hey_photo
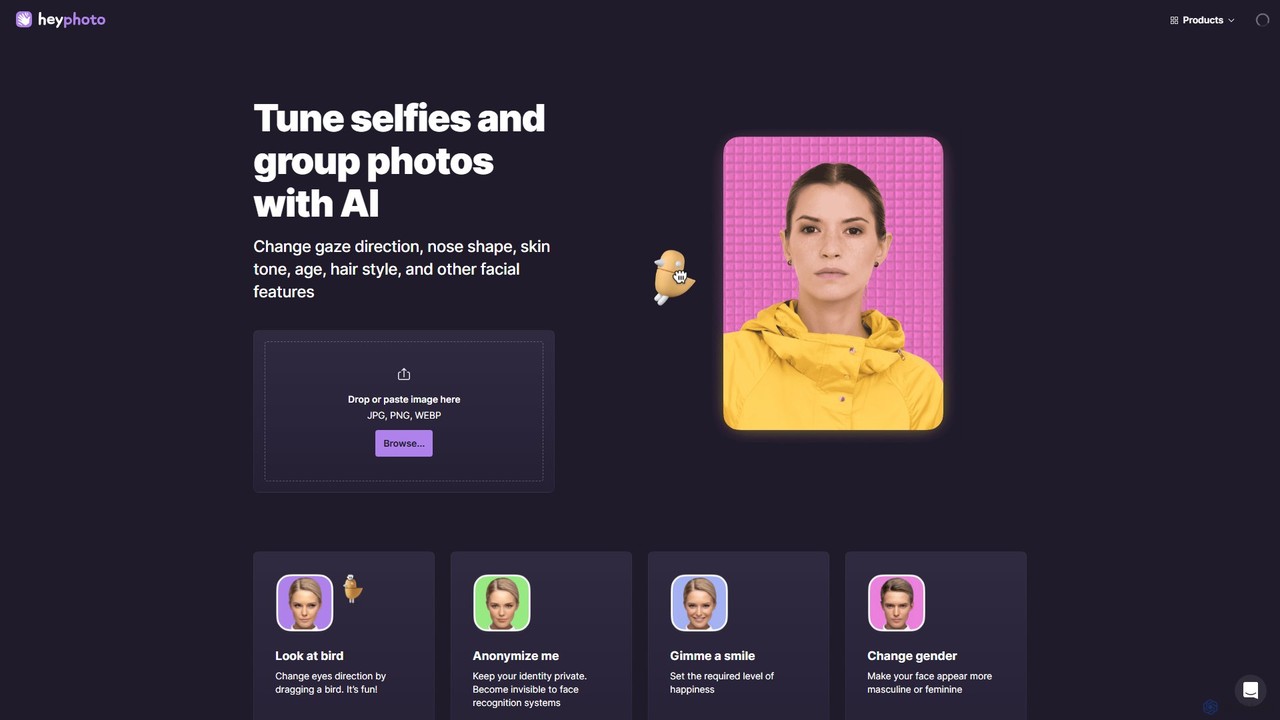
hey_photo ist ein Online-KI-Fotoeditor, der für die mühelose Bearbeitung von Gesichtszügen entwickelt wurde. Er ermöglicht es Benutzern, Ausdrücke, …
hey_photo ist ein Online-KI-Fotoeditor, der für die mühelose Bearbeitung von Gesichtszügen entwickelt wurde. Er ermöglicht es Benutzern, Ausdrücke, Alter, Geschlecht, Blickrichtung und andere Gesichtsmerkmale in Selfies und Gruppenfotos ohne komplexe Software einfach zu ändern. Er ist intuitiv, macht Spaß und ist kostenlos.
PiktID
PiktID ist eine umfassende KI-gestützte Bildbearbeitungssuite für Profis. Sie ist spezialisiert auf DSGVO-konforme Gesichtsanonymisierung, hochauflösenden Gesichtsaustausch, Fotoverbesserung und …
PiktID ist eine umfassende KI-gestützte Bildbearbeitungssuite für Profis. Sie ist spezialisiert auf DSGVO-konforme Gesichtsanonymisierung, hochauflösenden Gesichtsaustausch, Fotoverbesserung und Produktbildbearbeitung. Die Plattform bietet eine Reihe von Werkzeugen wie EraseID, SuperID und SwapID, um komplexe Bildverarbeitungsaufgaben zu automatisieren, Zeit und Kosten zu sparen und gleichzeitig Datenschutz und kreative Flexibilität zu gewährleisten.
Über Anonymisierung
Anonymisierungstools sind eine Klasse von KI-gestützten Softwarelösungen, die darauf ausgelegt sind, personenbezogene Daten (PII) aus Datensätzen zu entfernen oder zu verschleiern. Diese Tools verwenden fortschrittliche Techniken wie Datenmaskierung, Generalisierung und Pseudonymisierung, um sensible Daten so zu transformieren, dass sie nur schwer einer bestimmten Person zugeordnet werden können. Ihr Hauptwert liegt darin, Datenanalysen, -freigaben und Modelltraining zu ermöglichen und gleichzeitig Datenschutzbestimmungen wie die DSGVO und CCPA einzuhalten. Dieser Prozess ist ein entscheidender Bestandteil des Datenschutzes und konzentriert sich speziell darauf, Daten für eine sichere Nutzung unpersönlich zu machen.
Kernfunktionen
- PII-Erkennung: Scannt Datensätze automatisch, um sensible Informationen wie Namen, Adressen und Sozialversicherungsnummern zu identifizieren und zu klassifizieren.
- Datenmaskierung & Verschleierung: Ersetzt sensible Daten durch realistische, aber fiktive Informationen, wobei das Datenformat und die Nutzbarkeit für Tests oder Analysen erhalten bleiben.
- Pseudonymisierung: Ersetzt direkte Identifikatoren durch konsistente, aber nicht identifizierbare Token (Pseudonyme), was eine Datenverknüpfung ohne Offenlegung der Identität ermöglicht.
- Generalisierung & Unterdrückung: Reduziert die Genauigkeit von Daten (z. B. Umwandlung eines exakten Alters in eine Altersspanne) oder entfernt bestimmte Datensätze, um eine Re-Identifizierung durch einzigartige Kombinationen zu verhindern.
Anwendungsfälle
Anonymisierungstools sind in Sektoren, die mit sensiblen Informationen umgehen, unerlässlich. Im Gesundheitswesen ermöglichen sie die klinische Forschung mit Patientendaten, ohne die Vertraulichkeit zu gefährden. Finanzinstitute nutzen sie zur Analyse von Betrugsmustern in Transaktionsdaten. Technologieunternehmen wenden sie an, um sichere, realistische Datensätze für die Softwareentwicklung und -tests zu erstellen.
Wie man wählt
Bei der Auswahl eines Tools sollten Sie die unterstützten Anonymisierungstechniken (z. B. k-Anonymität, differentielle Privatsphäre) bewerten. Berücksichtigen Sie die Fähigkeit, verschiedene Datentypen (strukturiert, unstrukturiert, Bilder) zu verarbeiten, und die Integrationsmöglichkeiten in Ihre bestehenden Datenpipelines. Überprüfen Sie außerdem die Konformitätszertifizierungen für die in Ihrer Branche relevanten Vorschriften.
AnonymisierungAnwendungsfälle
Sicherung medizinischer Daten für die klinische Forschung
Medizinische Forscher und Datenwissenschaftler benötigen oft Zugang zu großen Patientendatensätzen, um Trends zu erkennen, Hypothesen zu testen und neue Behandlungen zu entwickeln. Die Verwendung von Rohdaten von Patienten birgt jedoch erhebliche Datenschutzrisiken und verstößt gegen Vorschriften wie HIPAA. Anonymisierungstools lösen dieses Problem, indem sie PII wie Namen, Patienten-IDs und genaue Adressen systematisch entfernen oder maskieren, während medizinisch relevante Informationen wie Diagnosen, Behandlungen und Ergebnisse erhalten bleiben. Dies ermöglicht es Forschern, mit reichhaltigen, realistischen Daten zu arbeiten und medizinische Durchbrüche zu beschleunigen, ohne die Vertraulichkeit der Patienten zu gefährden.
Erstellen sicherer Datensätze für Softwaretests
Softwareentwickler und QA-Ingenieure benötigen realistische Daten, um Anwendungen effektiv zu testen, insbesondere bei Funktionen, die Benutzerinformationen verarbeiten. Die Verwendung von Live-Produktionsdaten ist riskant und oft illegal. Anonymisierungstools erstellen sichere, konforme Testdatensätze, indem sie eine Kopie der Produktionsdaten nehmen und Techniken wie Datenmaskierung und -mischung anwenden. Dies stellt sicher, dass die Testdaten die Komplexität und die statistischen Eigenschaften der realen Daten beibehalten – was die Testgenauigkeit verbessert – aber keine tatsächlichen sensiblen Kundeninformationen enthalten, was gründliche Tests in Entwicklungs-, Staging- und Drittanbieterumgebungen ermöglicht.
Ermöglichen eines datenschutzkonformen KI-Modelltrainings
Ingenieure für maschinelles Lernen benötigen riesige Datenmengen, um robuste KI-Modelle zu trainieren. Wenn diese Daten PII enthalten, kann dies dazu führen, dass Modelle versehentlich sensible Informationen speichern und preisgeben, was erhebliche Datenschutz- und Sicherheitslücken schafft. Anonymisierungstools werden verwendet, um Trainingsdaten vorzuverarbeiten und PII zu entfernen oder umzuwandeln, bevor sie das Modell überhaupt erreichen. Dies ist besonders wichtig für Modelle in den Bereichen Finanzen, Gesundheitswesen und Kundenservice. Durch das Training mit anonymisierten Daten können Organisationen leistungsstarke und genaue KI-Systeme aufbauen, ohne das Risiko von Datenlecks oder Verstößen gegen Datenschutzgesetze einzugehen.
Analyse des Kundenverhaltens ohne Verletzung der Privatsphäre
Marketing- und Business-Intelligence-Teams analysieren Kundendaten, um Trends zu verstehen, Zielgruppen zu segmentieren und Erlebnisse zu personalisieren. Vorschriften wie die DSGVO und CCPA legen jedoch strenge Regeln dafür fest, wie personenbezogene Daten für Analysen verwendet werden dürfen. Anonymisierungstools ermöglichen es diesen Teams, eine „datenschutzsichere“ Version ihrer Kundendatenbank zu erstellen. Durch den Ersatz direkter Identifikatoren durch Pseudonyme und die Generalisierung sensibler Attribute wie des Standorts können Analysten leistungsstarke aggregierte Analysen durchführen und breite Verhaltensmuster erkennen, ohne auf die personenbezogenen Daten einzelner Personen zuzugreifen, was sowohl aufschlussreiche Analysen als auch die Einhaltung gesetzlicher Vorschriften gewährleistet.
Sicherer Datenaustausch mit Partnern und Dritten
Unternehmen müssen oft Daten mit externen Partnern für gemeinsame Projekte, Forschung oder Service-Integrationen teilen. Die Weitergabe von Rohdaten stellt eine erhebliche Sicherheitsverantwortung dar. Anonymisierungstools fungieren als sicheres Gateway für den Datenaustausch. Bevor Daten an Dritte übertragen werden, kann eine Organisation Anonymisierungsrichtlinien anwenden, um alle PII zu entfernen. Dies versorgt den Partner mit den notwendigen Daten zur Erfüllung seiner Funktion (z. B. Analyse von Markttrends) und stellt gleichzeitig sicher, dass keine sensiblen Kundeninformationen die Kontrolle der Organisation verlassen, wodurch das Risiko von Datenpannen durch Drittanbieter gemindert wird.
Veröffentlichung offener Daten für die öffentliche und akademische Nutzung
Regierungsbehörden, NGOs und akademische Einrichtungen veröffentlichen häufig Datensätze für öffentliche Transparenz und Forschung, wie z. B. Volkszählungsdaten, öffentliche Gesundheitsstatistiken oder Ergebnisse von Sozialumfragen. Um dies verantwortungsvoll zu tun, müssen alle persönlichen Identifikatoren entfernt werden, um die Privatsphäre der Bürger zu schützen. Anonymisierungstools sind für diesen Prozess von entscheidender Bedeutung. Sie wenden rigorose Techniken wie Generalisierung und differentielle Privatsphäre an, um sicherzustellen, dass Einzelpersonen auch bei öffentlicher Freigabe der Daten nicht aus dem Datensatz re-identifiziert werden können, selbst wenn sie mit anderen verfügbaren Informationen kombiniert werden. Dies fördert Open-Data-Initiativen und wahrt gleichzeitig ethische und rechtliche Datenschutzstandards.