Plural
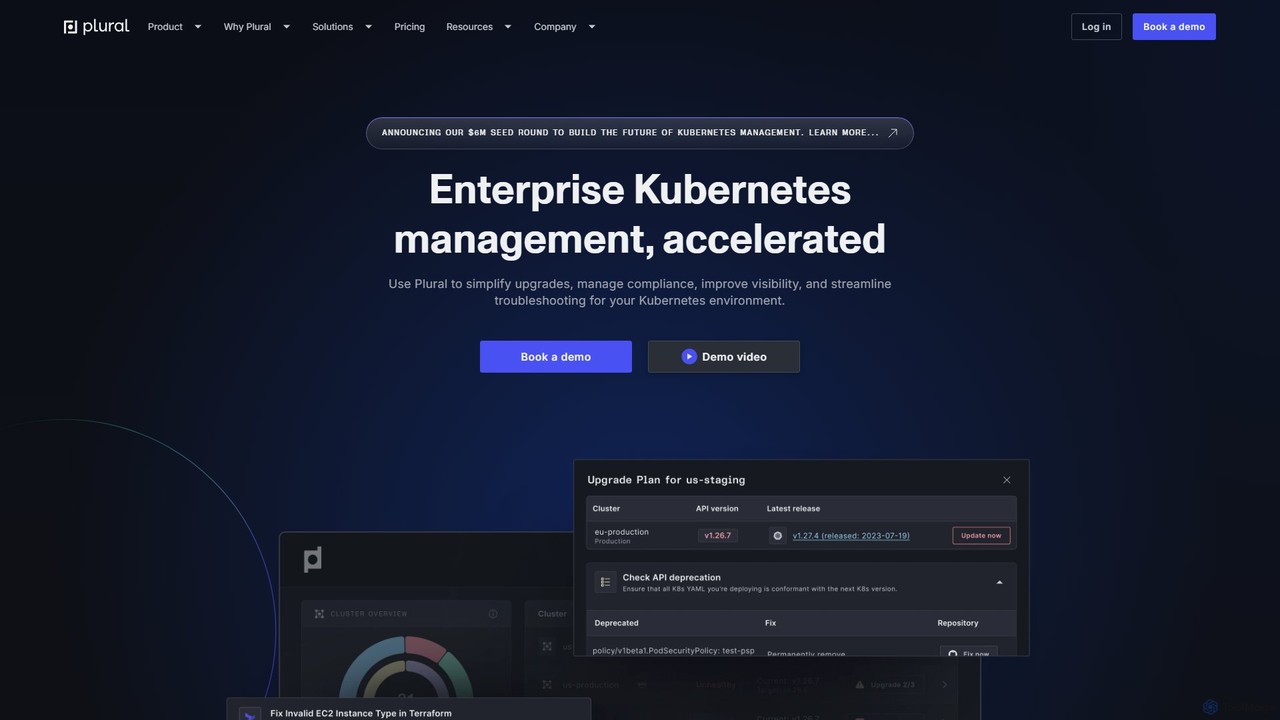
Plural ist eine KI-gestützte Enterprise-Kubernetes-Management-Plattform, die entwickelt wurde, um Operationen zu beschleunigen und zu vereinfachen. Sie bietet Multi-Cloud-Transparenz, …
Plural ist eine KI-gestützte Enterprise-Kubernetes-Management-Plattform, die entwickelt wurde, um Operationen zu beschleunigen und zu vereinfachen. Sie bietet Multi-Cloud-Transparenz, automatisiert komplexe Upgrades, ermöglicht KI-gesteuerte Fehlerbehebung und gewährleistet robuste Sicherheit und Compliance. Ideal für DevOps- und Plattform-Engineering-Teams, reduziert Plural Betriebskosten und steigert die Entwicklergeschwindigkeit.
Über Beobachtbarkeit
Observability-Tools sind KI-gestützte Lösungen, die entwickelt wurden, um tiefe Einblicke in den internen Zustand komplexer Systeme zu ermöglichen, indem sie deren externe Ausgaben analysieren. Diese Tools nutzen Logs, Metriken und Traces, um ein umfassendes Verständnis des Anwendungs- und Infrastrukturverhaltens zu bieten. Sie ermöglichen es IT-Betriebs- und Entwicklungsteams, Probleme proaktiv zu identifizieren, Vorfälle schneller zu beheben und die Systemleistung in modernen verteilten Umgebungen zu optimieren. Indem sie über das traditionelle Monitoring hinausgehen, hilft Observability, die Grundursachen von Problemen aufzudecken und potenzielle Ausfälle vorherzusagen.
Kernfunktionen
- Log-Management & -Analyse: Zentralisierte Sammlung, Parsing, Suche und Korrelation von Log-Daten aus verschiedenen Quellen.
- Metrik-Monitoring & -Alarmierung: Echtzeit-Aggregation, Visualisierung und Alarmierung bei wichtigen Leistungsindikatoren (KPIs) und Systemzustandsmetriken.
- Distributed Tracing: End-to-End-Sichtbarkeit von Anfragen, während sie durch Microservices und verteilte Architekturen fließen, zur Identifizierung von Latenzen und Fehlern.
- Anomalieerkennung: KI-gesteuerte Identifizierung ungewöhnlicher Muster in Daten, die auf aufkommende Probleme hinweisen können, oft bevor sie Benutzer betreffen.
- Dashboarding & Visualisierung: Anpassbare Dashboards zur Darstellung komplexer Daten in einem intuitiven, umsetzbaren Format für schnelle Einblicke.
Anwendungsfälle
Observability-Tools sind unerlässlich für DevOps-, SRE- und IT-Betriebsteams, die Cloud-native Anwendungen, Microservices und komplexe Infrastrukturen verwalten. Sie werden zur Diagnose von Produktionsproblemen, zur Optimierung der Ressourcennutzung und zur Gewährleistung der Servicezuverlässigkeit eingesetzt. Entwickler nutzen diese Tools auch, um das Anwendungsverhalten in realen Szenarien zu verstehen und die Code-Performance zu verbessern.
Auswahlkriterien
Bei der Auswahl einer Observability-Plattform sollten Sie deren Integrationsfähigkeiten mit Ihrem bestehenden Technologie-Stack, ihre Skalierbarkeit zur Bewältigung Ihres Datenvolumens und die Granularität der bereitgestellten Einblicke berücksichtigen. Bewerten Sie das Kostenmodell, die Datenaufbewahrungsrichtlinien und die Benutzerfreundlichkeit der Plattform. Achten Sie auf Funktionen wie KI-gesteuerte Anomalieerkennung, robuste Alarmierung und anpassbare Visualisierungsoptionen, um Ihre spezifischen betrieblichen Anforderungen zu erfüllen.
BeobachtbarkeitAnwendungsfälle
Beschleunigung der Ursachenanalyse bei Produktionsvorfällen
DevOps-Ingenieure nutzen Observability-Tools, um die Ursache von Anwendungsfehlern oder Leistungsabfällen in der Produktion schnell zu lokalisieren. Durch die Korrelation von Logs, Metriken und Distributed Traces über Microservices hinweg können sie die genaue Komponente oder Codeänderung identifizieren, die das Problem verursacht, wodurch die mittlere Reparaturzeit (MTTR) erheblich verkürzt und Dienstunterbrechungen minimiert werden.
Proaktive Leistungsoptimierung und Kapazitätsplanung
SRE-Teams nutzen Observability-Plattformen, um Systemleistungsmetriken kontinuierlich zu überwachen und Trends zu identifizieren. Durch die Analyse historischer Daten und Echtzeit-Einblicke können sie die Ressourcenzuweisung proaktiv optimieren, potenzielle Engpässe erkennen, bevor sie Benutzer betreffen, und zukünftige Kapazitätsanforderungen genau planen, um sicherzustellen, dass das System effizient mit der Nachfrage skaliert.
Verbesserung der Benutzererfahrungsüberwachung und Wirkungsanalyse
Produktmanager und Entwicklungsteams nutzen Observability-Tools, um Einblicke in die tatsächliche Benutzererfahrung zu gewinnen. Durch die Überwachung von Frontend-Leistungsmetriken, die Verfolgung von Benutzerpfaden und deren Korrelation mit der Backend-Systemgesundheit können sie verstehen, wie Infrastrukturprobleme oder Anwendungsfehler die Benutzerzufriedenheit, Konversionsraten und die gesamten Geschäftsergebnisse direkt beeinflussen.
Optimierung der Erkennung und Untersuchung von Sicherheitsvorfällen
Sicherheitsanalysten nutzen Observability-Plattformen für zentralisiertes Log-Management und Anomalieerkennung, um verdächtige Aktivitäten oder potenzielle Sicherheitsverletzungen zu identifizieren. Durch die Korrelation von Sicherheitsereignissen über verschiedene Systemkomponenten hinweg und die Rückverfolgung ihrer Herkunft können sie Vorfälle schnell untersuchen, deren Umfang verstehen und effektive Gegenmaßnahmen implementieren, wodurch die gesamte Systemsicherheit verbessert wird.
Validierung neuer Bereitstellungen und Feature-Releases
Entwicklungs- und QA-Teams nutzen Observability-Tools, um die Gesundheit und Leistung neuer Code-Bereitstellungen und Feature-Releases in Echtzeit zu überwachen. Durch den Vergleich von Metriken und Logs vor und nach einer Bereitstellung können sie schnell Regressionen, Leistungsengpässe oder unerwartete Fehler erkennen, was schnelle Rollbacks oder Hotfixes ermöglicht und die Stabilität der Produktionsumgebung gewährleistet.
Überwachung der Cloud-Infrastrukturgesundheit und Kosteneffizienz
Cloud-Operations-Teams nutzen Observability-Plattformen, um eine umfassende Sichtbarkeit ihrer dynamischen Cloud-Infrastruktur zu erhalten. Sie überwachen die Ressourcenauslastung, die Netzwerkleistung und die Serviceverfügbarkeit bei verschiedenen Cloud-Anbietern. Dies ermöglicht es ihnen, ungenutzte Ressourcen zu identifizieren, Cloud-Ausgaben zu optimieren und die Ausfallsicherheit und Effizienz ihrer Cloud-nativen Anwendungen und Dienste sicherzustellen.