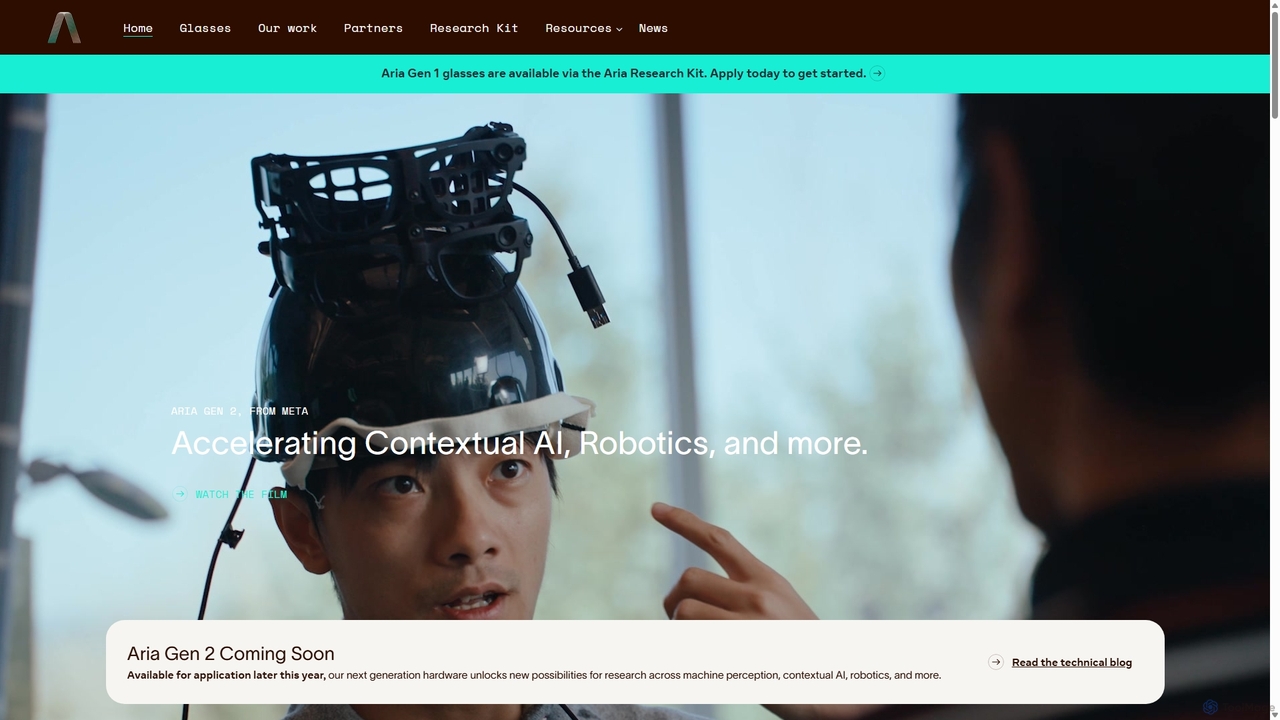
Project Aria
Project Aria ist eine Forschungsinitiative von Meta, die die Entwicklung von kontextbezogener KI, Augmented Reality (AR) und Robotik …
Project Aria ist eine Forschungsinitiative von Meta, die die Entwicklung von kontextbezogener KI, Augmented Reality (AR) und Robotik beschleunigen soll. Es verwendet fortschrittliche Forschungsbrillen wie die Aria Gen 2, um Daten aus der Ich-Perspektive zu erfassen, und bietet Forschern eine umfassende Plattform mit Hardware, Open-Source-Datensätzen und Entwicklungstools, um die Zukunft der maschinellen Wahrnehmung zu gestalten.

Allen Institute for AI (AI2)
Das Allen Institute for AI (AI2) ist ein gemeinnütziges Forschungsinstitut, das sich der Entwicklung bahnbrechender KI für das …
Das Allen Institute for AI (AI2) ist ein gemeinnütziges Forschungsinstitut, das sich der Entwicklung bahnbrechender KI für das Gemeinwohl widmet. Es konzentriert sich auf die Schaffung wirklich quelloffener großer Sprachmodelle wie OLMo, umfassender Datensätze und spezialisierter KI-Tools, um die wissenschaftliche Forschung voranzutreiben und große globale Herausforderungen in Bereichen wie Klimawissenschaft, Naturschutz und Medizin anzugehen.
Über Datensätze
Datensätze sind kuratierte Sammlungen von Daten, die zum Trainieren, Validieren und Testen von Modellen der künstlichen Intelligenz verwendet werden. Diese Sammlungen, die Bilder, Text, Audio oder numerische Daten umfassen können, liefern das grundlegende Wissen für maschinelle Lernalgorithmen, um Muster zu lernen und Vorhersagen zu treffen. Der Zugriff auf hochwertige, relevante Datensätze ist ein entscheidender erster Schritt bei der Entwicklung effektiver KI-Anwendungen, von Computer-Vision-Systemen bis hin zu Prozessoren für natürliche Sprache. Sie dienen als die „Lehrbücher“, aus denen die KI lernt, und beeinflussen direkt die Genauigkeit und Leistung des endgültigen Modells.
Kernfunktionen
- Strukturierte & Beschriftete Daten: Daten sind oft organisiert und mit Beschriftungen (z. B. „Katze“ oder „Hund“ für Bilder) versehen, um überwachtes Lernen zu erleichtern.
- Vielfältige Datentypen: Umfasst eine breite Palette von Formaten wie Bilder, Textdokumente, Audioclips und tabellarische Daten zur Unterstützung verschiedener KI-Aufgaben.
- Datenaufteilung: Typischerweise in Trainings-, Validierungs- und Testsets vorab aufgeteilt, um eine ordnungsgemäße Modellevaluierung zu gewährleisten und Überanpassung zu vermeiden.
- Umfassende Metadaten: Begleitet von detaillierter Dokumentation, die Datenquellen, Erhebungsmethoden und Lizenzinformationen erläutert.
Anwendungsfälle
Datensätze sind in der akademischen Forschung und der kommerziellen KI-Entwicklung von grundlegender Bedeutung. Sie werden von Datenwissenschaftlern zum Trainieren benutzerdefinierter maschineller Lernmodelle, von Forschern zum Benchmarking der Algorithmusleistung anhand etablierter Standards und von Entwicklern zur Feinabstimmung vortrainierter Modelle für spezifische Aufgaben wie Stimmungsanalyse oder Objekterkennung verwendet.
Wie man wählt
Bei der Auswahl eines Datensatzes sollten Sie dessen Relevanz für Ihr spezifisches Problem und seine Gesamtqualität berücksichtigen, einschließlich der Genauigkeit der Beschriftungen und des Fehlens von Verzerrungen. Bewerten Sie auch die Größe des Datensatzes – er sollte groß genug sein, damit Ihr Modell effektiv lernen kann. Überprüfen Sie schließlich die Lizenzbedingungen, um sicherzustellen, dass sie Ihre beabsichtigte Nutzung, ob für kommerzielle oder akademische Zwecke, erlauben.
DatensätzeAnwendungsfälle
Ein benutzerdefiniertes Bilderkennungsmodell trainieren
Ein Computervisions-Ingenieur muss ein Modell erstellen, um spezifische Herstellungsfehler zu identifizieren. Er verwendet einen hochwertigen, beschrifteten Datensatz von Produktbildern, bei dem jedes Bild als „bestanden“ oder „nicht bestanden“ zusammen mit dem Fehlertyp annotiert ist. Durch das Trainieren seines Convolutional Neural Network (CNN) mit diesem Datensatz lernt das Modell, zwischen fehlerfreien Produkten und verschiedenen Mängeln zu unterscheiden, was den Qualitätskontrollprozess automatisiert und die Erkennungsgenauigkeit erhöht.
Ein Sprachmodell für den Kundensupport feinabstimmen
Ein Startup möchte einen spezialisierten Chatbot für seine Branche erstellen. Ein Spezialist für maschinelles Lernen nimmt ein großes, vortrainiertes Sprachmodell und stimmt es mithilfe eines kuratierten Datensatzes aus branchenspezifischen Kundenanfragen und den entsprechenden Expertenantworten fein ab. Dieser Prozess passt das allgemeine Modell an, um Nischenterminologie zu verstehen und relevante, genaue Antworten zu liefern, was die Kundensupporterfahrung erheblich verbessert.
Benchmarking eines neuen Empfehlungsalgorithmus
Ein Data-Science-Team hat einen neuen Algorithmus für eine Filmempfehlungs-Engine entwickelt. Um seine Wirksamkeit zu beweisen, testen sie ihn mit einem öffentlichen, branchenüblichen Datensatz wie MovieLens. Sie vergleichen die Vorhersagegenauigkeit ihres Algorithmus (z. B. wie gut er Benutzerbewertungen vorhersagt) mit etablierten Benchmarks. Dies ermöglicht eine objektive Leistungsbewertung und Validierung vor der Bereitstellung des neuen Systems.
Ein sprachgesteuertes Smart-Home-Gerät entwickeln
Ein IoT-Entwickler erstellt ein Gerät, das auf Sprachbefehle reagiert. Er nutzt einen großen Audiodatensatz, der Tausende von Stunden gesprochener Befehle von diversen Sprechern mit unterschiedlichen Akzenten und in verschiedenen akustischen Umgebungen enthält. Dieser Datensatz wird verwendet, um ein Speech-to-Text-Modell zu trainieren, das sicherstellt, dass das Gerät Benutzerbefehle wie „Licht einschalten“ oder „Timer stellen“ unter realen Bedingungen zuverlässig verstehen kann.
Einen KI-Assistenten für die medizinische Diagnose erstellen
Eine medizinische Forschungseinrichtung zielt darauf ab, ein KI-Tool zu entwickeln, das Radiologen bei der Erkennung von Tumoren in MRT-Scans unterstützt. Sie verwenden einen spezialisierten, anonymisierten Datensatz medizinischer Bilder, bei dem jeder Scan von erfahrenen Radiologen beschriftet wird. Das Trainieren eines Modells mit diesem Datensatz hilft dabei, ein System zu schaffen, das potenzielle Problembereiche hervorheben kann, als Zweitmeinung dient und potenziell die Diagnosegeschwindigkeit und -genauigkeit verbessert.
Stimmungsanalyse für die Marktforschung durchführen
Ein Marketinganalyst möchte die öffentliche Meinung zu einer neuen Produkteinführung einschätzen. Er verwendet einen Datensatz von Social-Media-Beiträgen und Produktbewertungen, die jeweils mit einer Stimmung (positiv, negativ, neutral) gekennzeichnet sind. Durch das Trainieren eines Modells zur Verarbeitung natürlicher Sprache (NLP) mit diesen Daten kann er Tausende neuer Kommentare automatisch analysieren, Echtzeit-Einblicke in die Kundenzufriedenheit liefern und Verbesserungsbereiche identifizieren.