
Sublyzer
Sublyzer ist eine KI-gestützte Analyseplattform, die für SaaS-Gründer und -Entwickler entwickelt wurde, um Einnahmen zu überwachen, Abwanderung zu …
Sublyzer ist eine KI-gestützte Analyseplattform, die für SaaS-Gründer und -Entwickler entwickelt wurde, um Einnahmen zu überwachen, Abwanderung zu verfolgen, die Leistung zu analysieren und Fehler effizient zu beheben. Es bietet ein einheitliches Dashboard mit intelligenter Fehlerverfolgung, KI-Erklärungen und Lösungsvorschlägen über eine Konversationsschnittstelle.
Draftnrun
Draftnrun ist eine Open-Source-KI-Agentenplattform, die Entwickler, Produktteams und Agenturen befähigt, produktionsreife KI-Workflows ohne Code zu entwerfen, bereitzustellen und …
Draftnrun ist eine Open-Source-KI-Agentenplattform, die Entwickler, Produktteams und Agenturen befähigt, produktionsreife KI-Workflows ohne Code zu entwerfen, bereitzustellen und zu überwachen. Sie bietet einen visuellen Builder, umfassende Beobachtbarkeit und flexible Bereitstellungsoptionen, um die KI-Integration zu beschleunigen und volle Kontrolle zu gewährleisten.
Starbase
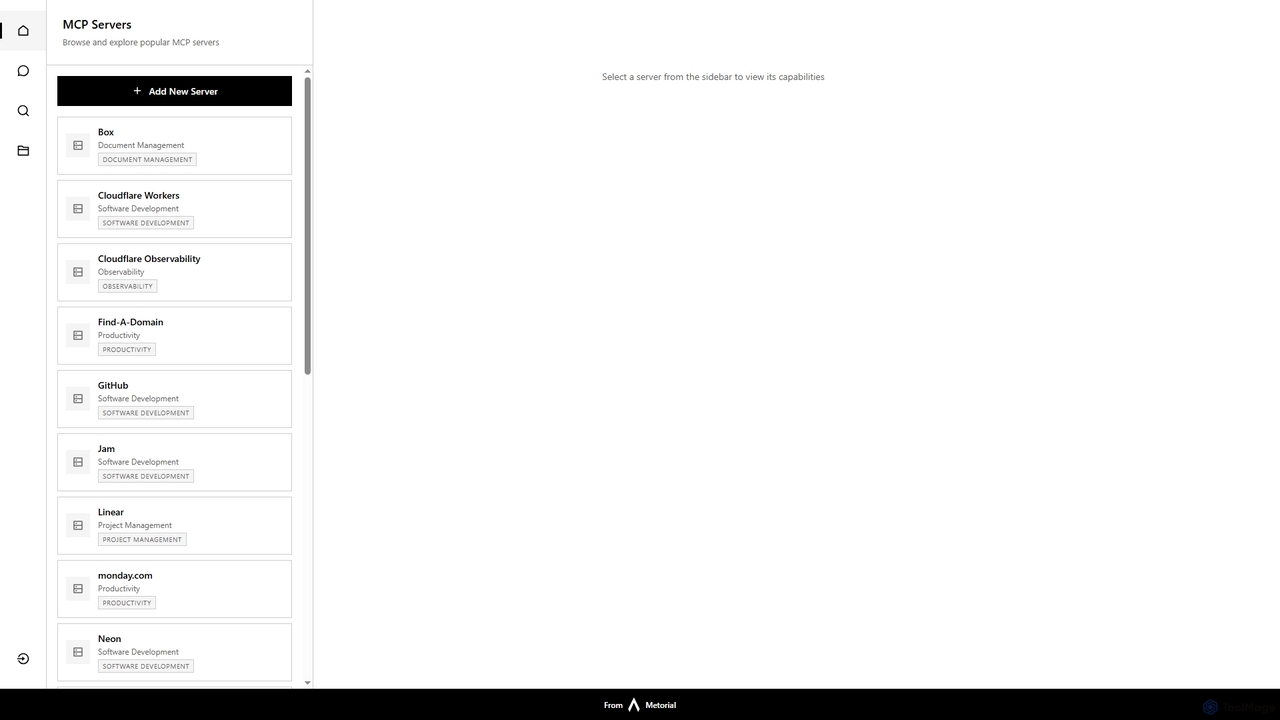
Starbase von Metorial ist eine umfassende Plattform, die entwickelt wurde, um das Browsen, Erkunden und Verwalten verschiedener beliebter …
Starbase von Metorial ist eine umfassende Plattform, die entwickelt wurde, um das Browsen, Erkunden und Verwalten verschiedener beliebter Softwaredienste zu zentralisieren. Sie integriert eine breite Palette von Tools aus den Bereichen Softwareentwicklung, Projektmanagement, Produktivität und Infrastruktur und bietet ein einheitliches Dashboard zur Anzeige und Interaktion mit deren Funktionen.
Über Observierbarkeit
KI-Observability-Tools sind fortschrittliche Plattformen, die maschinelles Lernen nutzen, um tiefe Einblicke in den Zustand und die Leistung komplexer IT-Systeme zu gewähren. Sie sammeln und analysieren automatisch die drei Säulen der Observability – Metriken, Protokolle (Logs) und Traces – um über traditionelles Monitoring hinauszugehen. Durch die Korrelation riesiger Datenmengen können diese Tools proaktiv Anomalien erkennen, potenzielle Ausfälle vorhersagen und die Ursachenanalyse beschleunigen. Dies ermöglicht es Teams, nicht nur zu verstehen, *was* falsch ist, sondern auch *warum*, was die Ausfallzeiten erheblich reduziert und die Systemzuverlässigkeit verbessert.
Kernfunktionen
- Automatisierte Anomalieerkennung: Nutzt Algorithmen des maschinellen Lernens, um ungewöhnliche Muster und Abweichungen vom normalen Verhalten in Echtzeit zu identifizieren.
- KI-gestützte Ursachenanalyse (RCA): Korreliert Signale über Metriken, Protokolle und Traces hinweg, um automatisch die zugrunde liegende Ursache eines Problems zu ermitteln.
- Verteiltes Tracing: Bietet eine durchgängige Sichtbarkeit von Anfragen, während sie durch verteilte Dienste und Microservices reisen.
- Protokollmustererkennung: Gruppiert und analysiert intelligent große Mengen unstrukturierter Protokolldaten, um kritische Ereignisse und Fehler aufzudecken.
- Prädiktive Analytik: Nutzt historische Daten, um zukünftige Leistungstrends und potenzielle Kapazitätsengpässe vorherzusagen.
Anwendungsfälle
Diese Tools sind für DevOps-, Site Reliability Engineering (SRE)- und MLOps-Teams, die moderne, cloud-native Anwendungen verwalten, unerlässlich. Sie werden häufig zur Überwachung von Microservices-Architekturen, Kubernetes-Umgebungen und serverlosen Funktionen eingesetzt, bei denen traditionelles Monitoring an seine Grenzen stößt. Wichtige Anwendungen umfassen die proaktive Vorfallprävention, die Leistungsoptimierung in der Produktion und die Sicherstellung der Zuverlässigkeit von CI/CD-Pipelines.
Auswahlkriterien
Bei der Auswahl eines KI-Observability-Tools sollten Sie dessen Integrationsfähigkeiten mit Ihrem bestehenden Tech-Stack (Cloud-Anbieter, Datenbanken, Frameworks) berücksichtigen. Bewerten Sie die Komplexität seiner KI/ML-Modelle für Anomalieerkennung und RCA. Beurteilen Sie seine Skalierbarkeit zur Verarbeitung Ihres Datenvolumens und die Abfrageleistung. Berücksichtigen Sie schließlich die Intuitivität der Benutzeroberfläche für die Datenexploration und die Klarheit seiner Visualisierungen für umsetzbare Erkenntnisse.
ObservierbarkeitAnwendungsfälle
Proaktive Problemerkennung im E-Commerce
Ein SRE-Team eines großen Online-Händlers nutzt eine KI-Observability-Plattform zur Überwachung seines Checkout-Dienstes. Das auf historischen Leistungsdaten trainierte Machine-Learning-Modell des Tools erkennt einen leichten Anstieg der API-Latenz, der sich noch innerhalb der Standard-Alarmschwellen befindet. Es korreliert dies automatisch mit einer bestimmten Datenbankabfrage und alarmiert das Team, *bevor* die Benutzer Verlangsamungen oder Warenkorbabbrüche bemerken. Dies ermöglicht es den Ingenieuren, die Abfrage proaktiv zu optimieren, um Umsatzverluste zu vermeiden und während eines verkaufsstarken Events ein reibungsloses Kundenerlebnis zu gewährleisten.
Debugging komplexer Microservices
Ein Entwickler hat die Aufgabe, einen Fehler zu beheben, bei dem Benutzerprofil-Updates gelegentlich fehlschlagen. Die Anwendung besteht aus über 50 Microservices. Anstatt die Protokolle für jeden Dienst manuell zu überprüfen, verwendet er die verteilte Tracing-Funktion eines Observability-Tools. Er findet einen Trace für eine fehlgeschlagene Anfrage und sieht sofort die gesamte Aufrufkette. Die Visualisierung zeigt, dass ein nachgelagerter Authentifizierungsdienst ein Timeout hatte, was zu einem kaskadierenden Fehler führte. Das Tool lokalisiert den genauen Dienst und Codeblock und reduziert die Debugging-Zeit von mehreren Stunden auf unter zehn Minuten.
Überwachung von Leistungsabweichungen bei ML-Modellen
Ein MLOps-Team verwaltet ein Betrugserkennungsmodell. Mit einem Observability-Tool überwachen sie nicht nur Systemmetriken, sondern auch modellspezifische Metriken wie Vorhersage-Konfidenzwerte und Merkmalsverteilung. Die KI des Tools erkennt eine allmähliche Abweichung in der Verteilung der Eingabedaten, was darauf hindeutet, dass sich die Transaktionsmuster der Kunden ändern. Es alarmiert das Team, dass die Genauigkeit des Modells wahrscheinlich bald nachlassen wird. Dies ermöglicht es ihnen, proaktiv eine Neutrainings-Pipeline mit neuen Daten auszulösen, um eine hohe Genauigkeit aufrechtzuerhalten und einen Anstieg übersehener betrügerischer Transaktionen zu verhindern.
Optimierung der Cloud-Infrastrukturkosten
Ein IT-Betriebsteam sieht sich mit steigenden Cloud-Rechnungen konfrontiert. Sie setzen ein KI-Observability-Tool in ihren Kubernetes-Clustern ein. Die Plattform analysiert die Ressourcennutzungsmuster (CPU, Speicher) im Vergleich zur Anwendungsleistung. Sie identifiziert mehrere Dienste, die durchgehend überprovisioniert sind und teure Ressourcen ohne entsprechenden Leistungsvorteil verbrauchen. Außerdem werden ineffiziente Datenbankabfragen markiert, die hohe E/A-Kosten verursachen. Basierend auf diesen spezifischen, datengesteuerten Empfehlungen passt das Team die Ressourcenanforderungen an und überarbeitet die Abfragen, was zu einer Reduzierung ihrer monatlichen Cloud-Ausgaben um 25 % führt.
Identifizierung von Sicherheitsbedrohungen durch Protokollanalyse
Ein Sicherheitsanalyst verwendet eine Observability-Plattform, um die Zugriffsprotokolle aller Produktionssysteme zu überwachen. Die KI des Tools clustert automatisch Milliarden von Protokolleinträgen in einige Dutzend Muster. Der Analyst bemerkt ein neues, niederfrequentes Muster, das wiederholte fehlgeschlagene Anmeldeversuche aus einem ungewöhnlichen IP-Bereich zeigt, gefolgt von einer einzigen erfolgreichen Anmeldung. Dieses Muster, das manuell kaum zu finden wäre, wird sofort als potenzieller Brute-Force-Angriff gekennzeichnet. Das Sicherheitsteam kann den IP-Bereich schnell blockieren und das kompromittierte Konto untersuchen, um einen potenziellen Datenverstoß zu verhindern.
Verbesserung der Endbenutzererfahrung mit Leistungsdaten
Ein Produktteam möchte verstehen, warum das Benutzerengagement in seiner mobilen App sinkt. Sie verwenden ein Observability-Tool, das Frontend-Leistungsdaten (z. B. Seitenladezeiten, Interaktionsverzögerungen) mit Backend-Traces verknüpft. Sie entdecken, dass Benutzer in einer bestimmten geografischen Region beim Laden ihrer Profilseite eine hohe Latenz erfahren. Der verteilte Trace zeigt, dass Anfragen aus dieser Region an ein entferntes Rechenzentrum weitergeleitet werden. Durch die Korrelation dieser technischen Daten mit den Aufzeichnungen der Benutzersitzungen bestätigen sie, dass die Benutzer die App aus Frustration verlassen. Das Team arbeitet dann mit dem Betrieb zusammen, um ein besseres Geo-Routing zu implementieren, was die Latenz behebt und das Benutzerengagement wiederherstellt.