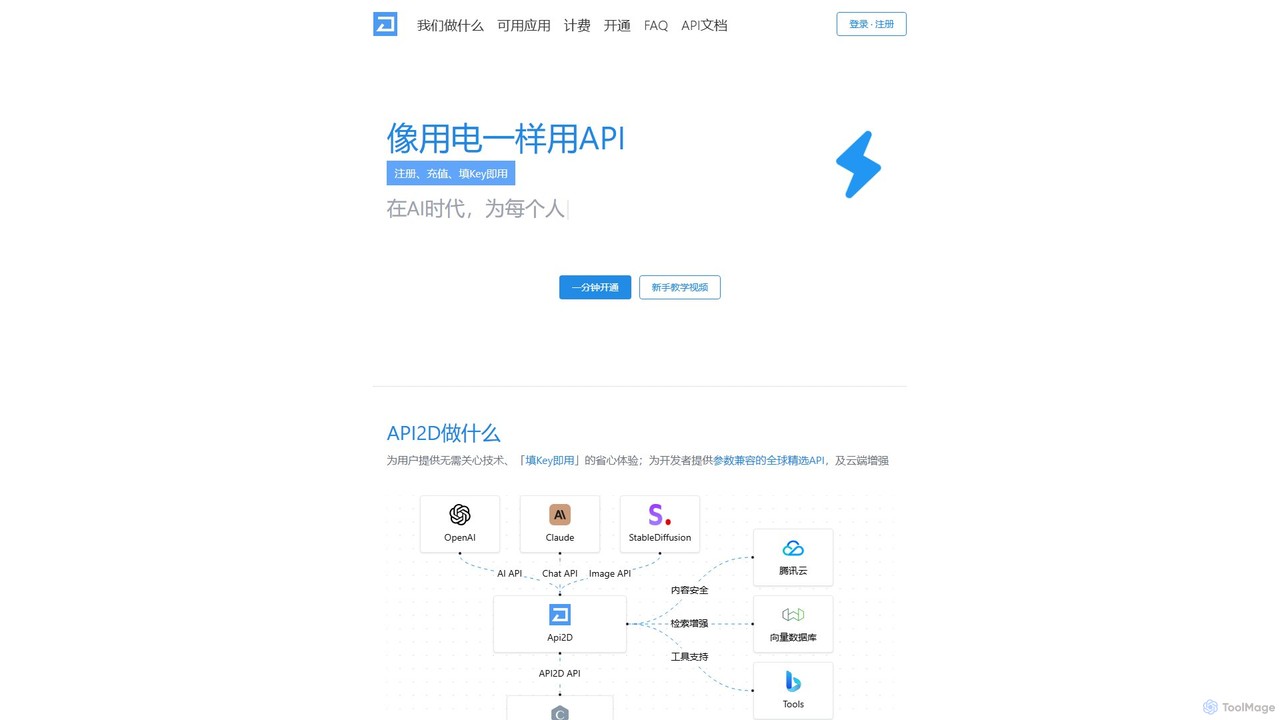
API2D
API2D ist ein API-Aggregator- und Proxy-Dienst, der den Zugriff auf führende KI-Modelle wie GPT-4, Claude und Stable Diffusion …
API2D ist ein API-Aggregator- und Proxy-Dienst, der den Zugriff auf führende KI-Modelle wie GPT-4, Claude und Stable Diffusion vereinfacht. Er bietet einen einzigen, einheitlichen API-Schlüssel, der mit den OpenAI-Standards kompatibel ist und eine einfache Integration in Hunderte von bestehenden Anwendungen ermöglicht. Mit einem Pay-as-you-go-Preismodell und Funktionen wie Caching und Inhaltssicherheit bietet API2D eine bequeme und kostengünstige Lösung für Entwickler und Benutzer, um leistungsstarke KI-Fähigkeiten ohne komplexe Setups oder geografische Einschränkungen zu nutzen.
Über Middleware
KI-Middleware ist eine Softwareschicht, die die Kommunikation zwischen verschiedenen Komponenten einer KI-Anwendung, wie Modellen, Datenquellen und Benutzeroberflächen, verbindet und verwaltet. Diese Tools bieten eine standardisierte Infrastruktur für die Bereitstellung, Skalierung und Überwachung von KI-Modellen und fungieren als zentrales Nervensystem für komplexe KI-Systeme. Durch die Abstraktion von Low-Level-Verbindungen ermöglicht Middleware Entwicklern, robuste, produktionsreife KI-Dienste effizienter zu erstellen. Es ist eine entscheidende Komponente der KI-Infrastruktur, um Interoperabilität und Betriebsstabilität zu gewährleisten.
Kernfunktionen
- Modell-Serving & Bereitstellung: Verpackt KI-Modelle in skalierbare, hochleistungsfähige API-Endpunkte.
- API-Gateway & Verwaltung: Bietet einen einheitlichen Einstiegspunkt zur Verwaltung von Traffic, Sicherheit, Authentifizierung und Ratenbegrenzung für KI-Dienste.
- Workflow-Orchestrierung: Definiert und automatisiert mehrstufige Prozesse, die mehrere Modelle oder Datenquellen umfassen.
- Anfrage- & Antworttransformation: Konvertiert automatisch Datenformate zwischen Anwendungen und KI-Modellen.
- Beobachtbarkeit & Überwachung: Verfolgt die Modellleistung, Latenz, Fehlerraten und Ressourcennutzung in Echtzeit.
Anwendungsfälle
KI-Middleware wird hauptsächlich von MLOps-Ingenieuren, Backend-Entwicklern und IT-Teams in Unternehmen verwendet. Sie ist unerlässlich für den Aufbau von produktionsreifen Systemen wie Echtzeit-Betrugserkennungs-APIs, multimodalen KI-Assistenten, die Sprach- und Bildmodelle kombinieren, und skalierbaren Empfehlungs-Engines für E-Commerce-Plattformen. Sie hilft bei der Verwaltung der Komplexität von auf Microservices basierenden KI-Architekturen.
Wie man wählt
Bei der Auswahl von KI-Middleware bewerten Sie deren Skalierbarkeit und Leistung unter hoher Last. Prüfen Sie die Kompatibilität mit Ihren spezifischen Modell-Frameworks (z. B. TensorFlow, PyTorch, ONNX). Beurteilen Sie die Integrationsfähigkeiten mit Ihrer bestehenden Cloud-Infrastruktur, Datenbanken und CI/CD-Pipelines. Berücksichtigen Sie schließlich die Robustheit der Überwachungs-, Protokollierungs- und Sicherheitsfunktionen zur Aufrechterhaltung der Produktionsstabilität.
MiddlewareAnwendungsfälle
Bereitstellung einer Echtzeit-Betrugserkennungs-API
Ein Fintech-Unternehmen muss ein maschinelles Lernmodell einsetzen, um betrügerische Transaktionen in Echtzeit zu erkennen. Ein MLOps-Ingenieur verwendet ein KI-Middleware-Tool, um das trainierte Modell in einen sicheren API-Endpunkt mit geringer Latenz zu verpacken. Die Middleware verarbeitet eingehende Transaktionsdaten, verwaltet die Authentifizierung, leitet Anfragen an horizontal skalierte Modellinstanzen zur Bewertung weiter und gibt innerhalb von Millisekunden einen Betrugswahrscheinlichkeitswert zurück. Diese Einrichtung gewährleistet eine hohe Verfügbarkeit und kann Tausende von Transaktionen pro Sekunde ohne manuellen Eingriff verarbeiten.
Orchestrierung einer multimodalen Inhaltsanalyse-Pipeline
Ein Medienanalyseunternehmen möchte einen Workflow zur Analyse von Videoinhalten erstellen. Ein Entwickler verwendet KI-Middleware, um eine mehrstufige Pipeline zu orchestrieren. Zuerst sendet die Middleware die Videodatei an ein Speech-to-Text-Modell. Anschließend leitet sie das resultierende Transkript gleichzeitig an ein Stimmungsanalysemodell und ein Themenextraktionsmodell weiter. Parallel dazu sendet sie Videoframes an ein Objekterkennungsmodell. Schließlich fasst die Middleware alle Ausgaben in einem einzigen, strukturierten JSON-Bericht zusammen. Dies automatisiert einen komplexen Prozess, der zuvor erhebliche manuelle Koordination erforderte.
Verwaltung mehrerer LLM-Anbieter über ein einziges Gateway
Ein Unternehmen möchte mehrere große Sprachmodelle (LLMs) von verschiedenen Anbietern (z. B. OpenAI, Anthropic, Google) nutzen, ohne sich an einen einzigen Anbieter zu binden. Ein IT-Architekt implementiert eine KI-Middleware-Lösung als einheitliches API-Gateway. Anwendungsentwickler können nun Anfragen an einen einzigen internen Endpunkt senden. Die Middleware leitet die Anfrage dann intelligent an das kostengünstigste oder leistungsstärkste LLM weiter, basierend auf vordefinierten Regeln. Sie standardisiert auch das API-Format, was die Entwicklung vereinfacht und es dem Unternehmen ermöglicht, LLM-Anbieter nahtlos zu wechseln.
Skalierung einer E-Commerce-Empfehlungs-Engine
Die Empfehlungs-Engine eines Online-Händlers erlebt während der Feiertagsverkäufe enorme Verkehrsspitzen. Um die Stabilität zu gewährleisten, verwendet das Betriebsteam KI-Middleware zur Verwaltung der Modellbereitstellung. Die Middleware skaliert die Anzahl der Modellinstanzen automatisch je nach Echtzeitverkehr nach oben oder unten und gewährleistet so eine geringe Latenz für die Benutzer. Sie bietet auch Lastausgleich zur gleichmäßigen Verteilung von Anfragen und implementiert Caching für häufig angeforderte Empfehlungen, was die Last auf dem Kernmodell reduziert und die Infrastrukturkosten erheblich senkt, während die Benutzererfahrung verbessert wird.
Zentralisierte Überwachung und Alarmierung für bereitgestellte Modelle
Ein AIOps-Team ist für die Wartung von Dutzenden von maschinellen Lernmodellen in der Produktion verantwortlich. Sie verwenden eine KI-Middleware-Plattform, um eine einheitliche Ansicht aller Modelle zu erhalten. Das Dashboard der Middleware zeigt Echtzeit-Metriken für jedes Modell, einschließlich Anforderungslatenz, Fehlerraten und CPU/GPU-Auslastung. Das Team richtet automatisierte Alarme ein, die ausgelöst werden, wenn die Latenz eines Modells einen bestimmten Schwellenwert überschreitet oder wenn seine Vorhersagegenauigkeit nachlässt. Dies ermöglicht es ihnen, Probleme proaktiv zu identifizieren und zu beheben, bevor sie Endbenutzer beeinträchtigen, und gewährleistet eine hohe Servicezuverlässigkeit.
Ermöglichung von A/B-Tests für verschiedene Modellversionen
Ein Data-Science-Team hat eine neue Version eines Kundenabwanderungs-Vorhersagemodells entwickelt und möchte dessen Leistung mit der aktuellen Version vergleichen. Mithilfe von KI-Middleware konfigurieren sie eine Traffic-Splitting-Regel. Die Middleware leitet 90 % der eingehenden Anfragen an das stabile, bestehende Modell (A) und die restlichen 10 % an das neue Herausforderermodell (B). Sie protokolliert die Vorhersagen und Ergebnisse für beide Versionen getrennt. Nach einer Woche kann das Team die Protokolle analysieren, um endgültig festzustellen, ob das neue Modell eine messbare Verbesserung bietet, was datengesteuerte Entscheidungen über Modellaktualisierungen ermöglicht.