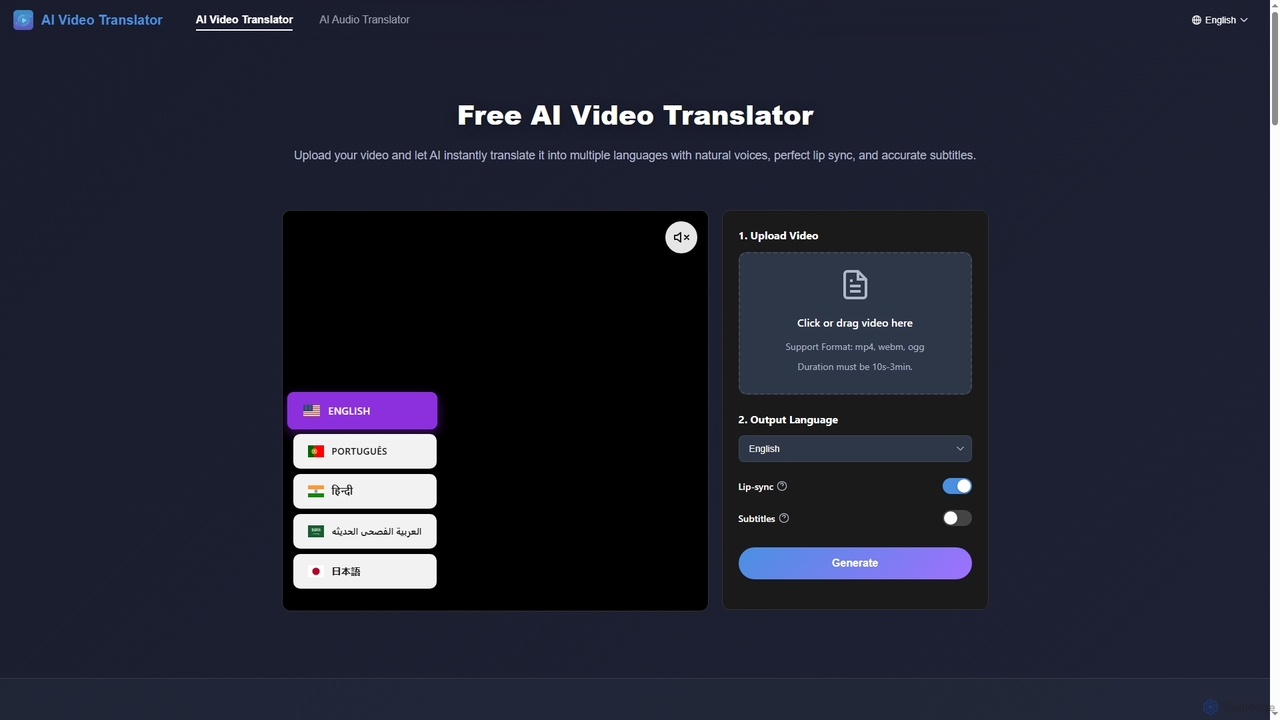
AIVideoTranslator
AIVideoTranslator ist ein leistungsstarkes KI-Tool, das Videos und Audios sofort in mehrere Sprachen übersetzt, mit natürlichen Stimmen, perfekter …
AIVideoTranslator ist ein leistungsstarkes KI-Tool, das Videos und Audios sofort in mehrere Sprachen übersetzt, mit natürlichen Stimmen, perfekter Lippensynchronisation und präzisen Untertiteln. Es hilft Content-Erstellern, Unternehmen und Pädagogen, mühelos ein globales Publikum zu erreichen, bietet schnelle Verarbeitung und erweiterte Stimm-Anpassung, ohne dass eine Anmeldung für die Videoübersetzung erforderlich ist.
Über Sprachsynthese
Sprachsynthese-Tools sind eine Klasse von KI-Anwendungen, die geschriebenen Text in natürlich klingende menschliche Sprache umwandeln, oft als Text-to-Speech (TTS) bezeichnet. Durch den Einsatz von Deep Learning und neuronalen Netzen können diese Tools Audio mit realistischer Intonation, Emotion und Tempo erzeugen, was traditionelle Roboterstimmen bei weitem übertrifft. Sie werden hauptsächlich zur Erstellung von Audioinhalten in großem Umfang verwendet, wie z. B. für Voice-over, Podcasts und Barrierefreiheitsfunktionen. Fortgeschrittene Plattformen bieten sogar das Klonen von Stimmen an, sodass Benutzer aus einem kurzen Audio-Sample eine digitale Nachbildung einer bestimmten Stimme erstellen können.
Kernfunktionen
- Hochwertige Stimmen: Erzeugung klarer, menschenähnlicher Sprache in verschiedenen Stilen, Geschlechtern und Altersgruppen.
- Stimmenklonung & Anpassung: Fähigkeit, eine digitale Nachbildung einer bestimmten Stimme zu erstellen oder Parameter wie Tonhöhe, Geschwindigkeit und Pausen fein abzustimmen.
- Mehrsprachige & Akzent-Unterstützung: Eine umfangreiche Bibliothek von Sprachen und regionalen Akzenten, um ein globales Publikum anzusprechen.
- Emotions- & Stilsteuerung: Optionen, um Sprache mit Emotionen (z. B. fröhlich, traurig, wütend) oder spezifischen Stilen (z. B. Nachrichtensprecher, Konversation) zu versehen.
- API-Zugang: Ermöglicht die programmatische Integration der Spracherzeugung in Anwendungen, Websites und Dienste.
Anwendungsszenarien
Diese Tools werden häufig von Content-Erstellern für YouTube-Videos und Podcasts, von Lehrdesignern für E-Learning-Module und von Autoren für die Hörbuchproduktion verwendet. Im Geschäftsbereich werden sie in automatisierten Kundenservice-Systemen (IVR), Unternehmensschulungsvideos und bei der Erstellung lokalisierter Marketinginhalte eingesetzt. Entwickler nutzen sie auch zur Erstellung von Anwendungen mit Sprachfeedback und Barrierefreiheitsfunktionen.
Auswahlkriterien
Bei der Auswahl eines Sprachsynthese-Tools sollten Sie den Realismus und die Natürlichkeit der angebotenen Stimmen bewerten. Berücksichtigen Sie die Breite der Stimmen- und Sprachbibliothek sowie die Tiefe der verfügbaren Anpassungsoptionen (z. B. SSML-Unterstützung). Für Entwickler sind die Qualität der API-Dokumentation und die einfache Integration entscheidend. Schließlich bewerten Sie das Preismodell – ob abonnementbasiert, pro Zeichen oder gestaffelt – um sicherzustellen, dass es Ihrem Nutzungsvolumen entspricht.
SprachsyntheseAnwendungsfälle
Erstellung von Voice-overs für Videos und Podcasts
Content-Ersteller wie YouTuber und Podcaster benötigen oft eine konsistente und hochwertige Erzählung. Anstatt ihre eigene Stimme aufzunehmen oder teure Synchronsprecher zu engagieren, verwenden sie KI-Sprachsynthese-Tools. Indem sie einfach ihr Skript in das Tool einfügen, können sie in wenigen Minuten ein professionell klingendes Voice-over erstellen. Sie können eine Stimme auswählen, die zum Ton ihrer Marke passt, das Tempo für dramatische Effekte anpassen und eine einwandfreie Aussprache sicherstellen, was die Produktionszeit erheblich verkürzt und die Audiokonsistenz über alle ihre Inhalte hinweg aufrechterhält.
Entwicklung von E-Learning- und Schulungsmodulen
Lehrdesigner haben die Aufgabe, ansprechende und zugängliche Bildungsinhalte zu erstellen. Die KI-Sprachsynthese ermöglicht es ihnen, Kursmaterialien schnell in ein Audioformat umzuwandeln. Dies ist besonders nützlich für die Erstellung mehrsprachiger Schulungsprogramme für globale Unternehmen. Ein Designer kann die Erzählung für ein Modul auf Englisch erstellen und dann sofort dieselbe Erzählung auf Spanisch, Deutsch und Japanisch mit demselben Tool produzieren. Dies spart nicht nur ein erhebliches Budget für Sprecher, sondern gewährleistet auch eine einheitliche Lernerfahrung für alle Mitarbeiter, unabhängig von ihrem Standort.
Erstellung von Hörbüchern aus digitalem Text
Autoren und Verleger können ihre E-Books und Manuskripte in Hörbücher umwandeln, ohne die hohen Kosten und den langwierigen Prozess der Studioaufnahme. Mit einem Sprachsynthese-Tool können sie ihren gesamten Text hochladen und eine Erzählerstimme auswählen, die zum Genre des Buches passt. Fortgeschrittene Tools ermöglichen die Anpassung des Tons für verschiedene Charaktere oder Kapitel. Das Ergebnis ist ein komplettes Hörbuch, das in einem Bruchteil der Zeit und Kosten produziert wird, was Audioinhalte für unabhängige Autoren und kleine Verlage zugänglicher macht und ihre Reichweite auf dem wachsenden Markt der Hörbuchhörer erweitert.
Prototyping von IVR- und Sprachassistenten-Antworten
Entwickler und UX-Designer, die konversationelle KI-Systeme wie IVR für den Kundensupport oder Sprachassistenten erstellen, müssen Dialogflüsse mit realistischen Stimmen testen. Anstatt temporäre Sprachzeilen aufzunehmen, verwenden sie eine Sprachsynthese-API. Dies ermöglicht es ihnen, schnell Prototypen zu erstellen und Skripte zu iterieren. Sie können sofort Audio für neue Dialogoptionen generieren, testen, wie sich verschiedene Stimmen auf die Benutzererfahrung auswirken, und interaktive Prototypen mit Stakeholdern teilen, um Feedback zu erhalten, bevor sie sich für endgültige Sprecher oder Aufnahmesitzungen entscheiden.
Erstellung barrierefreier Inhalte für sehbehinderte Benutzer
Organisationen und Bildungseinrichtungen nutzen die Sprachsynthese, um ihre digitalen Inhalte wie Artikel, Berichte und Websites für Menschen mit Sehbehinderungen zugänglich zu machen. Durch die Integration einer TTS-Funktion können Benutzer den Inhalt anhören, anstatt ihn zu lesen. Dies geht über einfache Bildschirmleser hinaus, indem es ein natürlicheres und ansprechenderes Hörerlebnis bietet. Die Verwendung hochwertiger KI-Stimmen verbessert das Verständnis und reduziert die Ermüdung beim Zuhören, wodurch sichergestellt wird, dass wichtige Informationen einem breiteren Publikum zugänglich sind und Barrierefreiheitsstandards wie WCAG eingehalten werden.
Personalisiertes Stimmenklonen für die Markenidentität
Ein Unternehmen oder eine öffentliche Person kann eine einzigartige, wiedererkennbare KI-Stimme erstellen, die in all ihren Audiokommunikationen verwendet wird. Durch die Bereitstellung einiger Minuten hochwertiger Audioaufnahmen einer bestimmten Person (mit deren Zustimmung) kann ein Sprachsynthese-Tool einen Klon erstellen. Diese geklonte Stimme kann dann zur Erzählung von Marketingvideos, für Unternehmensankündigungen oder zur Steuerung eines gebrandeten virtuellen Assistenten verwendet werden. Dies schafft eine starke, konsistente Markenidentität und eine persönlichere Verbindung zum Publikum, ohne dass der ursprüngliche Sprecher für jede neue Aufnahme verfügbar sein muss.