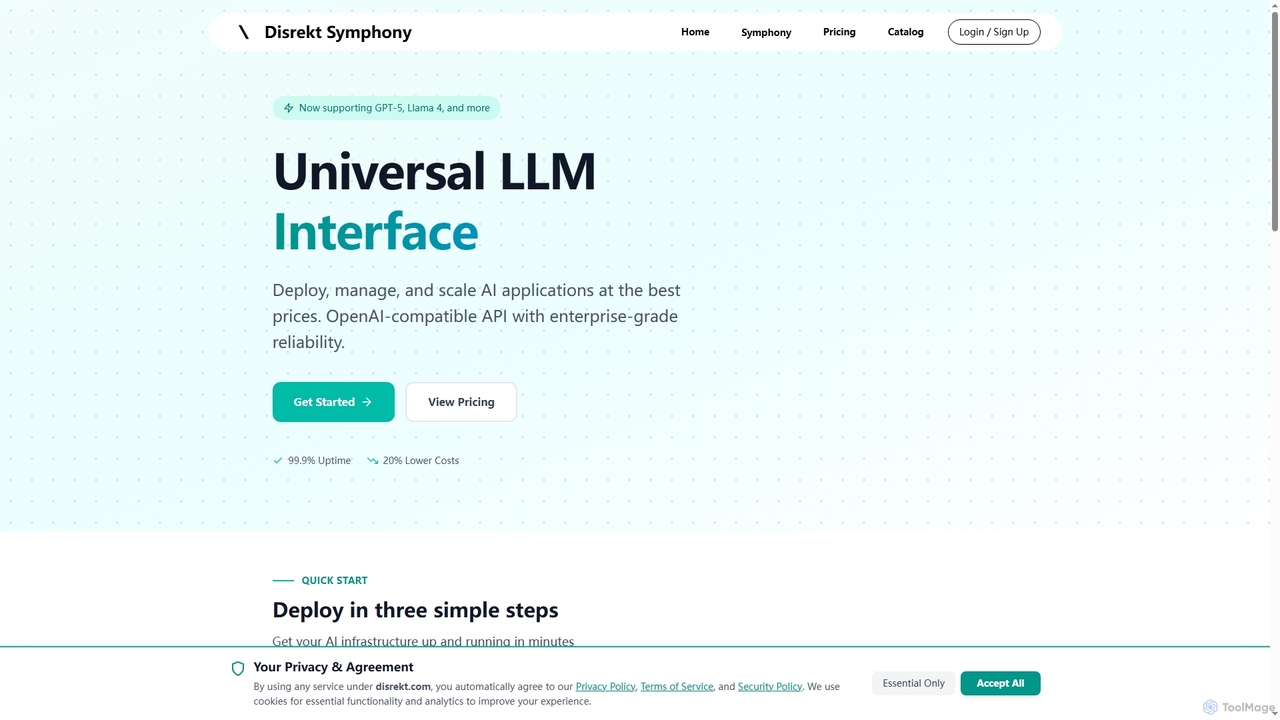
Symphony
Symphony ist eine universelle LLM-Schnittstelle, die eine OpenAI-kompatible API zur Bereitstellung, Verwaltung und Skalierung von KI-Anwendungen bietet. Sie …
Symphony ist eine universelle LLM-Schnittstelle, die eine OpenAI-kompatible API zur Bereitstellung, Verwaltung und Skalierung von KI-Anwendungen bietet. Sie zeichnet sich durch unternehmensgerechte Zuverlässigkeit, bis zu 20 % niedrigere Kosten und die Unterstützung von über 100 wichtigen KI-Modellen wie GPT-5 und Llama 4 aus, was sie zur idealen Lösung für Entwickler und Unternehmen macht, die eine effiziente und robuste KI-Infrastruktur suchen.
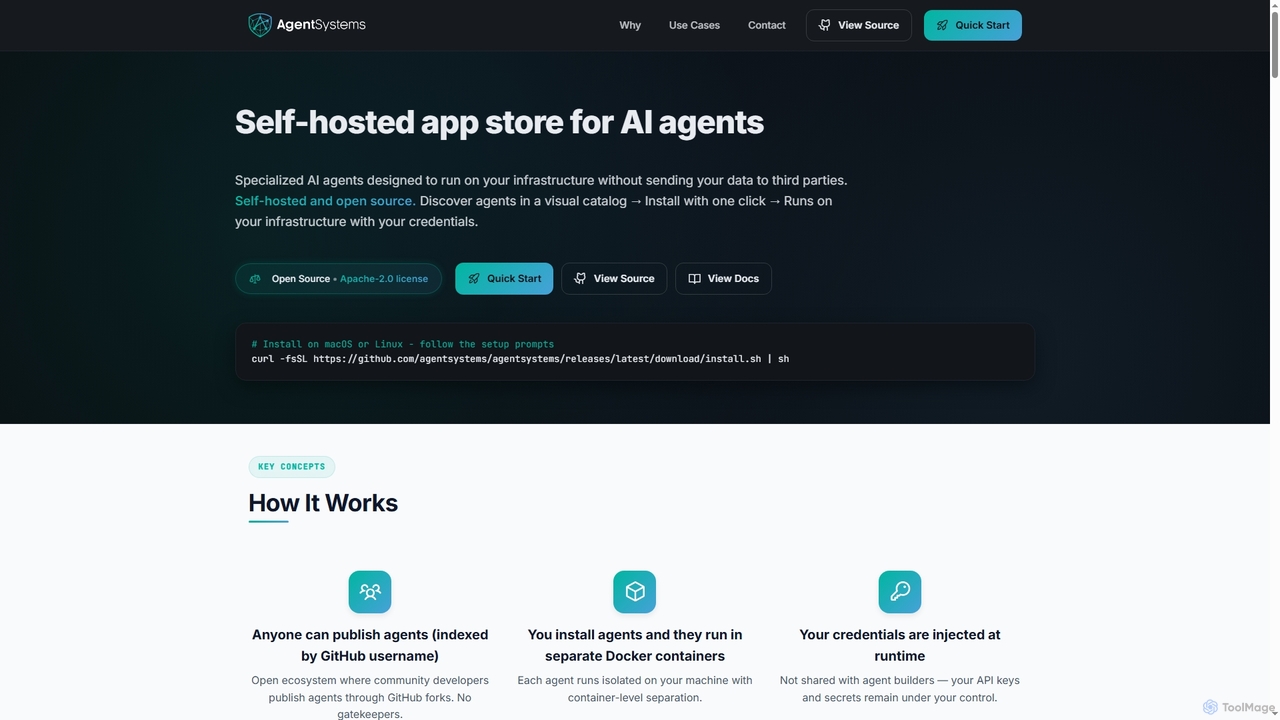
AgentSystems
Eine Open-Source-, selbst gehostete Plattform zum Entdecken, Bereitstellen und Verwalten spezialisierter KI-Agenten auf Ihrer eigenen Infrastruktur, die vollständige …
Eine Open-Source-, selbst gehostete Plattform zum Entdecken, Bereitstellen und Verwalten spezialisierter KI-Agenten auf Ihrer eigenen Infrastruktur, die vollständige Datenprivatsphäre und -kontrolle gewährleistet.
Über KI-Infrastruktur
KI-Infrastruktur bietet die grundlegenden Plattformen und Dienste zum Erstellen, Trainieren, Bereitstellen und Verwalten von Machine-Learning-Modellen in großem Maßstab. Diese Tools abstrahieren die Komplexität der zugrunde liegenden Hardware und Software und bieten verwaltete Umgebungen, die für den gesamten KI-Entwicklungslebenszyklus optimiert sind. Sie ermöglichen es Entwicklern und Datenwissenschaftlern, sich auf die Modellerstellung anstatt auf die Verwaltung komplexer Systeme zu konzentrieren und beschleunigen so den Weg vom Experiment zur Produktion. Diese spezialisierte Infrastruktur ist entscheidend für die Verarbeitung großer Datensätze, intensiver Berechnungen und kontinuierlicher Modellüberwachung.
Kernfunktionen
- Verwaltete Rechenressourcen: Bietet On-Demand-Zugriff auf optimierte Hardware wie GPUs und TPUs für Training und Inferenz ohne manuelle Einrichtung.
- MLOps & Lebenszyklusmanagement: Bietet Tools für Experiment-Tracking, Modellversionierung, automatisiertes Neutraining und CI/CD-Pipelines für maschinelles Lernen.
- Skalierbare Modellbereitstellung: Ermöglicht die einfache Bereitstellung trainierter Modelle als skalierbare API-Endpunkte, serverlose Funktionen oder Batch-Verarbeitungsaufträge.
- Daten- & Feature-Management: Umfasst Lösungen für Datenspeicherung, Versionierung, Kennzeichnung und die Erstellung zentraler Feature-Stores für die Modellkonsistenz.
- Integrierte Entwicklungsumgebungen: Bietet vorkonfigurierte Notebooks und Umgebungen mit beliebten KI-Frameworks wie TensorFlow und PyTorch.
Anwendungsfälle
KI-Infrastruktur ist unerlässlich für Technologieunternehmen, KI-Startups und Data-Science-Teams in Unternehmen, die maßgeschneiderte KI-Lösungen entwickeln. Sie wird zur Entwicklung großer Empfehlungssysteme, zur Bereitstellung von Computer-Vision-Modellen für die industrielle Automatisierung und zur Verwaltung des Lebenszyklus von Betrugserkennungsmodellen im Finanzwesen eingesetzt. Forschungseinrichtungen nutzen sie ebenfalls, um Experimente durch den On-Demand-Zugriff auf leistungsstarke Rechenressourcen zu beschleunigen.
Auswahlkriterien
Bei der Auswahl eines KI-Infrastruktur-Tools bewerten Sie dessen Skalierbarkeit und Leistung für Ihre erwartete Arbeitslast. Berücksichtigen Sie die Unterstützung für Ihre bevorzugten Machine-Learning-Frameworks und den Grad der MLOps-Automatisierung. Wägen Sie das Gleichgewicht zwischen Benutzerfreundlichkeit (vollständig verwaltete Plattformen) und Flexibilität (zusammensetzbare Komponenten) ab. Analysieren Sie schließlich das Preismodell (z. B. Pay-per-Use, Abonnement) und die Integrationsfähigkeiten mit Ihrem bestehenden Daten-Stack.
KI-InfrastrukturAnwendungsfälle
Bereitstellung eines benutzerdefinierten LLM für den Kundenservice
Ein SaaS-Unternehmen möchte einen Support-Chatbot erstellen, der von einem feinabgestimmten Large Language Model (LLM) angetrieben wird. Ihr MLOps-Team verwendet eine KI-Infrastrukturplattform, um den gesamten Prozess zu verwalten. Zuerst nutzen sie die Datenmanagement-Tools der Plattform, um ihre proprietären Support-Tickets vorzubereiten und zu versionieren. Dann setzen sie On-Demand-GPU-Instanzen ein, um ein Open-Source-Modell feinabzustimmen. Nachdem sie Experimente verfolgt haben, um die leistungsstärkste Version zu finden, stellen sie das Modell als hochverfügbaren, automatisch skalierenden API-Endpunkt bereit. Dies ermöglicht ihrer Anwendung, Tausende von gleichzeitigen Benutzeranfragen zu bearbeiten, ohne dass das Team Server verwalten muss.
Aufbau eines skalierbaren Bilderkennungsdienstes
Ein Startup entwickelt eine mobile App, die Pflanzenarten anhand von Fotos identifiziert. Ihre Datenwissenschaftler verwenden eine KI-Infrastrukturplattform, um ihr Computer-Vision-Modell zu trainieren. Die integrierte Umgebung der Plattform ermöglicht es ihnen, einfach auf einen großen Datensatz von Pflanzenbildern zuzugreifen und diesen zu verarbeiten, der in der Cloud gespeichert ist. Sie führen Dutzende von Trainingsjobs parallel auf verwalteten GPU-Clustern aus und verwenden die Funktion zur Experimentverfolgung, um Ergebnisse zu vergleichen. Sobald das endgültige Modell fertig ist, wird es als serverlose Funktion bereitgestellt, was die Kosten niedrig hält, da es nur ausgeführt wird, wenn ein Benutzer ein Foto hochlädt, und automatisch skaliert, um virale Verkehrsspitzen zu bewältigen.
Verwaltung des MLOps-Lebenszyklus für eine FinTech-App
Ein Finanztechnologieunternehmen verlässt sich auf ein Machine-Learning-Modell, um betrügerische Transaktionen in Echtzeit zu erkennen. Um die Genauigkeit aufrechtzuerhalten und sich an neue Betrugsmuster anzupassen, muss das Modell häufig neu trainiert werden. Sie verwenden eine KI-Infrastrukturplattform mit starken MLOps-Fähigkeiten. Die Plattform automatisiert den gesamten Lebenszyklus: Sie löst eine Neutrainings-Pipeline aus, wann immer die Modellleistung nachlässt oder neue gekennzeichnete Daten verfügbar sind. Nach dem Training wird das neue Modell automatisch getestet und, wenn es besteht, ohne Ausfallzeiten in die Produktion überführt. Dies stellt sicher, dass ihr Betrugserkennungssystem immer auf dem neuesten Stand und zuverlässig ist und strenge regulatorische Anforderungen erfüllt.
Unterstützung der semantischen Suche mit Vektordatenbanken
Eine E-Commerce-Plattform möchte ihre Produktsuche von der Stichwortsuche auf die semantische Suche umstellen, um die Absicht der Benutzer besser zu verstehen. Ihr Entwicklungsteam wählt einen KI-Infrastrukturanbieter, der einen verwalteten Vektordatenbankdienst anbietet. Sie nutzen diesen Dienst, um Vektoreinbettungen für alle ihre Produktbeschreibungen und Bilder zu speichern. Wenn ein Benutzer nach „warme Jacke zum Wandern“ sucht, wandelt das System die Anfrage in einen Vektor um und verwendet die Datenbank, um die semantisch ähnlichsten Produkte zu finden, anstatt nur Stichwörter abzugleichen. Der verwaltete Dienst kümmert sich um die Skalierung und Indizierung der Vektordatenbank, sodass das Team diese erweiterte Funktion schnell implementieren kann.
Beschleunigung von KI-Forschung und Experimenten
Ein universitäres Forschungslabor arbeitet an einem Durchbruch in der Verarbeitung natürlicher Sprache, der das Training sehr großer Modelle erfordert. Ihnen fehlt die Rechenleistung vor Ort für solche Aufgaben. Durch die Nutzung einer cloudbasierten KI-Infrastrukturplattform können Forscher sofort leistungsstarke Multi-GPU-Server für ihre Experimente bereitstellen, ohne große Kapitalinvestitionen tätigen zu müssen. Die Experiment-Tracking-Tools der Plattform protokollieren automatisch alle Hyperparameter, Codeversionen und Ergebnisse und gewährleisten so die Reproduzierbarkeit. Dies ermöglicht es dem Team, Hunderte von Experimenten durchzuführen, effektiv zusammenzuarbeiten und ihren Forschungszeitplan im Vergleich zur Verwaltung eigener Hardware erheblich zu beschleunigen.
Entwicklung und Hosting einer generativen KI-Anwendung
Ein Indie-Entwickler erstellt ein SaaS-Produkt, das Marketingtexte mit einem generativen KI-Modell erstellt. Er wählt eine KI-Infrastrukturplattform, die die Bereitstellung und das Hosting vereinfacht. Nach dem Training seines Modells lädt er es auf die Plattform hoch und stellt es über eine einfache API zur Verfügung. Die Plattform kümmert sich um die Benutzerauthentifizierung, die Ratenbegrenzung und die Abrechnungsintegration. Sie bietet auch Dashboards zur Überwachung der API-Nutzung, Latenz und Kosten. Dies ermöglicht es dem Entwickler, sein Produkt schnell auf den Markt zu bringen und sich auf die Verbesserung des Modells und der Benutzererfahrung zu konzentrieren, anstatt eine komplexe Backend-Infrastruktur von Grund auf neu zu erstellen und zu warten.