette für KI und spezialisiert auf die Bereitstellung hochwertiger, kulturell authentischer, von Menschen beschrifteter Datensätze in unterversorgten Sprachen für führende KI-Unternehmen. Es überbrückt die sprachliche Kluft und ermöglicht weltweit inklusivere und präzisere KI-Modelle.

Sapien
Sapien ist eine dezentrale Daten-Foundry, die KI-Trainingsdaten auf Unternehmensebene bereitstellt. Es nutzt ein globales Netzwerk von menschlichen Mitwirkenden, …
Sapien ist eine dezentrale Daten-Foundry, die KI-Trainingsdaten auf Unternehmensebene bereitstellt. Es nutzt ein globales Netzwerk von menschlichen Mitwirkenden, um hochwertige, spezialisierte Daten für komplexe KI-Systeme zu liefern, einschließlich 3D/4D-Annotation, Experten-Reasoning und groß angelegter Datenerfassung.
Über Trainingsdaten
Trainingsdaten-Tools sind Plattformen und Dienste, die zur Erstellung, Verwaltung und Bereitstellung hochwertiger Datensätze für maschinelle Lernmodelle entwickelt wurden. Diese Tools optimieren den kritischen Prozess der Datenvorbereitung und bieten Funktionalitäten für Datenannotation, synthetische Datengenerierung und Qualitätssicherung. Ihr Hauptwert liegt in der Beschleunigung der Entwicklung präziser und robuster KI-Systeme, da die Leistung jedes Modells grundlegend von der Qualität seiner Trainingsdaten abhängt. Als Schlüsselkomponente im Lebenszyklus der KI-Entwicklung bilden sie die Grundlage, auf der effektive Modelle aufgebaut werden.
Kernfunktionen
- Datenannotation & -kennzeichnung: Bietet Schnittstellen und automatisierte Werkzeuge zur präzisen Kennzeichnung verschiedener Datentypen wie Bilder, Text und Audio, um eine Ground Truth für Modelle zu erstellen.
- Synthetische Datengenerierung: Erstellt künstliche, aber realistische Daten, um begrenzte Datensätze zu erweitern, Randfälle abzudecken oder sensible Informationen zu schützen.
- Datenmanagement & -versionierung: Bietet eine zentrale Plattform zum Speichern, Verfolgen und Verwalten verschiedener Versionen von Datensätzen, um die Reproduzierbarkeit von Experimenten zu gewährleisten.
- Qualitätssicherungs-Workflows: Umfasst Funktionen für Überprüfung, Konsens und Fehlererkennung, um hohe Standards an Datengenauigkeit und -konsistenz aufrechtzuerhalten.
- Datensatzbeschaffung: Bietet Zugang zu vorannotierten, sofort einsatzbereiten Datensätzen oder Diensten zur Sammlung und Vorbereitung benutzerdefinierter Daten.
Anwendungsfälle
Diese Tools sind in datenintensiven Branchen wie autonomen Fahrzeugen zur Objekterkennung, im Gesundheitswesen zur medizinischen Bildanalyse und im Einzelhandel zur Produktkategorisierung unerlässlich. Machine-Learning-Ingenieure, Datenwissenschaftler und KI-Forscher nutzen sie täglich, um Datensätze für Aufgaben von der Verarbeitung natürlicher Sprache bis zur Computer Vision zu erstellen und zu verfeinern.
Auswahlkriterien
Bei der Auswahl eines Trainingsdaten-Tools sollten Sie die Unterstützung für Ihre spezifischen Datentypen (z. B. Video, 3D-Punktwolken) berücksichtigen. Bewerten Sie die Qualitätskontrollmechanismen wie Gutachterrollen und Konsensbewertung. Beurteilen Sie die Skalierbarkeit für Großprojekte und die Fähigkeit zur Integration in Ihre bestehende MLOps-Pipeline und Ihren Cloud-Speicher. Überprüfen Sie schließlich die Sicherheitsprotokolle und die Einhaltung von Datenschutzbestimmungen wie DSGVO oder HIPAA.
TrainingsdatenAnwendungsfälle
Training von Wahrnehmungsmodellen für autonome Fahrzeuge
Ein Automobiltechnologieunternehmen, das selbstfahrende Autos entwickelt, muss seine Computer-Vision-Modelle trainieren, um Fußgänger, Fahrzeuge, Verkehrsschilder und Fahrbahnmarkierungen genau zu identifizieren. Mithilfe einer Datenannotationsplattform führt ein Team von Annotatoren semantische Segmentierung und Bounding-Box-Annotationen an Millionen von Bildern und Videoframes durch, die bei Straßentests aufgenommen wurden. Die Qualitätskontrollfunktionen der Plattform, wie Konsensbewertung und Gutachter-Workflows, gewährleisten eine hohe Genauigkeit. Dieser sorgfältig annotierte Datensatz ist entscheidend für das Training von Wahrnehmungsmodellen, die sicher in komplexen städtischen Umgebungen navigieren können.
Entwicklung einer KI für die medizinische Bilddiagnose
Ein Gesundheitsforschungsinstitut möchte ein KI-Modell entwickeln, um Tumore im Frühstadium in MRT-Scans zu erkennen. Aufgrund des Mangels an erfahrenen Radiologen und der hohen Kosten für die manuelle Annotation verwenden sie ein spezialisiertes Tool zur Annotation medizinischer Bilder. Dieses Tool bietet Funktionen wie DICOM-Unterstützung und halbautomatische Segmentierung, was den Prozess beschleunigt. Zum Schutz der Patientendaten werden alle Daten innerhalb der Plattform anonymisiert. Der resultierende hochwertige, annotierte Datensatz ermöglicht es dem Data-Science-Team, ein Modell zu trainieren, das Radiologen unterstützen kann, indem es potenziell bedenkliche Bereiche hervorhebt, was zu früheren und genaueren Diagnosen führt.
Generierung synthetischer Daten zur Betrugserkennung
Ein Finanzdienstleistungsunternehmen möchte sein Betrugserkennungsmodell verbessern, ist aber durch die geringe Anzahl echter Betrugsfälle und strenge Datenschutzbestimmungen eingeschränkt. Sie verwenden ein Tool zur Generierung synthetischer Daten, um einen großen, ausgewogenen Datensatz von Finanztransaktionen zu erstellen. Das Tool modelliert die statistischen Eigenschaften ihrer realen Daten, um realistische, aber vollständig künstliche Transaktionsdatensätze zu generieren, einschließlich komplexer Betrugsszenarien, die in der realen Welt selten sind. Dies ermöglicht es ihnen, ein robusteres Modell zu trainieren, ohne sensible Kundendaten zu verwenden, wodurch die Erkennungsraten verbessert und die vollständige Einhaltung der Vorschriften gewährleistet wird.
Verbesserung der E-Commerce-Produktkategorisierung
Ein Online-Handelsriese verwaltet Millionen von Produkten, und die manuelle Kategorisierung neuer Artikel ist langsam und fehleranfällig. Sie nutzen einen Datenkennzeichnungsdienst, um einen großen Datensatz von Produktbildern und -beschreibungen zu klassifizieren. Der Dienst verwendet eine Kombination aus menschlichen Annotatoren und KI-gestützter Vorkennzeichnung, um Produkte effizient in eine detaillierte Taxonomie einzuordnen. Diese gekennzeichneten Daten werden dann verwendet, um ein maschinelles Lernmodell zu trainieren, das neuen, auf der Website hochgeladenen Produkten automatisch Kategorien zuweist, was den manuellen Aufwand erheblich reduziert, die Suchrelevanz verbessert und das Einkaufserlebnis der Kunden optimiert.
Verwaltung von Datensätzen für die Reproduzierbarkeit von NLP-Modellen
Ein KI-Forschungslabor entwickelt ein neues Sprachmodell und muss Hunderte von Experimenten mit verschiedenen Versionen seines Textkorpus durchführen. Um sicherzustellen, dass ihre Ergebnisse reproduzierbar sind, verwenden sie eine Plattform zur Datenverwaltung und -versionierung. Dieses Tool ermöglicht es ihnen, jede Änderung am Datensatz zu verfolgen, bestimmte Datensatzversionen mit Modelltrainingsläufen zu verknüpfen und einfach zu früheren Zuständen zurückzukehren. Es funktioniert wie 'Git für Daten', bietet einen klaren Audit-Trail und verhindert Verwirrung. Dieser systematische Ansatz ist für die kollaborative Forschung und die Veröffentlichung überprüfbarer wissenschaftlicher Erkenntnisse unerlässlich.
Überprüfung von Datensätzen auf Voreingenommenheit in Einstellungsalgorithmen
Ein Unternehmen für Personaltechnologie entwickelt ein KI-Tool zur Unterstützung bei der Überprüfung von Lebensläufen. Um die Fortführung historischer Vorurteile zu verhindern, verwenden sie ein Tool zur Datenqualitätssicherung, um ihren Trainingsdatensatz zu überprüfen. Das Tool analysiert die Verteilung demografischer Daten (z. B. Geschlecht, ethnische Zugehörigkeit) und identifiziert potenzielle Ungleichgewichte oder Korrelationen, die zu unfairen Ergebnissen führen könnten. Es liefert Visualisierungen und statistische Berichte, die dem Data-Science-Team helfen, Voreingenommenheit vor dem Modelltraining zu erkennen und zu mindern. Dieser proaktive Schritt ist entscheidend für die Entwicklung verantwortungsvoller und ethischer KI-Systeme, die faire Einstellungspraktiken fördern.