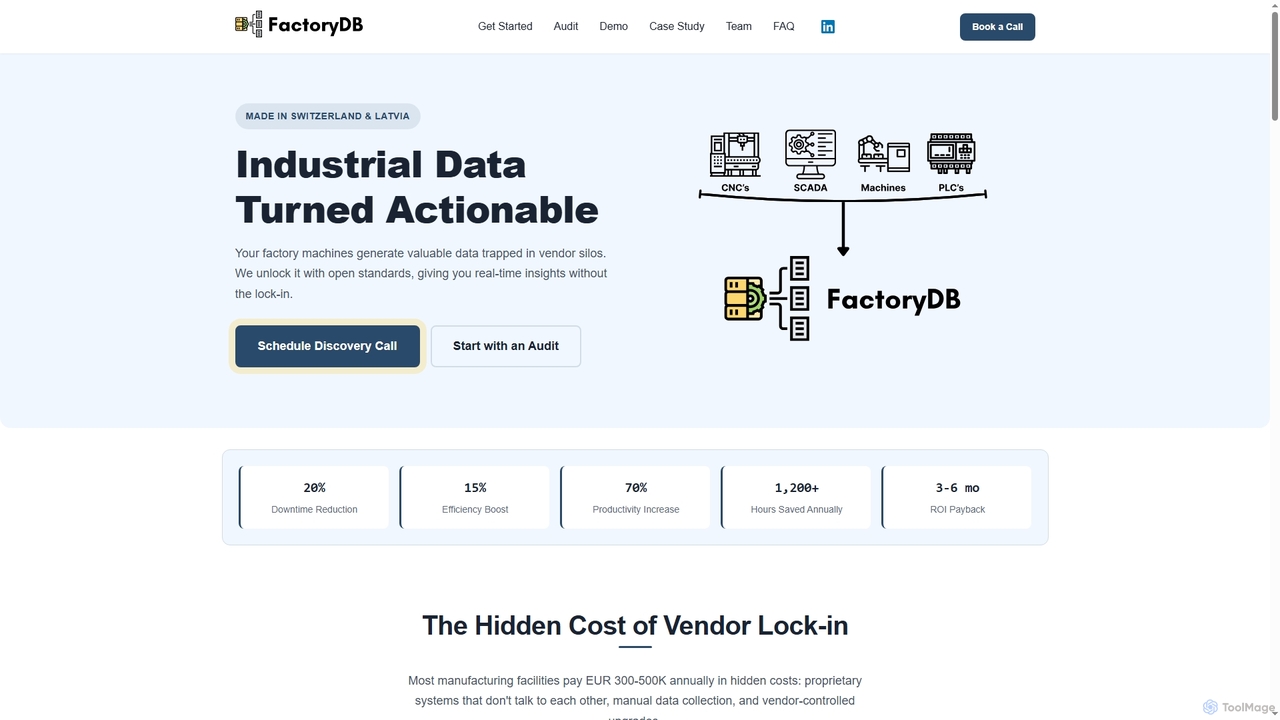
FactoryDB
FactoryDB ist eine industrielle Dateninfrastrukturplattform, die entwickelt wurde, um die Herstellerabhängigkeit (Vendor Lock-in) für Produzenten zu beseitigen. Durch …
FactoryDB ist eine industrielle Dateninfrastrukturplattform, die entwickelt wurde, um die Herstellerabhängigkeit (Vendor Lock-in) für Produzenten zu beseitigen. Durch die Verwendung offener Standards wie MQTT werden Daten von SPS, SCADA und MES-Systemen in einer einzigen, herstellerneutralen Datenschicht vereinheitlicht. Dies ermöglicht Echtzeitanalysen, vorausschauende Wartung und erhebliche Effizienzsteigerungen, insbesondere für regulierte Branchen wie Pharma, Lebensmittel & Getränke und Energie.
Über Dateninfrastruktur
Dateninfrastruktur-Tools sind spezialisierte KI-gestützte Lösungen, die die grundlegenden Systeme für die Sammlung, Speicherung, Verarbeitung und Verwaltung der riesigen Datensätze bereitstellen, die für Operationen der künstlichen Intelligenz und des maschinellen Lernens unerlässlich sind. Diese Tools gewährleisten Datenverfügbarkeit, -integrität und -leistung und ermöglichen ein effizientes Training, die Bereitstellung und Skalierung von KI-Modellen innerhalb der breiteren IT-Landschaft. Sie sind entscheidend für die Bewältigung der einzigartigen Anforderungen von KI-Workloads, von der Echtzeit-Datenerfassung bis zur komplexen analytischen Verarbeitung.
Kernfunktionen
- Skalierbarer Datenspeicher: Bietet hochleistungsfähige, verteilte Speicherlösungen, die für große KI-Datensätze optimiert sind und verschiedene Datentypen und Zugriffsmuster unterstützen.
- Automatisierte Datenpipelines: Erleichtert die Erstellung und Verwaltung automatisierter Datenaufnahme-, Transformations- und Lade-Pipelines (ETL), um Daten für das Training von KI-Modellen vorzubereiten.
- Echtzeit-Datenverarbeitung: Ermöglicht die Verarbeitung und Analyse von Streaming-Daten mit geringer Latenz, was für Echtzeit-KI-Anwendungen wie Betrugserkennung oder Empfehlungssysteme entscheidend ist.
- Datengovernance & Sicherheit: Implementiert robuste Sicherheitsmaßnahmen, Zugriffskontrollen und Compliance-Frameworks zum Schutz sensibler KI-Trainingsdaten und Modellausgaben.
- Ressourcenorchestrierung: Verwaltet und optimiert Rechenressourcen (GPUs, CPUs) und Speicher in verteilten Umgebungen für eine effiziente Ausführung von KI-Workloads.
Anwendungsszenarien
Die Dateninfrastruktur ist für Organisationen, die KI entwickeln und einsetzen, unverzichtbar. Zum Beispiel benötigt ein großes Technologieunternehmen, das ein neues Sprachmodell entwickelt, eine robuste Infrastruktur, um Petabytes an Textdaten zu speichern und verteilte Trainingsjobs über Tausende von GPUs zu verwalten. Ähnlich nutzen Finanzinstitute sie für die Echtzeitverarbeitung von Transaktionsdaten, um KI-gesteuerte Betrugserkennungssysteme zu betreiben und eine sofortige Analyse und Reaktion zu gewährleisten. E-Commerce-Plattformen nutzen sie, um Kundendaten zu sammeln und zu verarbeiten, die Empfehlungssysteme speisen, die Benutzererlebnisse personalisieren.
Auswahlkriterien
Die Auswahl der richtigen Dateninfrastruktur-Tools erfordert die Bewertung mehrerer Schlüsselfaktoren. Berücksichtigen Sie die erforderliche Skalierbarkeit, um zukünftiges Datenwachstum und zunehmende KI-Modellkomplexität zu bewältigen. Bewerten Sie die Leistungsanforderungen, einschließlich Datenaufnahmeraten, Verarbeitungsgeschwindigkeit und Abfragelatenz, insbesondere für Echtzeitanwendungen. Bewerten Sie die Integrationsfähigkeiten mit bestehenden KI/ML-Plattformen, Datenquellen und Cloud-Umgebungen. Prüfen Sie schließlich Sicherheitsfunktionen, Compliance-Zertifizierungen und die Gesamtbetriebskosten, einschließlich Betriebsaufwand und Wartung.
DateninfrastrukturAnwendungsfälle
Aufbau skalierbarer KI-Modelltrainingspipelines
Maschinelles Lernen-Ingenieure und Datenwissenschaftler nutzen eine robuste Dateninfrastruktur, um effiziente und skalierbare Pipelines für das Training von KI-Modellen aufzubauen. Dies umfasst die Automatisierung der Erfassung riesiger Datensätze aus verschiedenen Quellen, die Durchführung notwendiger Datenbereinigung und -transformation sowie die Bereitstellung vorbereiteter Daten für ML-Plattformen. Eine gut konzipierte Infrastruktur gewährleistet eine konsistente Datenqualität und -verfügbarkeit, wodurch der Zeit- und Arbeitsaufwand für die iterative Modellentwicklung und -bereitstellung erheblich reduziert wird, was zu schnellerer Innovation und verbesserter Modellleistung führt.
Aufbau skalierbarer KI/ML-Trainingspipelines
Datenwissenschaftler und Machine-Learning-Ingenieure nutzen die Dateninfrastruktur, um robuste und skalierbare Pipelines für das Training von KI-Modellen aufzubauen. Dies umfasst das effiziente Erfassen großer Datensätze aus verschiedenen Quellen, die Durchführung komplexer Datentransformationen (ETL) und das Speichern der vorbereiteten Daten in optimierten Data Lakes oder Data Warehouses. Die Infrastruktur gewährleistet Datenqualität, -herkunft und -zugänglichkeit, was eine schnelle Iteration des Modelltrainings, Versionskontrolle und nahtlose Integration mit KI-Plattformen ermöglicht und letztendlich die Entwicklung und Bereitstellung leistungsstarker KI-Lösungen beschleunigt.
Aufbau skalierbarer Datenpipelines für KI-Training
Datenwissenschaftler und ML-Ingenieure nutzen Dateninfrastruktur-Tools, um automatisierte Pipelines zu erstellen, die Rohdaten aus verschiedenen Quellen aufnehmen, bereinigen, transformieren und in optimierten Formaten speichern. Dies gewährleistet eine kontinuierliche Versorgung mit hochwertigen, vorverarbeiteten Daten, die für das Training und die Feinabstimmung komplexer KI-Modelle unerlässlich sind, wodurch der manuelle Datenaufbereitungsaufwand erheblich reduziert und die Modellgenauigkeit verbessert wird.
Aufbau skalierbarer Datenpipelines für das KI-Training
Datenwissenschaftler und ML-Ingenieure benötigen robuste Datenpipelines, um saubere, vorverarbeitete Daten in KI-Modelle einzuspeisen. Dateninfrastruktur-Tools ermöglichen die automatisierte Aufnahme, Transformation und das Laden (ETL) massiver Datensätze aus verschiedenen Quellen in Data Lakes oder Data Warehouses. Dies gewährleistet eine kontinuierliche Versorgung mit hochwertigen Daten, reduziert die manuelle Datenvorbereitungszeit erheblich und beschleunigt den iterativen Prozess des Modelltrainings und der Verfeinerung, was zu genaueren und effizienteren KI-Systemen führt.
Aufbau skalierbarer Data Lakes für das KI-Training
Datenwissenschaftler und Machine-Learning-Ingenieure benötigen einen robusten Data Lake, um vielfältige, rohe Datensätze (Bilder, Text, Audio, Sensordaten) in großem Maßstab für das Training komplexer KI-Modelle zu speichern. Dateninfrastruktur-Tools erleichtern die Erstellung solcher Lakes, indem sie flexiblen Speicher, Metadatenmanagement und effiziente Datenabrufmechanismen bereitstellen. Dies ermöglicht eine iterative Modellentwicklung und -experimente ohne Datenengpässe, gewährleistet hochwertige Eingaben für Deep-Learning-Algorithmen und reduziert die Trainingszeiten.
Echtzeit-Analysen für Business Intelligence
Geschäftsanalysten und Dateningenieure nutzen Echtzeit-Dateninfrastrukturen, um sofortige Einblicke in die Betriebsleistung und das Kundenverhalten zu erhalten. Durch die Verarbeitung von Streaming-Daten aus Anwendungen, IoT-Geräten oder Transaktionssystemen können Organisationen wichtige Kennzahlen in Echtzeit überwachen. Diese Fähigkeit ermöglicht proaktive Entscheidungsfindung, wie die Identifizierung aufkommender Markttrends, die Erkennung von Anomalien bei Finanztransaktionen oder die sofortige Personalisierung von Kundenerlebnissen, was durch zeitnahe Informationen einen Wettbewerbsvorteil bietet.
Betrieb von Echtzeit-Business-Intelligence-Dashboards
Geschäftsanalysten und Betriebsleiter verlassen sich auf die Dateninfrastruktur, um Echtzeit-Business-Intelligence (BI)-Dashboards zu speisen. Die Infrastruktur verarbeitet Streaming-Daten aus Vertrieb, Kundeninteraktionen und Betriebssystemen mit geringer Latenz, um sicherzustellen, dass BI-Tools die aktuellsten Metriken anzeigen. Dies ermöglicht sofortige Einblicke in wichtige Leistungsindikatoren (KPIs), wodurch Entscheidungsträger schnell auf Marktveränderungen reagieren, aufkommende Trends erkennen und Betriebsstrategien ohne Verzögerung optimieren können, was die Geschäftsagilität und Reaktionsfähigkeit erheblich verbessert.
Ermöglichung von Echtzeit-Analysen für den Geschäftsbetrieb
Geschäftsanalysten und Betriebsleiter nutzen Datenstreaming- und Data-Warehousing-Lösungen innerhalb der Dateninfrastruktur, um eingehende Datenströme sofort zu verarbeiten und zu analysieren. Dies ermöglicht die Echtzeitüberwachung wichtiger Leistungsindikatoren, die sofortige Betrugserkennung und ein dynamisches Bestandsmanagement, wodurch kritische Einblicke für agile Entscheidungen und eine schnelle Reaktion auf Marktveränderungen bereitgestellt werden.
Echtzeitanalyse und Business Intelligence
Geschäftsanalysten und Entscheidungsträger benötigen sofortige Einblicke aus Betriebsdaten, um schnell auf Marktveränderungen reagieren zu können. Die Dateninfrastruktur bildet das Rückgrat für Echtzeit-Datenstreaming und -verarbeitung, was die sofortige Aggregation und Analyse eingehender Daten aus Verkäufen, Kundeninteraktionen oder IoT-Sensoren ermöglicht. Diese Fähigkeit unterstützt dynamische Dashboards, Betrugserkennung und personalisierte Kundenerlebnisse und ermöglicht proaktive Geschäftsstrategien und Wettbewerbsvorteile.
Echtzeit-Datenerfassung für KI-gestützte Analysen
Für Anwendungen wie Betrugserkennung, personalisierte Empfehlungen oder IoT-Überwachung benötigen KI-Modelle Zugriff auf frische, Echtzeit-Datenströme. Dateninfrastruktur-Tools bieten Hochdurchsatz-Erfassungspipelines, die Streaming-Daten mit minimaler Latenz erfassen, verarbeiten und bereitstellen. Dies ermöglicht es KI-Systemen, sofortige, datengesteuerte Entscheidungen zu treffen, auf Ereignisse zu reagieren, sobald sie auftreten, und die Reaktionsfähigkeit und Genauigkeit von Echtzeit-KI-Anwendungen erheblich zu verbessern.
Sicherstellung von Datengovernance und Compliance
Compliance-Beauftragte und Datenverwalter verlassen sich auf die Dateninfrastruktur, um umfassende Datengovernance-Richtlinien zu etablieren und durchzusetzen, die regulatorische Anforderungen wie DSGVO oder HIPAA erfüllen. Diese Tools bieten Mechanismen für die Datenherkunftsverfolgung, Zugriffskontrolle, Datenmaskierung und Auditierung, wodurch Datenintegrität und -sicherheit gewährleistet werden. Durch die Zentralisierung der Governance-Bemühungen können Organisationen Compliance-Risiken minimieren, die Datenqualität aufrechterhalten und Vertrauen bei Kunden und Stakeholdern aufbauen, wodurch kostspielige Strafen und Reputationsschäden vermieden werden.
Erreichen einer 360-Grad-Kundenansicht für die Personalisierung
Marketing- und Kundendienstteams nutzen die Dateninfrastruktur, um disparate Kundendaten aus CRM-, Vertriebs-, Social-Media- und Webanalyseplattformen in einem einheitlichen Kundenprofil zu konsolidieren. Diese umfassende 360-Grad-Ansicht ermöglicht es Unternehmen, das Kundenverhalten, die Präferenzen und die Customer Journey über alle Berührungspunkte hinweg zu verstehen. Durch die Nutzung dieser integrierten Daten können Unternehmen hochgradig personalisierte Marketingkampagnen, maßgeschneiderte Produktempfehlungen und proaktiven Kundensupport bereitstellen, wodurch die Kundenzufriedenheit erheblich verbessert und höhere Konversionsraten und Kundenbindung erzielt werden.
Sicherstellung von Datengovernance und Compliance
Compliance-Beauftragte und Datenverwalter implementieren Dateninfrastrukturkomponenten wie Datenkataloge, Metadatenmanagement und Zugriffskontrollen, um Datengovernance-Richtlinien durchzusetzen. Dies gewährleistet Datenqualität, Herkunftsverfolgung und die Einhaltung von Vorschriften wie DSGVO oder HIPAA, wodurch Risiken im Zusammenhang mit Datenlecks und Nichteinhaltung gemindert und gleichzeitig die Datenintegrität im gesamten Unternehmen aufrechterhalten werden.
Sichere Datenspeicherung und Governance für Compliance
Organisationen, die sensible Kunden- oder proprietäre Daten verarbeiten, insbesondere in regulierten Branchen wie Finanzen oder Gesundheitswesen, müssen strenge Datensicherheit und Compliance gewährleisten. Dateninfrastruktur-Lösungen bieten verschlüsselten Speicher, granulare Zugriffssteuerungen, Datenmaskierung und Audit-Trails, um Vorschriften wie DSGVO oder HIPAA zu erfüllen. Dies schützt vor Datenlecks, erhält das Kundenvertrauen und vermeidet hohe Bußgelder, wodurch legale und ethische Datenverarbeitungspraktiken sichergestellt werden.
Orchestrierung verteilter KI-Modelltrainings-Workloads
Das Training großer KI-Modelle, insbesondere tiefer neuronaler Netze, erfordert oft erhebliche Rechenressourcen, die auf mehrere GPUs oder Cluster verteilt sind. Dateninfrastruktur-Lösungen umfassen Orchestrierungsfunktionen, die diese verteilten Workloads verwalten, Ressourcen effizient zuweisen, den Fortschritt von Jobs überwachen und Fehler behandeln. Dies stellt sicher, dass komplexe Trainingsläufe zuverlässig und optimal abgeschlossen werden, wodurch die Ressourcenauslastung maximiert und der Entwicklungszyklus für fortgeschrittene KI beschleunigt wird.
Konsolidierung von Daten aus verschiedenen Quellen
Datenarchitekten und IT-Manager nutzen Dateninfrastrukturen, um Informationen aus verschiedenen isolierten Systemen wie CRM, ERP und Marketingplattformen in einem einheitlichen Datenrepository zu integrieren und zu konsolidieren. Dieser Prozess umfasst die Gestaltung effizienter ETL/ELT-Workflows zum Extrahieren, Transformieren und Laden von Daten, wodurch eine einzige Quelle der Wahrheit geschaffen wird. Eine konsolidierte Datenansicht erleichtert umfassende Berichterstattung, funktionsübergreifende Analysen und unterstützt die Entwicklung ganzheitlicher KI-Anwendungen, die alle verfügbaren Organisationsdaten nutzen.
Sicherstellung der Einhaltung gesetzlicher Vorschriften und Datenprüfung
Compliance-Beauftragte und Rechtsteams in regulierten Branchen wie Finanzen und Gesundheitswesen verlassen sich auf eine robuste Dateninfrastruktur, um strenge gesetzliche Anforderungen wie DSGVO, HIPAA oder CCPA zu erfüllen. Die Infrastruktur bietet sichere Datenspeicherung mit Verschlüsselung, detaillierte Nachverfolgung der Datenherkunft und umfassende Auditfunktionen. Dies stellt sicher, dass alle Datenoperationen transparent, nachvollziehbar und konform sind, wodurch rechtliche Risiken minimiert und schnelle Reaktionen auf Prüfungsanfragen ermöglicht werden, indem ordnungsgemäße Datenverarbeitung, Zugriffskontrollen und Aufbewahrungsrichtlinien nachgewiesen werden.
Konsolidierung unterschiedlicher Datenquellen in einem einheitlichen Data Lake
Unternehmensarchitekten und Dateningenieure nutzen Data-Lake-Lösungen, um große Mengen strukturierter und unstrukturierter Daten aus verschiedenen Abteilungssystemen, IoT-Geräten und externen Feeds zu zentralisieren. Dieses einheitliche Repository erleichtert die umfassende Datenexploration und erweiterte Analysen, bricht Datensilos auf und bietet eine ganzheitliche Sicht für strategische Planung und Innovation.
Migration von Altdaten auf Cloud-native Plattformen
IT-Administratoren und Cloud-Architekten stehen oft vor der Herausforderung, große Mengen historischer Daten von On-Premise-Systemen in moderne Cloud-Umgebungen zu verschieben. Dateninfrastruktur-Tools erleichtern diese komplexe Migration durch die Bereitstellung robuster Konnektoren, Datenvalidierungsmechanismen und skalierbarer Übertragungsfunktionen. Dieser Übergang ermöglicht es Organisationen, die Elastizität der Cloud zu nutzen, Betriebskosten zu senken und neue analytische Möglichkeiten mit Cloud-basierten KI-Diensten zu erschließen, wodurch ihre Datenlandschaft modernisiert wird.
Gewährleistung von Datengovernance und Sicherheit für KI-Datensätze
KI-Modelle sind nur so gut wie die Daten, mit denen sie trainiert werden, und diese Daten enthalten oft sensible Informationen. Dateninfrastruktur-Tools bieten kritische Funktionen für die Datengovernance, einschließlich Zugriffskontrolle, Verschlüsselung, Datenmaskierung und Audit-Trails. Dies hilft Organisationen, Vorschriften wie DSGVO oder HIPAA einzuhalten, proprietäre Daten zu schützen und die Integrität und den Datenschutz von Datensätzen für die KI-Entwicklung zu wahren, Vertrauen aufzubauen und Risiken zu mindern.
Optimierung der Datenspeicherung für Kosten und Leistung
Cloud-Architekten und Datenbetriebsteams setzen Dateninfrastrukturlösungen ein, um Speicherstrategien zu optimieren und Kosteneffizienz mit Leistungsanforderungen in Einklang zu bringen. Dies umfasst die Implementierung von gestuftem Speicher, Datenkomprimierung und intelligenten Richtlinien für das Datenlebenszyklusmanagement, um seltener aufgerufene Daten auf günstigere Speicherebenen zu verschieben, während kritische Daten jederzeit verfügbar bleiben. Eine effektive Speicheroptimierung reduziert Cloud-Ausgaben, verbessert die Datenabrufgeschwindigkeiten und stellt sicher, dass Ressourcen effizient basierend auf Datenwert und Zugriffsmustern zugewiesen werden.
Verwaltung großer IoT-Datenmengen für die vorausschauende Wartung
Industrieingenieure und Betriebsleiter in der Fertigung oder Logistik nutzen die Dateninfrastruktur, um massive Datenmengen zu erfassen und zu verarbeiten, die von IoT-Sensoren an Maschinen, Fahrzeugen oder Infrastrukturen erzeugt werden. Dieser Echtzeit-Datenstrom, einschließlich Temperatur, Vibration und Leistungsmetriken, wird analysiert, um Anomalien zu identifizieren und potenzielle Geräteausfälle vorherzusagen. Durch die Implementierung prädiktiver Wartungsstrategien auf der Grundlage dieser Erkenntnisse können Unternehmen Ausfallzeiten minimieren, Reparaturkosten senken und die Lebensdauer kritischer Anlagen verlängern, wodurch die Betriebseffizienz optimiert und kostspielige Unterbrechungen verhindert werden.
Optimierung der Datenspeicherung für Kosten und Leistung
IT-Administratoren und Cloud-Architekten setzen innerhalb der Dateninfrastruktur gestufte Speicherlösungen und Datenarchivierung ein, um den Datenlebenszyklus effizient zu verwalten. Durch die Kategorisierung von Daten basierend auf Zugriffsfrequenz und Aufbewahrungsrichtlinien können sie seltener aufgerufene Daten in kostengünstigere Speicherebenen verschieben, wodurch Leistungsanforderungen mit Budgetbeschränkungen in Einklang gebracht und die langfristige Datenverfügbarkeit sichergestellt werden.
Unterstützung der Bereitstellung von Machine-Learning-Modellen im großen Maßstab
Nach dem Training erfordert die Bereitstellung von Machine-Learning-Modellen in der Produktion eine stabile und leistungsstarke Datenbereitstellungsschicht. Die Dateninfrastruktur stellt sicher, dass Modelle mit geringer Latenz und hohem Durchsatz auf die erforderlichen Merkmale und Inferenzdaten zugreifen können. Dies beinhaltet optimierte Datenspeicher, Caching-Mechanismen und die Integration mit Modellbereitstellungsplattformen. Eine gut konzipierte Infrastruktur garantiert, dass bereitgestellte KI-Anwendungen Endbenutzern konsistente, Echtzeit-Vorhersagen und -Empfehlungen liefern.
Automatisierung von ETL-Pipelines für das Feature Engineering im maschinellen Lernen
Bevor Daten für maschinelles Lernen verwendet werden können, bedürfen sie oft einer umfassenden Bereinigung, Transformation und Feature Engineering. Dateninfrastruktur-Tools automatisieren diese Extraktions-, Transformations- und Lade-Prozesse (ETL), wodurch Dateningenieure wiederholbare Pipelines erstellen können, die Daten für den Modellverbrauch vorbereiten. Dies reduziert den manuellen Aufwand, gewährleistet Datenkonsistenz und beschleunigt die Zeit bis zur Erkenntnis für Machine-Learning-Projekte, indem gut strukturierte Features für eine optimale Modellleistung bereitgestellt werden.
Unterstützung großer Datenmigrationsprojekte
IT-Projektmanager und Migrationsspezialisten nutzen eine robuste Dateninfrastruktur, um große Datenmigrationsprojekte zu planen und durchzuführen, wie z.B. die Verlagerung von Daten von On-Premise-Systemen in die Cloud oder die Konsolidierung mehrerer Altdatenbanken. Diese Tools bieten Funktionen für Datenprofilierung, Bereinigung, Mapping und sichere Übertragung, minimieren Ausfallzeiten und gewährleisten die Datenintegrität während des gesamten Migrationsprozesses. Eine gut verwaltete Datenmigrationsinfrastruktur mindert Risiken, beschleunigt den Projektabschluss und sorgt für einen reibungslosen Übergang in neue Datenumgebungen.
Aufbau eines skalierbaren Data Lakes für Big Data Analytics
Unternehmensarchitekten und Dateningenieure entwerfen und implementieren Dateninfrastrukturen, um skalierbare Data Lakes zu schaffen, die in der Lage sind, verschiedene Datentypen, einschließlich Roh-, semistrukturierter und unstrukturierter Daten, in massivem Umfang zu speichern. Dies dient als zentrales Repository für Big Data Analytics und ermöglicht es Datenwissenschaftlern, explorative Analysen durchzuführen, neue Datenmodelle zu erstellen und Datensätze für zukünftige KI-Projekte ohne die Einschränkungen traditioneller Data Warehouses vorzubereiten. Die Data-Lake-Infrastruktur unterstützt flexible Schema-on-Read-Ansätze, was Agilität bei der Datenexploration ermöglicht und Innovationen im gesamten Unternehmen fördert.
Unterstützung hybrider und Multi-Cloud-Datenumgebungen
Cloud-Architekten und DevOps-Teams nutzen Dateninfrastruktur-Tools, die eine nahtlose Integration und Verwaltung über On-Premise- und mehrere Cloud-Plattformen hinweg bieten. Dies ermöglicht es Organisationen, die besten Funktionen verschiedener Umgebungen zu nutzen, Datenportabilität zu gewährleisten und die Geschäftskontinuität aufrechtzuerhalten, wodurch Flexibilität und Resilienz für sich entwickelnde Datenstrategien ohne Anbieterbindung geboten werden.
Data Lake Management für unstrukturierte Daten
Dateningenieure und Forscher arbeiten häufig mit verschiedenen, unstrukturierten Datentypen wie Bildern, Videos, Audio und Text, die für fortschrittliche KI-Anwendungen wie Computer Vision und natürliche Sprachverarbeitung entscheidend sind. Die Dateninfrastruktur bietet Data-Lake-Lösungen, die Rohdaten mit Schema-on-Read in großem Maßstab speichern können. Dies ermöglicht eine flexible Erkundung und Experimente mit verschiedenen Datenformaten, wodurch die Entwicklung innovativer KI-Modelle ermöglicht wird, die Erkenntnisse aus zuvor unzugänglichen Informationen ableiten können.
Überwachung und Verwaltung der KI-Anwendungsleistung
Sobald KI-Modelle bereitgestellt sind, müssen ihre Leistung und die zugrunde liegende Dateninfrastruktur kontinuierlich überwacht werden. Tools in dieser Kategorie bieten umfassende Überwachungs-, Protokollierungs- und Alarmierungsfunktionen für Datenpipelines, Speichersysteme und Rechenressourcen. Dies ermöglicht es Betriebsteams, Engpässe schnell zu identifizieren und zu beheben, die Gesundheit des Datenflusses sicherzustellen und die Zuverlässigkeit und Effizienz von KI-gestützten Anwendungen in Produktionsumgebungen aufrechtzuerhalten, wodurch Dienstunterbrechungen verhindert werden.