News Image Creator - Python Source Code
Ein Python-Quellcode-Paket für Entwickler und Content-Ersteller zur automatischen Erstellung von Bildern im Nachrichtenstil mit benutzerdefinierten Textüberlagerungen. Es bietet …
Ein Python-Quellcode-Paket für Entwickler und Content-Ersteller zur automatischen Erstellung von Bildern im Nachrichtenstil mit benutzerdefinierten Textüberlagerungen. Es bietet erweiterte Optionen für die Massenerstellung, KI-gestützte Themengenerierung über OpenAI und Social-Media-Automatisierung.
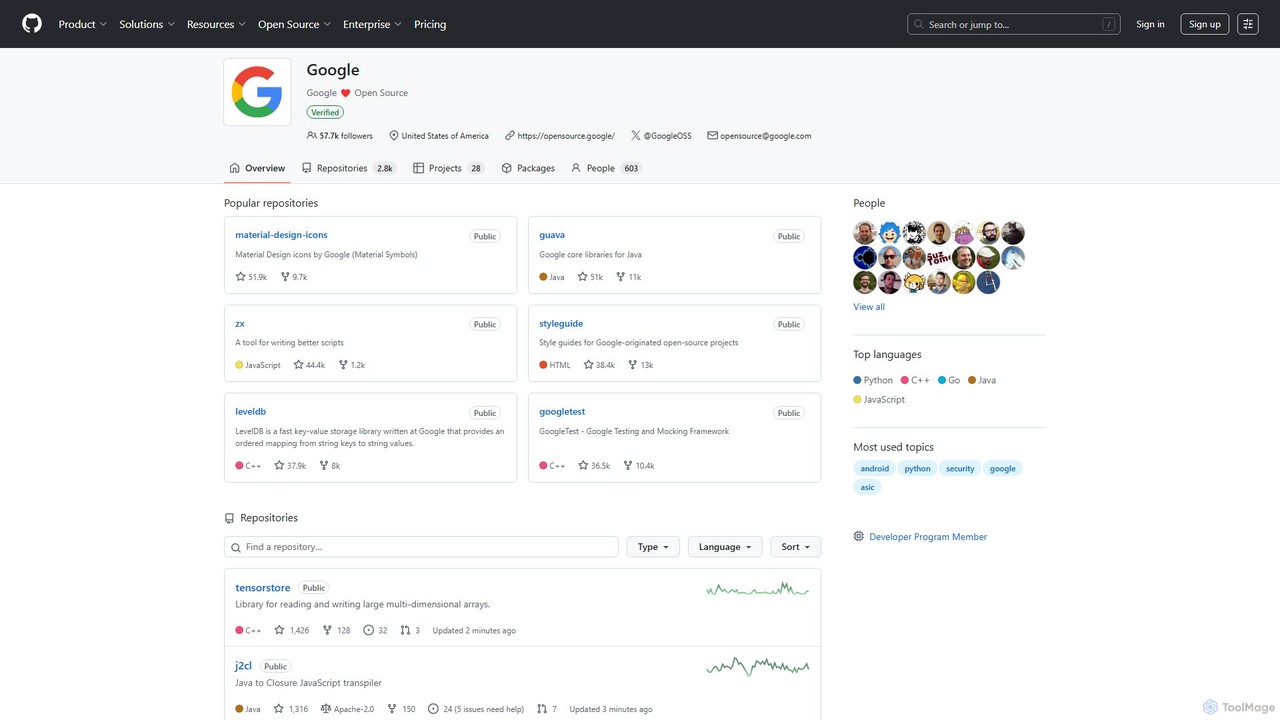
Google · GitHub
Der offizielle Open-Source-Hub von Google auf GitHub. Er beherbergt eine riesige Sammlung von über 2.700 öffentlichen Repositories, darunter …
Der offizielle Open-Source-Hub von Google auf GitHub. Er beherbergt eine riesige Sammlung von über 2.700 öffentlichen Repositories, darunter Bibliotheken, Entwicklerwerkzeuge, Frameworks und Styleguides. Eine entscheidende Ressource für Entwickler, die mit Java, C++, Python, Android, Web-Technologien und mehr arbeiten, und bietet produktionserprobten Code und fördert die Zusammenarbeit in der Community.
Über Code-Bibliotheken
Code-Bibliotheken sind unverzichtbare KI-gestützte Tools, die vorgefertigte Module, Funktionen und Algorithmen für die Entwicklung von Anwendungen der künstlichen Intelligenz bereitstellen. Sie abstrahieren komplexe mathematische und rechnerische Aufgaben und ermöglichen es Entwicklern, anspruchsvolle KI-Funktionen wie maschinelles Lernen, Deep Learning und natürliche Sprachverarbeitung effizienter zu integrieren. Diese Bibliotheken beschleunigen die Entwicklungszyklen erheblich, indem sie standardisierte, optimierte Komponenten für gängige KI-Aufgaben anbieten.
Core Features
- Vorgefertigte Algorithmen: Bietet optimierte Implementierungen von Machine-Learning-Algorithmen (z.B. Klassifikation, Regression, Clustering) und Deep-Learning-Architekturen (z.B. CNNs, RNNs).
- Datenverarbeitungs-Dienstprogramme: Stellt Tools für das Laden, Vorverarbeiten, Transformieren und Erweitern von Daten bereit, die für die Vorbereitung von Datensätzen für KI-Modelle entscheidend sind.
- Modelltraining und -bewertung: Umfasst Funktionen zum Definieren, Trainieren, Validieren und Bewerten von KI-Modellen, oft mit GPU-Beschleunigungsunterstützung.
- Bereitstellungs- und Inferenz-Tools: Erleichtert die Bereitstellung trainierter Modelle in Produktionsumgebungen und optimiert sie für eine effiziente Inferenz.
Anwendungsfälle
Entwickler aus verschiedenen Bereichen nutzen KI-Code-Bibliotheken, um ihre Arbeit zu optimieren. Datenwissenschaftler verwenden sie für schnelles Prototyping und Experimente mit verschiedenen Modellen. KI-Ingenieure integrieren diese Bibliotheken in größere Softwaresysteme, um intelligente Funktionen hinzuzufügen. Forscher nutzen sie, um neuartige KI-Algorithmen effizient zu implementieren und zu testen.
So wählen Sie aus
Bei der Auswahl einer KI-Code-Bibliothek sollten Sie deren Ökosystem und Community-Support berücksichtigen, was auf eine aktive Entwicklung und verfügbare Ressourcen hinweist. Bewerten Sie ihre Leistung und Skalierbarkeit für Ihre spezifischen Daten- und Modellgrößen. Beurteilen Sie ihre Benutzerfreundlichkeit und die Qualität der Dokumentation, insbesondere für neue Teammitglieder. Überprüfen Sie schließlich die Kompatibilität mit Ihrem bestehenden Technologie-Stack und den Hardwareanforderungen.
Code-BibliothekenAnwendungsfälle
Entwicklung benutzerdefinierter Machine-Learning-Modelle
Datenwissenschaftler verwenden Bibliotheken wie TensorFlow oder PyTorch, um neuronale Netze für spezifische Aufgaben wie Bilderkennung oder prädiktive Analysen zu erstellen, zu trainieren und zu optimieren. Dies ermöglicht eine schnelle Iteration und Experimente, ohne mathematische Operationen auf niedriger Ebene von Grund auf neu schreiben zu müssen.
Anwendungen zur Verarbeitung natürlicher Sprache (NLP)
Entwickler setzen Bibliotheken wie Hugging Face Transformers oder NLTK ein, um Funktionen wie Stimmungsanalyse, Textzusammenfassung oder Sprachübersetzung in Chatbots, Inhaltsanalysetools oder virtuellen Assistenten zu implementieren. Diese Bibliotheken bieten vortrainierte Modelle und Tokenizer, was die Entwicklungszeit erheblich verkürzt.
Integration von Computer-Vision-Systemen
Ingenieure nutzen OpenCV oder scikit-image in ihren Anwendungen, um Aufgaben wie Objekterkennung, Gesichtserkennung oder Bildsegmentierung durchzuführen. Dies ermöglicht die Erstellung intelligenter Überwachungssysteme, Augmented-Reality-Erlebnisse oder automatisierte Qualitätskontrolle in der Fertigung.
Datenvorverarbeitung und Feature Engineering
Datenanalysten und Machine-Learning-Ingenieure verwenden Bibliotheken wie Pandas und NumPy, um Rohdaten für das Modelltraining zu bereinigen, zu transformieren und vorzubereiten. Dazu gehören die Behandlung fehlender Werte, die Skalierung von Features und die Erstellung neuer Features, die entscheidende Schritte zur Verbesserung der Modellleistung sind.
Reinforcement Learning für autonome Agenten
Forscher und Entwickler wenden Bibliotheken wie OpenAI Gym oder Stable Baselines an, um intelligente Agenten für komplexe Entscheidungsaufgaben zu entwerfen und zu trainieren, z.B. zur Steuerung von Robotern, zur Optimierung von Spielstrategien oder zur Verwaltung der Ressourcenzuweisung in dynamischen Umgebungen.
Aufbau von Empfehlungssystemen
E-Commerce-Plattformen und Content-Anbieter verwenden Bibliotheken wie Surprise oder LightFM, um personalisierte Empfehlungs-Engines zu entwickeln. Diese Bibliotheken helfen, das Nutzerverhalten und die Artikelmerkmale zu analysieren, um Produkte, Filme oder Artikel vorzuschlagen und so die Nutzerbindung und den Umsatz zu steigern.