Kubiks
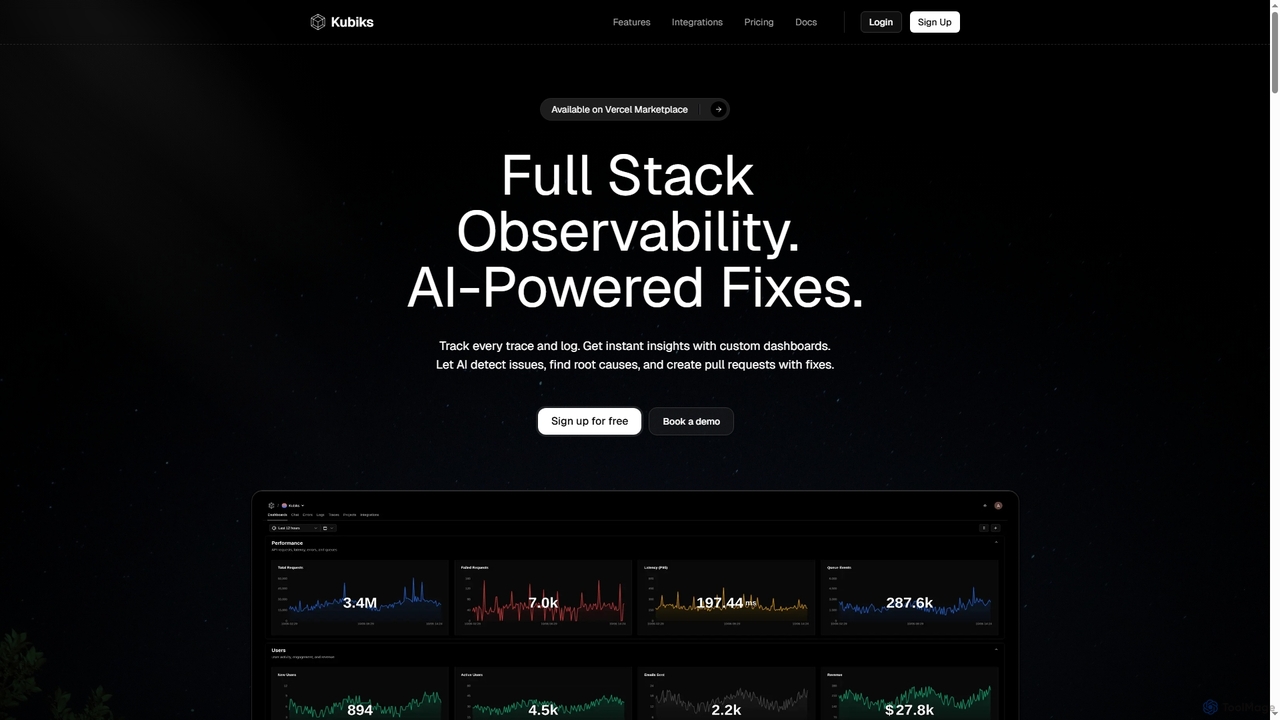
Kubiks ist eine KI-gestützte Full-Stack-Observability-Plattform, die verteiltes Tracing, Logging und benutzerdefinierte Dashboards bietet. Sie erkennt Probleme automatisch, findet …
Kubiks ist eine KI-gestützte Full-Stack-Observability-Plattform, die verteiltes Tracing, Logging und benutzerdefinierte Dashboards bietet. Sie erkennt Probleme automatisch, findet Ursachen und erstellt Pull-Requests mit Korrekturen, um Engineering-Teams dabei zu helfen, schneller zu debuggen und Probleme proaktiv zu lösen.
Über Site Reliability Engineering
Site Reliability Engineering (SRE) ist eine Disziplin, die Software-Engineering-Prinzipien auf Infrastruktur- und Betriebsprobleme anwendet, um hochzuverlässige und skalierbare Systeme zu schaffen. Es nutzt Automatisierung, datengesteuerte Entscheidungsfindung und einen Fokus auf Service Level Objectives (SLOs), um die Stabilität und Leistung kritischer Dienste zu gewährleisten. Als Kernbestandteil der umfassenderen Kategorie „Operations“ ermöglichen SRE-Tools Teams, die Systemgesundheit proaktiv zu verwalten, effizient auf Vorfälle zu reagieren und die Servicezuverlässigkeit kontinuierlich zu verbessern.
Kernfunktionen
- SLO/SLA-Überwachung: Verfolgung und Berichterstattung von Service Level Objectives und Agreements, um sicherzustellen, dass Leistungsziele erreicht werden.
- Incident Management & Automatisierung: Optimierung der Erkennung, Alarmierung, Reaktion und Behebung von Vorfällen durch automatisierte Workflows.
- Fehlerbudget-Management: Definition und Verfolgung akzeptabler Unzuverlässigkeitsgrade, um Entwicklungs- und Betriebs-Prioritäten zu steuern.
- Observability & Monitoring: Bereitstellung umfassender Einblicke in das Systemverhalten durch Logs, Metriken und Traces zur proaktiven Problemidentifikation.
- Kapazitätsplanung: Prognose des Ressourcenbedarfs und Optimierung der Infrastruktur, um erwartete Lasten zu bewältigen und Ausfälle zu verhindern.
Anwendungsszenarien
SRE-Tools sind unerlässlich für Organisationen, die komplexe, verteilte Systeme betreiben, wie z.B. große E-Commerce-Plattformen, SaaS-Anbieter und Finanzdienstleister. Sie ermöglichen SRE-Teams, DevOps-Ingenieuren und Plattform-Ingenieuren, hohe Verfügbarkeit aufrechtzuerhalten, die Zuverlässigkeit von Microservices zu verwalten und kritische Betriebsaufgaben zu automatisieren, wodurch nahtlose Benutzererfahrungen und Geschäftskontinuität gewährleistet werden.
Auswahlkriterien
Bei der Auswahl von SRE-Tools sollten Lösungen priorisiert werden, die robuste Observability-Funktionen, nahtlose Integration mit bestehenden CI/CD-Pipelines und Cloud-Plattformen sowie umfassende Incident-Management-Funktionen bieten. Berücksichtigen Sie die Skalierbarkeit des Tools, Berichtsfunktionen für die SLO-Konformität und seine Fähigkeit, die Fehlerbudget-Verfolgung zu unterstützen. Benutzerfreundlichkeit und Community-Support sind ebenfalls entscheidend für eine effektive Teamadoption.
Site Reliability EngineeringAnwendungsfälle
Automatisierung von Incident-Response-Workflows
Für Bereitschaftsingenieure und SRE-Teams automatisieren KI-gestützte SRE-Tools die Erkennung von Anomalien und kritischen Vorfällen in verteilten Systemen. Sie können Alarme auslösen, Diagnoseskripte starten und sogar auf Basis historischer Daten Abhilfemaßnahmen vorschlagen, wodurch die mittlere Wiederherstellungszeit (MTTR) erheblich reduziert und Dienstunterbrechungen bei kritischen Ausfällen minimiert werden.
Überwachung und Durchsetzung von Service Level Objectives (SLOs)
SRE-Teams nutzen diese Tools, um Service Level Objectives (SLOs) für kritische Dienste zu definieren, zu überwachen und durchzusetzen. Die Tools sammeln und analysieren kontinuierlich Metriken (z. B. Latenz, Fehlerrate, Verfügbarkeit) und stellen Echtzeit-Dashboards und Alarme bereit, wenn SLOs gefährdet sind, sodass Teams Leistungsverschlechterungen proaktiv beheben können, bevor sie Benutzer beeinträchtigen.
Proaktive Kapazitätsplanung und Ressourcenoptimierung
Infrastrukturarchitekten und SREs nutzen SRE-Tools für datengesteuerte Kapazitätsplanung. Durch die Analyse historischer Nutzungsmuster und die Vorhersage zukünftiger Nachfrage helfen diese Tools, die Ressourcenzuweisung zu optimieren, Engpässe zu vermeiden und sicherzustellen, dass Systeme effizient skaliert werden können, um Verkehrsspitzen zu bewältigen. Dadurch werden kostspielige Überprovisionierung oder Dienstausfälle aufgrund von Unterprovisionierung vermieden.
Durchführung von Blameless Post-Mortem-Analysen
Nach einem Vorfall erleichtern SRE-Tools umfassende Post-Mortem-Analysen, indem sie Logs, Metriken und Traces aus verschiedenen Quellen aggregieren. Dies ermöglicht SRE- und Entwicklungsteams, Grundursachen zu identifizieren, beitragende Faktoren zu verstehen und gelernte Lektionen ohne Schuldzuweisung zu dokumentieren, wodurch eine Kultur der kontinuierlichen Verbesserung gefördert und das Wiederauftreten ähnlicher Probleme verhindert wird.
Implementierung und Verwaltung von Fehlerbudgets
Produktverantwortliche und SREs nutzen diese Tools, um Fehlerbudgets zu implementieren und zu verwalten, die das akzeptable Maß an Unzuverlässigkeit für einen Dienst quantifizieren. Die Tools verfolgen den Verbrauch des Fehlerbudgets in Echtzeit und geben Produkt- und Engineering-Teams klare Signale, wann Zuverlässigkeitsarbeit gegenüber der Entwicklung neuer Funktionen priorisiert werden sollte, um Innovation und Stabilität auszugleichen.
Verbesserung der Observability in komplexen verteilten Systemen
Plattformingenieure und SREs setzen diese Tools ein, um tiefe Observability in Microservices-Architekturen und Cloud-nativen Anwendungen zu erhalten. Durch die Korrelation von Metriken, Logs und Traces über Hunderte oder Tausende von Diensten hinweg bieten die Tools eine einheitliche Ansicht der Systemgesundheit, was schnelles Debugging, Leistungsoptimierung und ein ganzheitliches Verständnis des Systemverhaltens ermöglicht.