
David AI
David AI bietet hochwertige, forschungstaugliche Audiodatensätze für das Training fortschrittlicher Sprach- und Konversations-KI-Modelle. Es bietet vielfältige, umfangreiche Datensätze, …
David AI bietet hochwertige, forschungstaugliche Audiodatensätze für das Training fortschrittlicher Sprach- und Konversations-KI-Modelle. Es bietet vielfältige, umfangreiche Datensätze, einschließlich mehrsprachiger Konversationen, Audio mit mehreren Sprechern und Expertendialogen, mit Optionen zur Erstellung benutzerdefinierter Datensätze, um neue KI-Fähigkeiten zu erschließen.
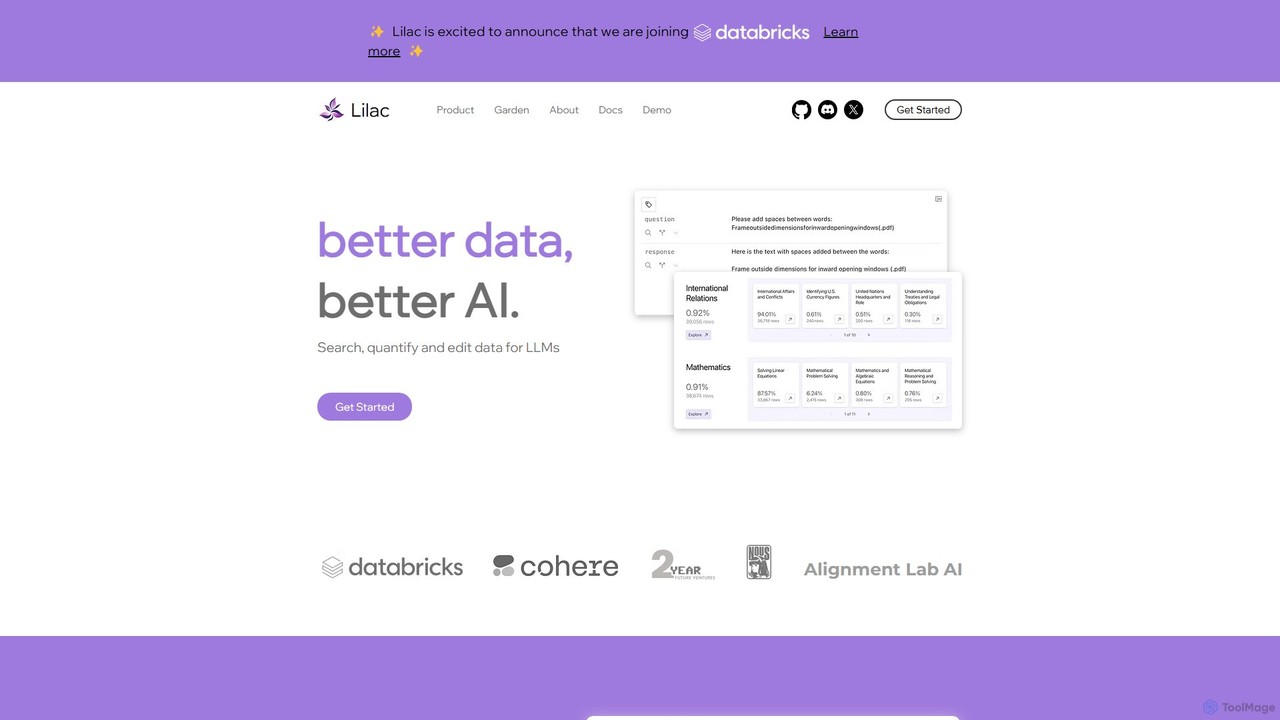
Lilac
Lilac ist ein Open-Source-Tool für Datenwissenschaftler und ML-Ingenieure zum Erkunden, Bereinigen und Verbessern von Datensätzen für große Sprachmodelle …
Lilac ist ein Open-Source-Tool für Datenwissenschaftler und ML-Ingenieure zum Erkunden, Bereinigen und Verbessern von Datensätzen für große Sprachmodelle (LLMs). Es bietet leistungsstarke semantische Suche, Daten-Clustering und Qualitätsanalyse, um bessere KI zu entwickeln.
Über Modelltraining
Modelltraining-Tools sind spezialisierte KI-Infrastrukturkomponenten, die Umgebungen und Ressourcen für den Aufbau, die Verfeinerung und die Optimierung von Machine-Learning-Modellen bereitstellen. Diese Plattformen ermöglichen es Datenwissenschaftlern und Entwicklern, Algorithmen iterativ mit großen Datensätzen zu trainieren und Rohdaten und Code in leistungsstarke, einsetzbare KI-Lösungen umzuwandeln. Sie sind entscheidend für die Erzielung der gewünschten Genauigkeit und Effizienz, die für reale KI-Anwendungen erforderlich sind.
Kernfunktionen
- Datenvorverarbeitung und -erweiterung: Tools zum Bereinigen, Transformieren und Erweitern von Datensätzen zur Verbesserung der Modellrobustheit.
- Algorithmusauswahl und -anpassung: Unterstützung für verschiedene Machine-Learning-Algorithmen und Frameworks, die eine maßgeschneiderte Modellentwicklung ermöglichen.
- Hyperparameter-Optimierung: Automatisierte oder geführte Optimierung von Modellparametern zur Maximierung der Leistung.
- Verteiltes Training: Möglichkeit, das Training über mehrere GPUs oder Maschinen zu skalieren, um große Datensätze schneller zu verarbeiten.
- Modellbewertung und -validierung: Metriken und Tools zur Bewertung der Modellgenauigkeit, -verzerrung und -generalisierungsfähigkeiten.
Anwendungsszenarien
Modelltraining-Tools sind für Organisationen, die kundenspezifische KI-Lösungen entwickeln, unverzichtbar. Datenwissenschaftlerteams nutzen sie, um prädiktive Analysemodelle für Finanzprognosen, Gesundheitsdiagnosen und Kundenverhaltensanalysen zu erstellen. KI-Forscher nutzen diese Plattformen, um mit neuartigen neuronalen Netzwerkarchitekturen zu experimentieren und den Stand der Technik im maschinellen Lernen voranzutreiben.
Auswahlkriterien
Bei der Auswahl einer Modelltrainingsplattform sollten Sie deren Skalierbarkeit zur Bewältigung Ihres Datenvolumens und Ihrer Rechenanforderungen, die Unterstützung Ihrer bevorzugten KI-Frameworks (z. B. TensorFlow, PyTorch) und die Integrationsmöglichkeiten mit anderen MLOps-Tools berücksichtigen. Bewerten Sie die Kosteneffizienz, die Datensicherheitsfunktionen und den Grad der Automatisierung für Aufgaben wie Hyperparameter-Optimierung und Experimentverfolgung.
ModelltrainingAnwendungsfälle
Entwicklung kundenspezifischer Betrugserkennungsmodelle
Datenwissenschaftler von Finanzinstituten nutzen Modelltrainingsplattformen, um KI-Modelle zu entwickeln und zu verfeinern, die betrügerische Transaktionen identifizieren können. Durch die Eingabe historischer Transaktionsdaten, einschließlich legitimer und betrügerischer Fälle, in diese Plattformen können sie Modelle iterativ trainieren, um komplexe Muster zu erkennen, die auf Betrug hindeuten. Dieser Prozess umfasst die Auswahl geeigneter Algorithmen, die Optimierung von Hyperparametern und die Bewertung der Modellleistung anhand neuer Daten, was letztendlich zu einem robusten System führt, das verdächtige Aktivitäten in Echtzeit kennzeichnen und finanzielle Verluste erheblich reduzieren kann.
Optimierung von Computer-Vision-Modellen für die Fertigung
Ingenieure in der Fertigung nutzen Modelltraining-Tools, um Computer-Vision-Modelle für die Qualitätskontrolle und Fehlererkennung zu optimieren. Durch das Training von Modellen auf großen Datensätzen von Produktbildern, einschließlich fehlerfreier und defekter Artikel, können sie die KI feinabstimmen, um Anomalien an Produktionslinien genau zu identifizieren. Dies führt zu automatisierten Inspektionssystemen, die manuelle Fehler reduzieren, den Durchsatz erhöhen und eine gleichbleibende Produktqualität gewährleisten, wodurch erhebliche Betriebskosten eingespart und die Kundenzufriedenheit verbessert werden.
Training von NLP-Modellen für Kundenservice-Chatbots
KI-Entwickler trainieren Natural Language Processing (NLP)-Modelle mithilfe spezialisierter Plattformen, um intelligente Kundenservice-Chatbots zu betreiben. Indem sie die Modelle mit großen Mengen an Kundenanfragen, Gesprächsprotokollen und Wissensdatenbankartikeln füttern, bringen sie der KI bei, die Benutzerabsicht zu verstehen, Schlüsselinformationen zu extrahieren und relevante Antworten zu generieren. Dieser iterative Trainingsprozess verbessert die Fähigkeit des Chatbots, vielfältige Anfragen zu bearbeiten, die Antwortzeiten zu verkürzen und die allgemeine Kundenzufriedenheit zu erhöhen, wodurch menschliche Agenten für komplexere Probleme entlastet werden.
Personalisierung von Content-Empfehlungssystemen
Medienunternehmen und E-Commerce-Plattformen nutzen Modelltraining-Tools, um Empfehlungssysteme zu entwickeln und kontinuierlich zu verfeinern, die Inhalte für Benutzer personalisieren. Datenwissenschaftler trainieren kollaborative Filter- oder Deep-Learning-Modelle anhand von Benutzerinteraktionsdaten (z. B. Ansichten, Käufe, Bewertungen), um Präferenzen vorherzusagen. Dies führt zu hochpräzisen Empfehlungen für Filme, Produkte oder Artikel, wodurch die Benutzerbindung, die Konversionsraten und der Gesamtumsatz erheblich gesteigert werden, indem relevante Inhalte präsentiert werden, die auf individuelle Geschmäcker zugeschnitten sind.
Verbesserung der Genauigkeit der medizinischen Bilddiagnose
Gesundheitsforscher und medizinische KI-Entwickler nutzen Modelltrainingsplattformen, um die Genauigkeit diagnostischer KI-Modelle für die medizinische Bildgebung zu verbessern. Durch das Training von Deep-Learning-Modellen auf großen, annotierten Datensätzen von Röntgenbildern, MRTs und CT-Scans ermöglichen sie der KI, subtile Anomalien zu erkennen, die auf Krankheiten wie Krebs oder Lungenentzündung hindeuten. Dieser rigorose Trainingsprozess hilft bei der Entwicklung von KI-Assistenten, die Radiologen bei der schnelleren und genaueren Diagnose unterstützen können, wodurch potenziell Leben gerettet und Patientenergebnisse verbessert werden.
Entwicklung von Modellen für die vorausschauende Wartung
Industrieingenieure und Datenwissenschaftler in den Bereichen Fertigung und Energie nutzen Modelltraining-Tools, um Modelle für die vorausschauende Wartung zu entwickeln. Durch das Training von KI auf Sensordaten von Maschinen, historischen Fehlerprotokollen und Betriebsparametern können sie Geräteausfälle vorhersagen, bevor sie auftreten. Dies ermöglicht eine proaktive Wartungsplanung, reduziert kostspielige Ausfallzeiten, verlängert die Lebensdauer von Anlagen und optimiert die Betriebseffizienz, was zu erheblichen Kosteneinsparungen und verbesserter Sicherheit in allen industriellen Betrieben führt.