Edgee
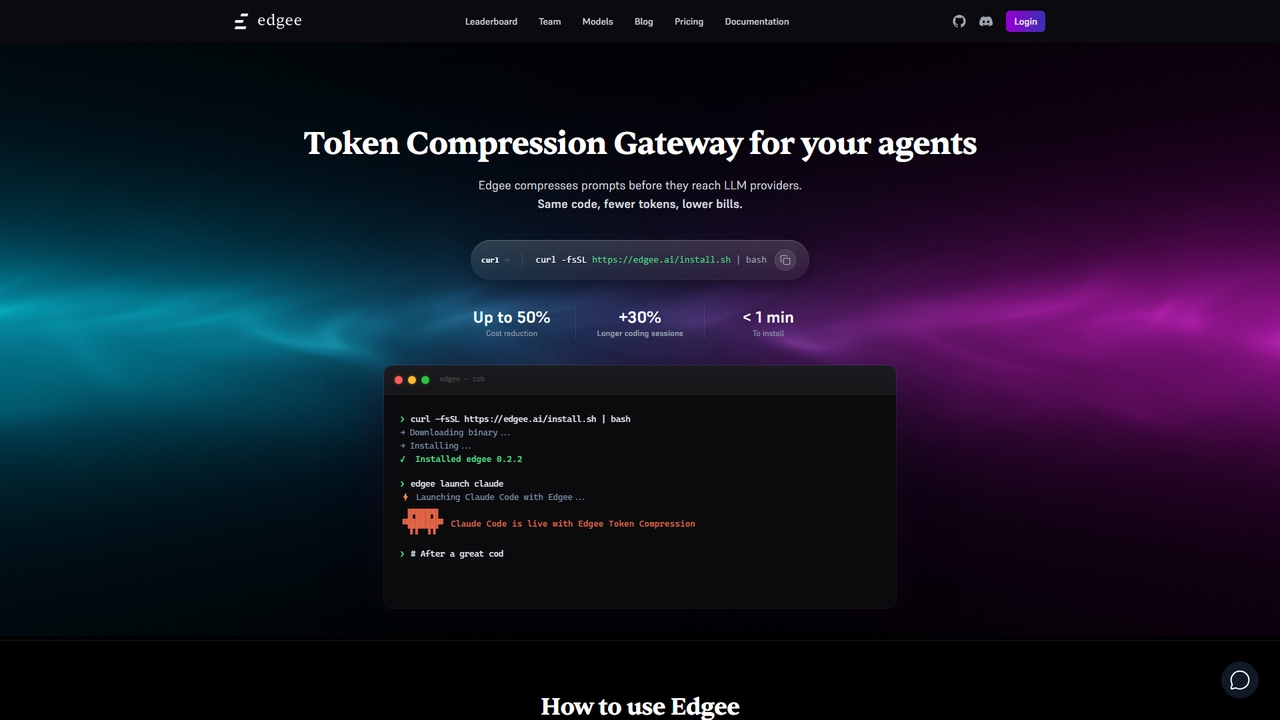
Edgee ist ein Token-Komprimierungs-Gateway, das die Kosten für LLM-Prompts um bis zu 50 % senkt. Es arbeitet transparent …
Edgee ist ein Token-Komprimierungs-Gateway, das die Kosten für LLM-Prompts um bis zu 50 % senkt. Es arbeitet transparent mit Coding-Agenten wie Claude, Codex und Cursor zusammen.
APIPark
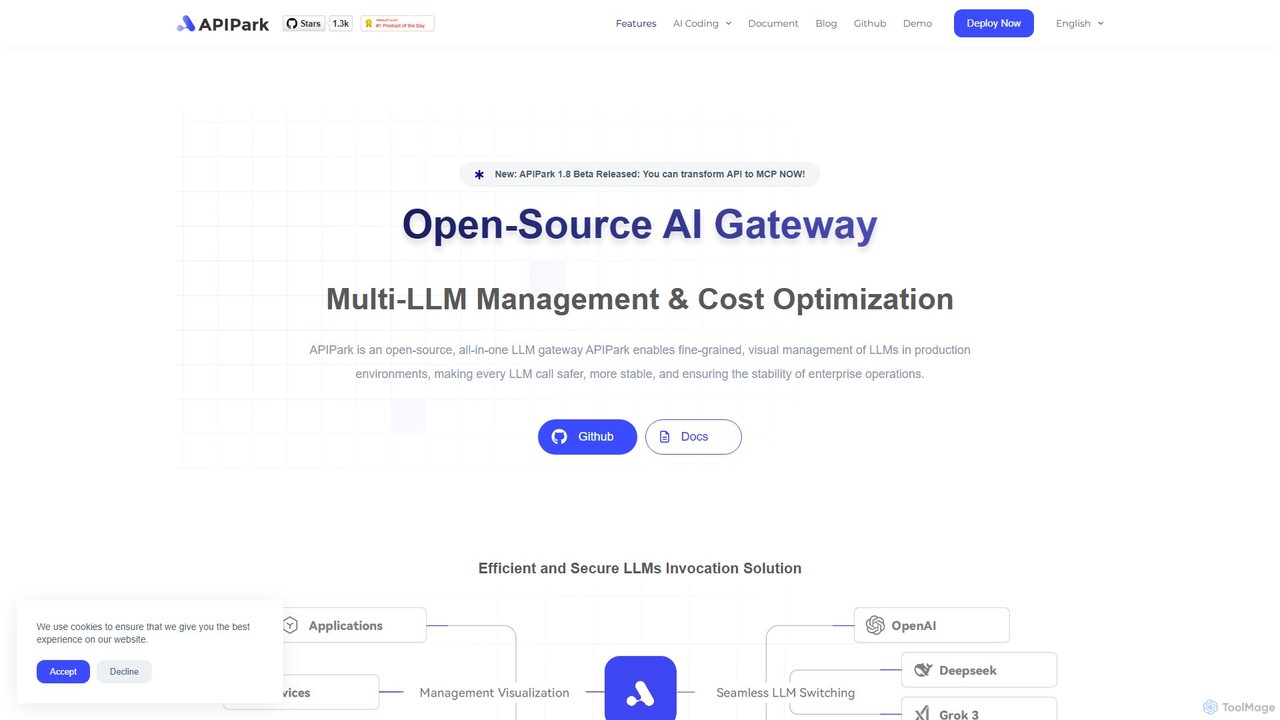
APIPark ist ein Open-Source-KI-Gateway und Entwicklerportal, das Unternehmen dabei unterstützt, KI-Dienste effizient zu verwalten, zu integrieren und bereitzustellen. …
APIPark ist ein Open-Source-KI-Gateway und Entwicklerportal, das Unternehmen dabei unterstützt, KI-Dienste effizient zu verwalten, zu integrieren und bereitzustellen. Es zentralisiert LLM-Aufrufe, senkt Kosten und bietet Werkzeuge für API-Freigabe, Überwachung und Sicherheit.
Über LLM-Gateway
LLM-Gateways sind spezialisierte Middleware-Tools, die den Zugriff auf mehrere große Sprachmodelle (LLMs) verwalten und optimieren. Sie fungieren als einheitliche API-Schicht, die zwischen Anwendungen und verschiedenen LLM-Anbietern wie OpenAI, Anthropic oder Google positioniert ist. Diese zentralisierte Steuerung ermöglicht es Entwicklern, Anfragen zu leiten, API-Schlüssel zu verwalten und die Nutzung zu überwachen, ohne an ein einziges Modell-Ökosystem gebunden zu sein. Als wichtiger Teil der KI-Infrastruktur sind LLM-Gateways unerlässlich für die Erstellung skalierbarer, kosteneffizienter und widerstandsfähiger KI-gestützter Anwendungen.
Kernfunktionen
- Einheitlicher API-Endpunkt: Greifen Sie über eine einzige, konsistente Schnittstelle auf verschiedene LLMs von mehreren Anbietern zu.
- Intelligentes Routing & Failover: Leiten Sie Anfragen automatisch an das optimale Modell basierend auf Kosten, Latenz oder Verfügbarkeit weiter, mit nahtlosem Failover.
- Kostenmanagement & -kontrolle: Verfolgen Sie die Token-Nutzung in Echtzeit, legen Sie Budgets fest und erzwingen Sie Ratenbegrenzungen, um unerwartete Ausgaben zu vermeiden.
- Performance-Caching: Speichern und wiederverwenden Sie Antworten auf häufige Anfragen, um die Latenz zu reduzieren und redundante API-Aufrufe zu minimieren.
- Zentralisierte Beobachtbarkeit: Konsolidieren Sie Protokolle, Metriken und Traces von allen LLM-Interaktionen für eine vereinfachte Überwachung und Fehlerbehebung.
Anwendungsfälle
LLM-Gateways werden häufig von Technologieunternehmen, die KI-native Produkte entwickeln, von Unternehmen, die generative KI in bestehende Arbeitsabläufe integrieren, und von Entwicklungsteams, die Modellflexibilität benötigen, eingesetzt. Sie sind besonders wertvoll in Produktionsumgebungen zur Verwaltung von Multi-Cloud- oder Multi-Modell-Strategien, zur Optimierung der Betriebskosten und zur Gewährleistung der Anwendungszuverlässigkeit.
Wie man wählt
Bei der Auswahl eines LLM-Gateways sollten Sie die Bandbreite der unterstützten LLM-Anbieter, die Bereitstellungsoptionen (Cloud vs. Self-Hosted), die Komplexität der Routing- und Caching-Regeln sowie die Integrationsfähigkeiten mit Ihrem bestehenden Beobachtbarkeits-Stack (z. B. Protokollierungs- und Überwachungstools) berücksichtigen. Bewerten Sie auch die Sicherheitsfunktionen und den durch das Gateway verursachten Latenz-Overhead.
LLM-GatewayAnwendungsfälle
Unternehmensweite Multi-Modell-KI-Integration
Ein Unternehmensentwicklungsteam muss generative KI-Funktionen in mehrere interne Anwendungen wie ein CRM und eine Wissensdatenbank integrieren. Anstatt separate Integrationen für jeden LLM-Anbieter zu erstellen, setzen sie ein LLM-Gateway ein. Dies bietet einen einzigen, sicheren Endpunkt für alle Anwendungen. Das Gateway ist so konfiguriert, dass es Anfragen mit sensiblen Daten an ein selbst gehostetes, privates Modell weiterleitet, während allgemeine Aufgaben zur Inhaltserstellung an das kostengünstigste kommerzielle Modell gesendet werden. dieser Ansatz vereinfacht die Wartung, setzt Sicherheitsrichtlinien zentral durch und vermeidet eine Anbieterabhängigkeit.
Kostenkontrolle für eine SaaS-Anwendung
Ein SaaS-Unternehmen bietet seinen Kunden in verschiedenen Preisstufen eine KI-gestützte Funktion zur Inhaltszusammenfassung an. Zur Verwaltung der Betriebskosten verwenden sie ein LLM-Gateway. Das Gateway erzwingt strenge monatliche Token-Limits für jeden Kunden basierend auf seinem Abonnementplan. Es liefert auch detaillierte Analysen zu Nutzungsmustern, die dem Produktteam helfen, die Kosten pro Funktion zu verstehen und die Preisgestaltung anzupassen. Darüber hinaus konfigurieren sie eine Regel, um Anfragen von kostenlosen Nutzern an ein günstigeres, etwas weniger leistungsfähiges Modell weiterzuleiten und die Premium-Modelle für zahlende Kunden zu reservieren.
Sicherstellung der Hochverfügbarkeit durch Modell-Failover
Eine Kundenservice-Plattform verlässt sich auf einen KI-Chatbot, der rund um die Uhr verfügbar sein muss. Um Ausfallzeiten durch Ausfälle von LLM-Anbietern oder Leistungseinbußen zu vermeiden, implementiert das DevOps-Team ein LLM-Gateway. Sie konfigurieren ein primäres Modell für alle Anfragen, richten aber ein sekundäres Modell von einem anderen Anbieter als Backup ein. Das Gateway überwacht kontinuierlich den Zustand und die Latenz des primären Modells. Wenn es ein Problem erkennt, leitet es den gesamten Verkehr automatisch und nahtlos auf das Backup-Modell um, bis der primäre Dienst wiederhergestellt ist, und gewährleistet so einen ununterbrochenen Service für die Endbenutzer.
A/B-Tests von LLMs für optimale Leistung
Ein Produktteam möchte feststellen, ob ein neues, feinabgestimmtes Open-Source-Modell für ihren spezifischen Anwendungsfall bessere Ergebnisse liefert als ihr aktuelles kommerzielles LLM. Mit einem LLM-Gateway richten sie einen A/B-Test ein. Das Gateway ist so konfiguriert, dass es 10 % des Benutzerverkehrs an das neue Modell weiterleitet, während die anderen 90 % weiterhin das bestehende Modell verwenden. Durch die zentralisierte Protokollierung des Gateways kann das Team wichtige Metriken wie die Antwortqualität (über Benutzerfeedback), die Latenz und die Kosten pro Anfrage für beide Modelle leicht vergleichen. Dieser datengesteuerte Ansatz ermöglicht es ihnen, eine fundierte Entscheidung zu treffen, ohne die Benutzererfahrung zu stören.
Zentralisierte Prompt-Verwaltung und Versionierung
Ein großes Team von Entwicklern und Prompt-Ingenieuren arbeitet an einer Anwendung mit Dutzenden von KI-gesteuerten Funktionen. Die Verwaltung und Aktualisierung von Prompts direkt im Anwendungscode ist langsam und fehleranfällig. Sie führen ein LLM-Gateway ein, das ein Prompt-Management-System enthält. Dies ermöglicht es ihnen, Prompt-Vorlagen von einem zentralen Dashboard aus zu speichern, zu versionieren und bereitzustellen. Wenn ein Prompt verbessert werden muss, kann ein Prompt-Ingenieur ihn in der Benutzeroberfläche des Gateways aktualisieren, und die Änderung wird sofort in der Anwendung widergespiegelt, ohne dass eine neue Code-Bereitstellung erforderlich ist. Dies entkoppelt das Prompt-Engineering vom Softwareentwicklungslebenszyklus.
Implementierung von semantischem Caching für die Leistung
Eine Plattform zur Analyse von Finanznachrichten macht häufige, ähnliche API-Aufrufe an ein LLM, um Eilmeldungen zusammenzufassen. Um die Latenz zu reduzieren und Kosten zu senken, verwenden sie ein LLM-Gateway mit semantischen Caching-Funktionen. Wenn eine Anfrage zur Zusammenfassung eines neuen Artikels eingeht, prüft das Gateway zunächst seinen Cache auf semantisch ähnliche Anfragen. Wenn eine ausreichend ähnliche Zusammenfassung bereits vorhanden ist, gibt es die zwischengespeicherte Antwort sofort zurück und vermeidet so einen kostspieligen Aufruf an das LLM. Dies verbessert die Antwortzeiten für Benutzer, die beliebte Nachrichtenartikel ansehen, erheblich und reduziert die gesamten API-Ausgaben um über 40 %.