LLMRTC
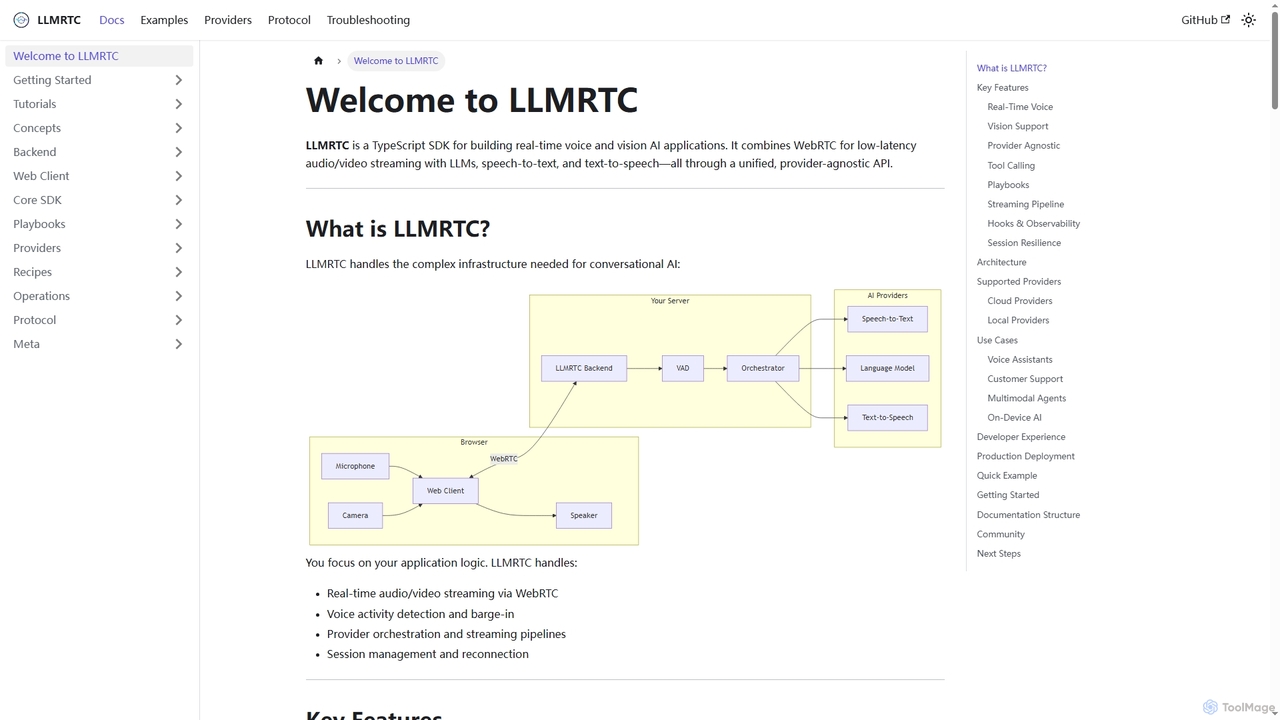
LLMRTC ist ein TypeScript SDK zum Erstellen von Echtzeit-Sprach- und Vision-KI-Anwendungen. Es kombiniert WebRTC für Audio-/Video-Streaming mit geringer …
LLMRTC ist ein TypeScript SDK zum Erstellen von Echtzeit-Sprach- und Vision-KI-Anwendungen. Es kombiniert WebRTC für Audio-/Video-Streaming mit geringer Latenz mit LLMs, Spracherkennung und Sprachsynthese – alles über eine einheitliche, providerunabhängige API. Entwickler können sich auf die Anwendungslogik konzentrieren, während LLMRTC die komplexe Infrastruktur für konversationelle KI übernimmt.
Noiz
Noiz ist eine fortschrittliche KI-Sprachplattform für Text-to-Speech, Stimmenklonung und sofortiges Video-Dubbing. Erstellen Sie lebensechte Stimmen, klonen Sie jede …
Noiz ist eine fortschrittliche KI-Sprachplattform für Text-to-Speech, Stimmenklonung und sofortiges Video-Dubbing. Erstellen Sie lebensechte Stimmen, klonen Sie jede Stimme aus einem 3-10 Sekunden langen Audioclip und übersetzen Sie Ihre Inhalte in mehrere Sprachen, während die ursprünglichen Stimmmerkmale erhalten bleiben. Ideal für Content-Ersteller, Vermarkter und Entwickler.
voiceisolator
Ein KI-gestütztes Online-Tool für hochwertige Stimmisolation, Hintergrundgeräusch-Entfernung und Stem-Separation aus Audio-/Videodateien. Es verfügt auch über einen vielseitigen Text-zu-Sprache …
Ein KI-gestütztes Online-Tool für hochwertige Stimmisolation, Hintergrundgeräusch-Entfernung und Stem-Separation aus Audio-/Videodateien. Es verfügt auch über einen vielseitigen Text-zu-Sprache (TTS)-Generator zur Erstellung natürlich klingender Voice-overs. Ideal für Musiker, Content-Ersteller und Video-Editoren.
CAMB.AI
CAMB.AI ist eine wegweisende KI-Lokalisierungsplattform für die Content-, Unterhaltungs- und Sportbranche. Sie bietet emotionserhaltende Synchronisation und Übersetzung in …
CAMB.AI ist eine wegweisende KI-Lokalisierungsplattform für die Content-, Unterhaltungs- und Sportbranche. Sie bietet emotionserhaltende Synchronisation und Übersetzung in Echtzeit in über 150 Sprachen. Große Partner wie IMAX und MLS vertrauen darauf und ermöglichen es Kreativen, ihre Inhalte weltweit zugänglich zu machen, während der ursprüngliche Ton und die Authentizität erhalten bleiben.
Altered
Altered ist eine professionelle KI-Stimmtechnologieplattform, die sowohl Echtzeit-Stimmveränderung als auch Postproduktions-Stimmbearbeitung anbietet. Mit seiner einzigartigen Speech-To-Speech-Morphing-Technologie können Benutzer …
Altered ist eine professionelle KI-Stimmtechnologieplattform, die sowohl Echtzeit-Stimmveränderung als auch Postproduktions-Stimmbearbeitung anbietet. Mit seiner einzigartigen Speech-To-Speech-Morphing-Technologie können Benutzer ihre Stimme in ein kuratiertes Portfolio ändern, jede Stimme klonen, Akzente ändern oder die Stimmklarheit wiederherstellen. Es richtet sich an Content-Ersteller, Gamer, Callcenter und Einzelpersonen, die eine Stimmmodifikation oder Schutz suchen.

neoformai
neoformai bietet fortschrittliche KI-Modelle für afrikanische Dialekte, einschließlich automatischer Spracherkennung (ASR) und Text-zu-Sprache (TTS). Es befähigt Entwickler und …
neoformai bietet fortschrittliche KI-Modelle für afrikanische Dialekte, einschließlich automatischer Spracherkennung (ASR) und Text-zu-Sprache (TTS). Es befähigt Entwickler und Unternehmen, inklusive Anwendungen zu erstellen, Sprachbarrieren zu überwinden und digitale Erlebnisse für Millionen in ganz Afrika zugänglich zu machen.
AudioPod
AudioPod ist ein professionelles KI-gestütztes Audio-Studio, das eine umfassende Suite von Werkzeugen für Kreative bietet. Es verfügt über …
AudioPod ist ein professionelles KI-gestütztes Audio-Studio, das eine umfassende Suite von Werkzeugen für Kreative bietet. Es verfügt über fortschrittliches Stimmenklonen, mehrsprachige Sprache-zu-Sprache-Übersetzung (KI-Synchronisation), hochpräzise Sprechertrennung, Musik-Stem-Splitting, Rauschunterdrückung und automatische Transkription. Es wurde entwickelt, um die Audio- und Videoproduktions-Workflows für Podcaster, Content-Ersteller, Musiker und Unternehmen zu optimieren und professionelle Audioverarbeitung zugänglich und effizient zu machen.
Über Text zu Sprache
Text-zu-Sprache (Text To Speech, TTS) Tools sind eine Klasse von KI-Software, die geschriebenen Text in natürlich klingende gesprochene Audiodaten umwandelt. Mithilfe von Deep-Learning-Modellen synthetisieren diese Tools menschenähnliche Stimmen und ermöglichen eine präzise Steuerung von Tonhöhe, Tonfall und Geschwindigkeit. Sie sind unerlässlich, um digitale Inhalte zugänglich zu machen, Audioversionen von Artikeln zu erstellen und Voiceover für Videos und Podcasts bereitzustellen. Moderne TTS-Technologie bietet eine breite Palette realistischer Stimmen, mehrere Sprachen und emotionale Ausdruckskraft, die weit über roboterhafte Ausgaben hinausgeht.
Kernfunktionen
- Mehrere Stimmen & Sprachen: Greifen Sie auf eine vielfältige Bibliothek von männlichen, weiblichen und Kinderstimmen in zahlreichen Sprachen und Akzenten zu.
- Stimmenanpassung: Passen Sie Sprachparameter wie Geschwindigkeit, Tonhöhe, Lautstärke an und fügen Sie Pausen für eine natürliche Wiedergabe hinzu.
- SSML-Unterstützung: Nutzen Sie die Speech Synthesis Markup Language (SSML) für eine feingranulare Kontrolle über Aussprache, Betonung und Intonation.
- Audio-Exportformate: Laden Sie das generierte Audio in gängigen Formaten wie MP3 und WAV für verschiedene Anwendungen herunter.
- API-Zugang: Integrieren Sie TTS-Funktionen direkt in Anwendungen und Websites zur Echtzeit-Audiogenerierung.
Anwendungsfälle
Diese Tools werden häufig von Content-Erstellern für Video-Voiceover, von Autoren für die Hörbuchproduktion und von Entwicklern zur Integration von Sprachfunktionen in Apps verwendet. Sie sind auch entscheidend im Unternehmenstraining für E-Learning-Module und im Kundenservice für dynamische IVR-Systeme.
Wie man wählt
Bei der Auswahl eines Text-zu-Sprache-Tools bewerten Sie zuerst die Stimmqualität und den Realismus. Berücksichtigen Sie die Auswahl an verfügbaren Sprachen und Akzenten. Beurteilen Sie den Grad der Anpassung und Kontrolle, wie z. B. die SSML-Unterstützung. Überprüfen Sie schließlich das Preismodell und die Verfügbarkeit einer API, falls Sie den Dienst in Ihre eigenen Produkte integrieren müssen.
Text zu SpracheAnwendungsfälle
Erstellung von Voiceovers für Videoinhalte
Ein Content-Ersteller oder Videomarketer benötigt ein konsistentes und professionelles Voiceover für eine Reihe von Erklärvideos, ohne die hohen Kosten eines Synchronsprechers. Er kann sein Skript in ein Text-zu-Sprache-Tool einfügen, eine passende Stimme und Sprache auswählen und die Wiedergabe durch Anpassen der Geschwindigkeit und Hinzufügen von Pausen verfeinern. Die endgültige Audiodatei wird als MP3-Datei exportiert und mit dem Videomaterial synchronisiert. Dieser Prozess reduziert die Produktionszeit und das Budget erheblich und ermöglicht eine schnellere Inhaltserstellung sowie einfache Aktualisierungen der Erzählung bei Skriptänderungen.
Entwicklung von E-Learning- und Schulungsmodulen
Ein Instruktionsdesigner erstellt einen Online-Kurs für eine globale Belegschaft. Um den Inhalt ansprechender und zugänglicher zu gestalten, verwendet er ein Text-zu-Sprache-Tool, um den Text auf dem Bildschirm zu erzählen. Durch die Verwendung einer API kann die Erzählung dynamisch generiert werden, wodurch sichergestellt wird, dass alle Aktualisierungen des Kursmaterials sofort im Audio widergespiegelt werden. Dieser Ansatz berücksichtigt unterschiedliche Lernstile, unterstützt Mitarbeiter mit Leseschwierigkeiten und erleichtert die Erstellung des Kurses in mehreren Sprachen durch einfache Auswahl verschiedener Stimmen, was das gesamte Lernerlebnis verbessert.
Produktion von Hörbüchern und Podcasts
Ein unabhängiger Autor möchte sein E-Book in ein Hörbuch umwandeln, um ein breiteres Publikum zu erreichen, hat aber nicht das Budget für ein professionelles Aufnahmestudio. Mit einem Text-zu-Sprache-Generator kann er sein gesamtes Manuskript hochladen, eine Erzählerstimme auswählen, die zum Ton des Buches passt, und hochwertige Audiodateien für jedes Kapitel erstellen. Dies ermöglicht ihm, auf Plattformen wie Audible oder Spotify zu einem Bruchteil der herkömmlichen Kosten zu veröffentlichen. In ähnlicher Weise kann ein Podcaster TTS verwenden, um konsistente Intros, Outros oder sogar Sprachsegmente für verschiedene Charaktere in einer narrativen Show zu erstellen.
Verbesserung der Zugänglichkeit von Websites und Artikeln
Ein digitaler Verlag oder eine Nachrichtenorganisation möchte ihre Online-Artikel für Benutzer mit Sehbehinderungen oder Leseschwächen zugänglich machen und die WCAG-Standards einhalten. Sie können ein Text-zu-Sprache-Widget auf ihrer Website integrieren. Dies ermöglicht es den Besuchern, auf einen „Anhören“-Button zu klicken, der den Text des Artikels sofort in hochwertiges Audio umwandelt. Dies verbessert nicht nur die Zugänglichkeit und die Benutzererfahrung, sondern spricht auch Benutzer an, die Inhalte lieber auditiv konsumieren, z. B. beim Pendeln oder Multitasking. Es erweitert die Reichweite der Website und zeigt ein Engagement für Inklusivität.
Prototyping von Sprachbenutzeroberflächen (VUI)
Ein UX-Designer oder App-Entwickler erstellt eine sprachgesteuerte Anwendung, wie einen intelligenten Assistenten oder ein Navigationssystem im Auto. Anstatt Platzhalter-Audio aufzunehmen, verwenden sie ein Text-zu-Sprache-Tool, um schnell Sprachantworten für ihren Prototyp zu generieren. Dies ermöglicht es ihnen, verschiedene Phrasen, Töne und Reaktionszeiten in einer realistischen Benutzertestumgebung zu testen. Die Möglichkeit, den Text sofort zu ändern und das Audio neu zu generieren, macht den Design-Iterationsprozess schnell und kostengünstig, was zu einer ausgefeilteren und benutzerfreundlicheren endgültigen Sprachoberfläche führt.
Automatisierung des Kundenservice mit IVR-Systemen
Ein Callcenter-Manager muss das interaktive Sprachdialogsystem (IVR) seines Unternehmens mit neuen Menüoptionen und Werbebotschaften aktualisieren. Anstatt für jede kleine Änderung einen Synchronsprecher zu engagieren, nutzt er einen Text-zu-Sprache-Dienst. Er gibt einfach die neuen Ansagen ein, wie z. B. „Unsere Geschäftszeiten haben sich geändert“, und generiert eine klare, professionelle Audiodatei. Dies stellt sicher, dass das Telefonsystem des Unternehmens immer über aktuelle Informationen verfügt und eine konsistente Markenstimme beibehält, während im Vergleich zu manuellen Aufnahmesitzungen erheblich Zeit und Ressourcen gespart werden.