Kubiks
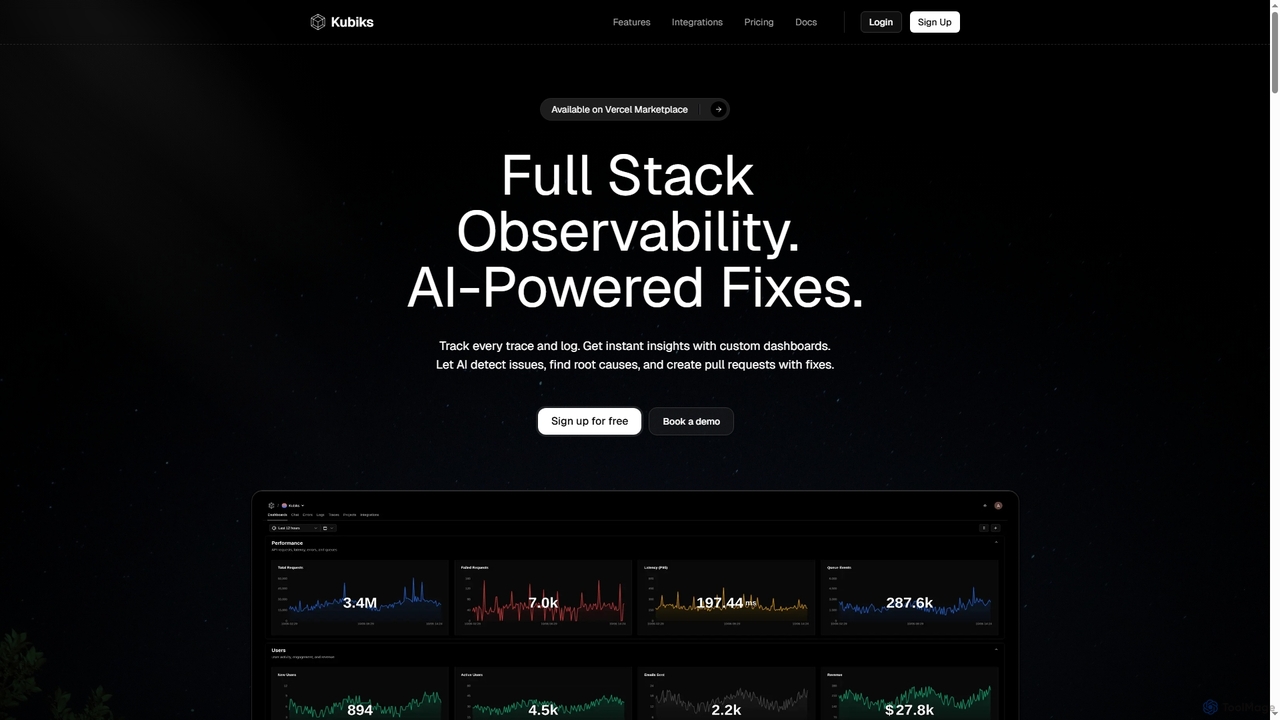
Kubiks ist eine KI-gestützte Full-Stack-Observability-Plattform, die verteiltes Tracing, Logging und benutzerdefinierte Dashboards bietet. Sie erkennt Probleme automatisch, findet …
Kubiks ist eine KI-gestützte Full-Stack-Observability-Plattform, die verteiltes Tracing, Logging und benutzerdefinierte Dashboards bietet. Sie erkennt Probleme automatisch, findet Ursachen und erstellt Pull-Requests mit Korrekturen, um Engineering-Teams dabei zu helfen, schneller zu debuggen und Probleme proaktiv zu lösen.
Über Observierbarkeit
Observierbarkeit ist eine Reihe von KI-gestützten und datengesteuerten Praktiken und Tools, die es Teams ermöglichen, den internen Zustand eines komplexen Systems durch die Untersuchung seiner externen Ausgaben – Protokolle, Metriken und Traces – zu verstehen. Diese Tools sind entscheidend, um tiefe Einblicke in das Verhalten, die Leistung und den Zustand von Software zu gewinnen, insbesondere innerhalb moderner verteilter Architekturen, die in der Softwareentwicklung üblich sind. Durch die Bereitstellung umfassender Sichtbarkeit ermöglichen Observierbarkeitslösungen Entwicklern und Betriebsteams, Probleme proaktiv zu identifizieren, Ursachen schnell zu diagnostizieren und die Systemleistung zu optimieren, wodurch robuste und zuverlässige Anwendungen gewährleistet werden.
Kernfunktionen
- Verteiltes Tracing: Verfolgt Anfragen über mehrere Dienste hinweg, um End-to-End-Transaktionsflüsse zu visualisieren und Latenzprobleme zu lokalisieren.
- Protokollaggregation & -analyse: Sammelt, zentralisiert und analysiert große Mengen von Protokolldaten zur Fehlererkennung, Sicherheitsprüfung und Verhaltensanalyse.
- Echtzeit-Metriküberwachung: Erfasst und visualisiert Leistungsindikatoren (CPU, Speicher, Netzwerk, anwendungsspezifische Daten), um den Systemzustand und Trends zu verfolgen.
- Anomalieerkennung: Nutzt KI, um ungewöhnliche Muster in Daten automatisch zu identifizieren und Teams auf potenzielle Probleme aufmerksam zu machen, bevor sie Benutzer beeinträchtigen.
- Alarmierung & Incident Management: Konfigurierbare Alarme basierend auf Schwellenwerten oder Anomalien, integriert in Incident-Response-Workflows.
Anwendungsfälle
Observierbarkeits-Tools sind für Softwareentwicklungs- und Betriebsteams, die komplexe Anwendungen verwalten, unverzichtbar. Sie werden von SREs zur Aufrechterhaltung der Systemverfügbarkeit, von Entwicklern zum Debuggen von Microservices und von Produktmanagern zum Verständnis der Auswirkungen auf die Benutzererfahrung eingesetzt. Diese Tools liefern die notwendigen Daten, um fundierte Entscheidungen über Systemarchitektur, Ressourcenzuweisung und Funktionspriorisierung zu treffen.
Auswahlkriterien
Bei der Auswahl eines Observierbarkeits-Tools sollten Sie dessen Datenerfassungsfähigkeiten (Protokolle, Metriken, Traces), die Integration in Ihren bestehenden Technologie-Stack (Cloud-Anbieter, Programmiersprachen, Datenbanken), die Skalierbarkeit zur Bewältigung wachsender Datenmengen und die Qualität seiner Visualisierungs- und Alarmierungsfunktionen berücksichtigen. Bewerten Sie das Kostenmodell, die Benutzerfreundlichkeit und den Community-Support, um sicherzustellen, dass es den technischen Kenntnissen und dem Budget Ihres Teams entspricht.
ObservierbarkeitAnwendungsfälle
Diagnose von Leistungsengpässen in Microservices
Für Softwareentwickler und SREs sind Observierbarkeits-Tools entscheidend, um Leistungsengpässe in komplexen Microservice-Architekturen zu identifizieren. Durch verteiltes Tracing können Teams den gesamten Anforderungsfluss über Dienste hinweg visualisieren, feststellen, welcher spezifische Dienst oder Datenbankaufruf Verzögerungen verursacht, und schnell in relevante Protokolle und Metriken eintauchen, um die Ursache zu verstehen. Dies reduziert die mittlere Reparaturzeit (MTTR) für kritische Leistungsstörungen drastisch.
Proaktive Fehlererkennung und Alarmierung
DevOps- und Betriebsteams nutzen Observierbarkeitsplattformen, um von einem reaktiven zu einem proaktiven Incident Management überzugehen. Die KI-gestützte Anomalieerkennung überwacht kontinuierlich Systemmetriken und Protokolle auf ungewöhnliche Muster, wie plötzliche Spitzen bei Fehlerraten oder unerwarteten Ressourcenverbrauch. Automatische Alarme werden ausgelöst, wenn Anomalien erkannt werden, sodass Teams potenzielle Probleme beheben können, bevor sie zu Ausfällen eskalieren oder Endbenutzer erheblich beeinträchtigen.
Verständnis der User Journey und Experience
Produktmanager und UX-Designer können Observierbarkeitsdaten nutzen, um Einblicke in die Interaktion der Benutzer mit ihren Anwendungen zu gewinnen. Durch die Korrelation von verteilten Traces mit Frontend-Leistungsmetriken und benutzerspezifischen Protokollen können sie Benutzerreisen rekonstruieren, Reibungspunkte identifizieren und den Einfluss der Backend-Leistung auf die Benutzererfahrung verstehen. Diese Daten fließen in Produktverbesserungen und die Priorisierung von Funktionen ein, was zu einer zufriedenstellenderen Benutzererfahrung führt.
Kapazitätsplanung und Ressourcenoptimierung
Infrastruktur- und Cloud-Architekten verlassen sich auf Observierbarkeits-Tools für eine effektive Kapazitätsplanung und Ressourcenoptimierung. Durch die Analyse historischer Trends bei CPU-Auslastung, Speicherverbrauch, Netzwerkverkehr und anwendungsspezifischen Metriken können Teams zukünftige Ressourcenanforderungen genau vorhersagen. Dies verhindert Überprovisionierung (Kostenersparnis) oder Unterprovisionierung (Vermeidung von Leistungsverschlechterung) und gewährleistet ein effizientes und skalierbares Infrastrukturmanagement.
Sicherheitsvorfalluntersuchung und Forensik
Sicherheitsbetriebsteams (SecOps) nutzen Observierbarkeitsplattformen für detaillierte Sicherheitsvorfalluntersuchungen. Zentralisierte Protokollaggregations- und Analysefunktionen ermöglichen es Sicherheitsanalysten, schnell große Mengen von System- und Anwendungsprotokollen nach verdächtigen Aktivitäten, unautorisierten Zugriffsversuchen oder Datenlecks zu durchsuchen. Die Korrelation dieser Protokolle mit Netzwerk-Traces und Systemmetriken bietet eine umfassende Zeitleiste und Kontext für die forensische Analyse, was bei der schnellen Eindämmung und Behebung hilft.
Optimierung der CI/CD-Pipeline-Leistung
Entwicklungs- und Release-Engineering-Teams wenden Observierbarkeitsprinzipien auf ihre CI/CD-Pipelines an. Durch das Sammeln von Metriken und Protokollen von Build-Servern, Testumgebungen und Bereitstellungsprozessen können sie Engpässe, langsame Tests oder fehlgeschlagene Bereitstellungen identifizieren. Diese Sichtbarkeit hilft, Pipeline-Phasen zu optimieren, Build-Zeiten zu reduzieren und eine schnellere, zuverlässigere Softwarebereitstellung zu gewährleisten, was direkt zur Entwicklerproduktivität und einer schnelleren Markteinführung beiträgt.