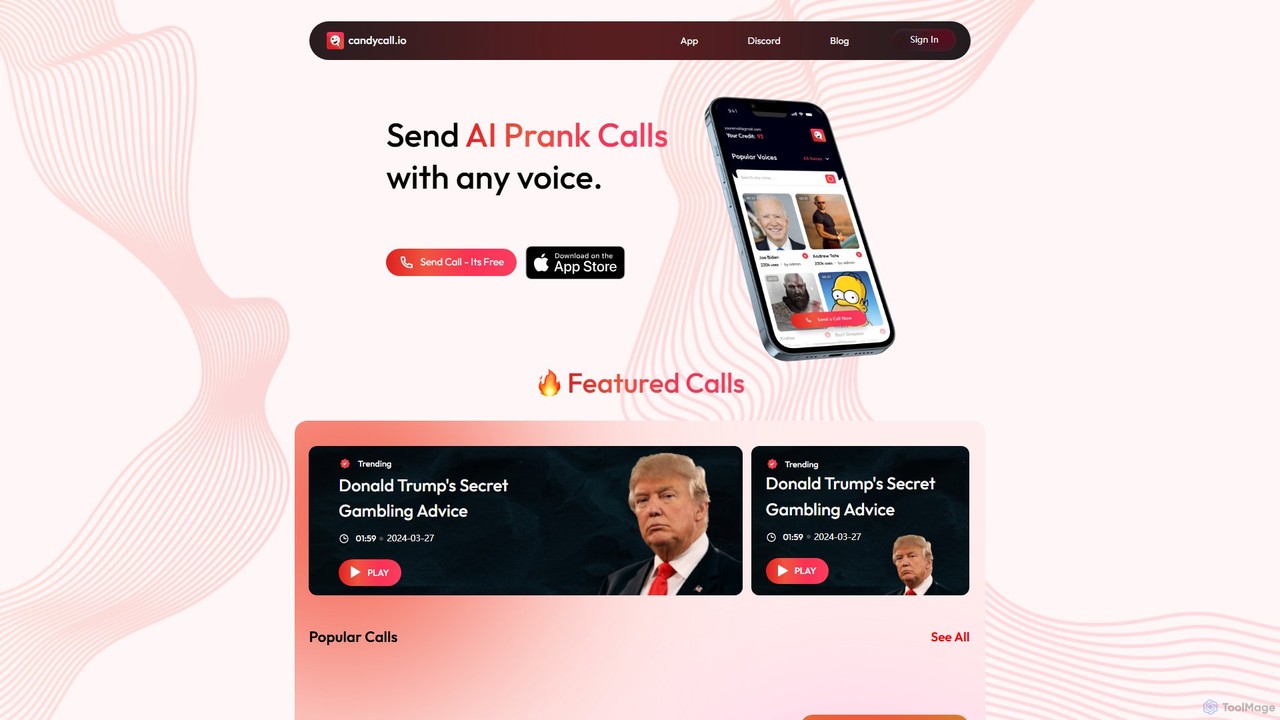
CandyCall
CandyCall ist eine KI-gestützte Unterhaltungsplattform, mit der Sie urkomische Scherzanrufe mit einer Bibliothek von über 300 realistischen Stimmen …
CandyCall ist eine KI-gestützte Unterhaltungsplattform, mit der Sie urkomische Scherzanrufe mit einer Bibliothek von über 300 realistischen Stimmen von Prominenten und Charakteren tätigen können. Personalisieren Sie Nachrichten oder verwenden Sie vorgefertigte Skripte, um Ihre Freunde mit Anrufen von Persönlichkeiten wie Joe Biden, Elon Musk und mehr zu überraschen.
Über Generative Stimme
Generative Sprachwerkzeuge sind KI-gestützte Anwendungen, die hochrealistische, menschenähnliche Sprache aus Text oder anderen Eingaben synthetisieren. Mithilfe fortschrittlicher Deep-Learning-Modelle und neuronaler Netze können diese Tools natürlich klingende Stimmen mit anpassbaren Emotionen, Akzenten und Sprechstilen erzeugen. Sie bieten einen erheblichen Mehrwert bei der Automatisierung der Audiocontent-Produktion, der Verbesserung der digitalen Barrierefreiheit und der Personalisierung von Benutzerinteraktionen auf verschiedenen Plattformen, was sie zu einer vielseitigen Komponente innerhalb der breiteren Kategorie kreativer KI-Tools macht.
Diese innovativen Lösungen verändern die Art und Weise, wie Audioinhalte erstellt und konsumiert werden, indem sie über die traditionellen Text-to-Speech-Einschränkungen hinausgehen, um ausdrucksstarke und kontextuell angemessene Sprachleistungen zu liefern. Von der Erstellung fesselnder Erzählungen für Podcasts bis hin zur Bereitstellung dynamischer Sprachantworten im Kundenservice ermöglicht die Generative Sprach-Technologie den Benutzern, hochwertige Audioinhalte effizient und in großem Maßstab zu produzieren.
Kernfunktionen
- Text-to-Speech (TTS): Konvertiert geschriebenen Text mit hoher Wiedergabetreue in natürlich klingende gesprochene Audioinhalte.
- Stimmklonung & -synthese: Repliziert und generiert neue Sprache in einer bestimmten Stimme aus minimalen Audiobeispielen.
- Emotions- und Stilkontrolle: Ermöglicht Benutzern, den emotionalen Ton (z. B. fröhlich, ernst) und den Sprechstil (z. B. Nachrichtensprecher, konversationell) der generierten Stimme anzupassen.
- Mehrsprachige und Akzentunterstützung: Generiert Sprache in einer Vielzahl von Sprachen und regionalen Akzenten, um ein globales Publikum anzusprechen.
- Speech-to-Speech (STS): Transformiert die Eigenschaften einer Stimme in eine andere, während der ursprüngliche Inhalt und die Intonation erhalten bleiben.
Anwendungsszenarien
Generative Sprachwerkzeuge werden in der Medienproduktion, im E-Learning und im Kundenservice weit verbreitet eingesetzt. Content-Ersteller wie Podcaster und YouTuber nutzen sie für effiziente Erzählungen und Charakter-Voiceovers. Unternehmen setzen diese Tools für dynamische Sprachassistenten in IVR-Systemen, Marketingkampagnen und Produktdemonstrationen ein. Sie spielen auch eine entscheidende Rolle dabei, digitale Inhalte einem breiteren Publikum zugänglich zu machen, indem sie Text für sehbehinderte Benutzer in gesprochenes Audio umwandeln.
Auswahlkriterien
Bei der Auswahl eines Generativen Sprachwerkzeugs sollten Sie die Natürlichkeit und emotionale Ausdruckskraft der generierten Stimmen berücksichtigen, da dies die Benutzerbindung direkt beeinflusst. Bewerten Sie die Bandbreite der Anpassungsoptionen, einschließlich verfügbarer Sprachen, Akzente und Sprechstile, um sie an Ihre spezifischen Projektanforderungen anzupassen. Bewerten Sie die Integrationsfähigkeiten mit Ihren bestehenden Content-Erstellungs- oder Kommunikationsplattformen und vergleichen Sie Preismodelle basierend auf dem Nutzungsvolumen. Berücksichtigen Sie schließlich die Benutzerfreundlichkeit und die Verfügbarkeit fortschrittlicher Funktionen wie der Stimmklonung, falls die Replikation spezifischer Markenstimmen für Ihre Strategie unerlässlich ist.
Generative StimmeAnwendungsfälle
Podcast- und Hörbuch-Narration automatisieren
Content-Ersteller und Verlage können Generative Sprachwerkzeuge nutzen, um Skripte in ansprechende Audioinhalte für Podcasts und Hörbücher umzuwandeln. Durch die Auswahl einer passenden Stimme, die Anpassung des Tons und das Hinzufügen von Pausen können sie schnell professionelle Narrationen produzieren. Dies reduziert die Kosten und den Zeitaufwand für die Beauftragung von Sprechern und Studioaufnahmen erheblich und ermöglicht häufigere Veröffentlichungen.
Charakterstimmen für Videospiele generieren
Spieleentwickler können Generative Sprachwerkzeuge nutzen, um vielfältige und konsistente Charakterdialoge zu erstellen, ohne auf umfangreiche Sprachaufnahmen angewiesen zu sein. Durch die Eingabe von Charakterzeilen und die Angabe gewünschter emotionaler Töne oder Akzente können sie schnell mehrere Stimmvarianten generieren. Dies optimiert den Lokalisierungsprozess und ermöglicht dynamische In-Game-Dialoge, die sich an Spielerentscheidungen oder den Erzählverlauf anpassen.
Voiceovers für E-Learning-Module erstellen
Bildungsinhaltsentwickler können Generative Sprachwerkzeuge nutzen, um klare und ansprechende Voiceovers für E-Learning-Module, Präsentationen und Lehrvideos zu produzieren. Dies ermöglicht eine schnelle Iteration von Kursmaterialien und einfache Aktualisierungen, wodurch die Konsistenz über die Lektionen hinweg gewährleistet wird. Die Möglichkeit, verschiedene Stimmen und Sprachen zu wählen, hilft auch bei der Erstellung lokalisierter Inhalte für eine globale Studentenschaft, was die Barrierefreiheit und das Lernengagement verbessert.
Marketing- und Werbe-Voiceovers produzieren
Marketingfachleute können Generative Sprachwerkzeuge nutzen, um überzeugende Voiceovers für Werbespots, Promotionsvideos und Social-Media-Anzeigen zu erstellen. Dies ermöglicht schnelle A/B-Tests verschiedener Stimmstile und Botschaften zur Optimierung der Kampagnenleistung. Die Fähigkeit, schnell hochwertige Audioinhalte in verschiedenen Sprachen zu generieren, unterstützt auch globale Marketingbemühungen und stellt sicher, dass die Markenbotschaft bei unterschiedlichen Zielgruppen ohne hohe Produktionskosten ankommt.
Barrierefreiheit für Webinhalte verbessern
Website-Betreiber und Content-Manager können Generative Sprachwerkzeuge einsetzen, um geschriebene Artikel, Blogbeiträge und Webseiten in gesprochenes Audio umzuwandeln. Dies verbessert die Barrierefreiheit für sehbehinderte Benutzer oder solche, die lieber zuhören als lesen, erheblich. Durch das Anbieten einer Audioversion können Websites ein breiteres Publikum erreichen, Barrierefreiheitsstandards einhalten und das gesamte Benutzererlebnis verbessern, wodurch Informationen inklusiver werden.
Interaktive Sprachdialogsysteme (IVR) personalisieren
Unternehmen können Generative Sprach-Technologie in ihre IVR-Systeme integrieren, um natürlichere und personalisiertere Kundenservice-Interaktionen zu ermöglichen. Anstatt sich auf vorab aufgezeichnete, statische Nachrichten zu verlassen, können IVR-Systeme dynamisch auf spezifische Kundenanfragen zugeschnittene Antworten generieren, wobei eine konsistente Markenstimme verwendet wird. Dies erhöht die Kundenzufriedenheit durch ein flüssigeres und menschenähnlicheres Gesprächserlebnis, reduziert Frustration und verbessert die Lösungsraten.