Serendpt AI
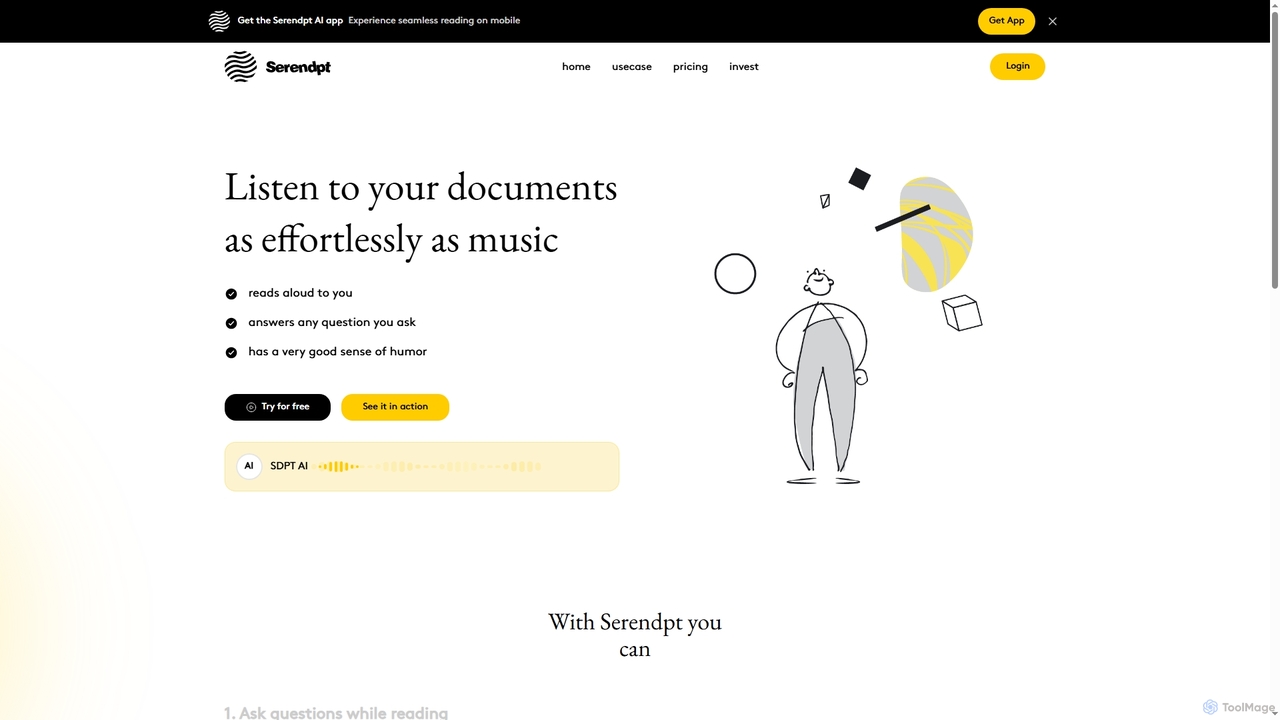
Serendpt AI ist ein intelligenter Lesebegleiter, der Dokumente und Bücher in interaktive Erlebnisse verwandelt. Er liest Inhalte laut …
Serendpt AI ist ein intelligenter Lesebegleiter, der Dokumente und Bücher in interaktive Erlebnisse verwandelt. Er liest Inhalte laut vor, beantwortet Fragen sofort und bietet einen personalisierten Tutorenmodus, alles über eine mobile App zugänglich.
ZenMic
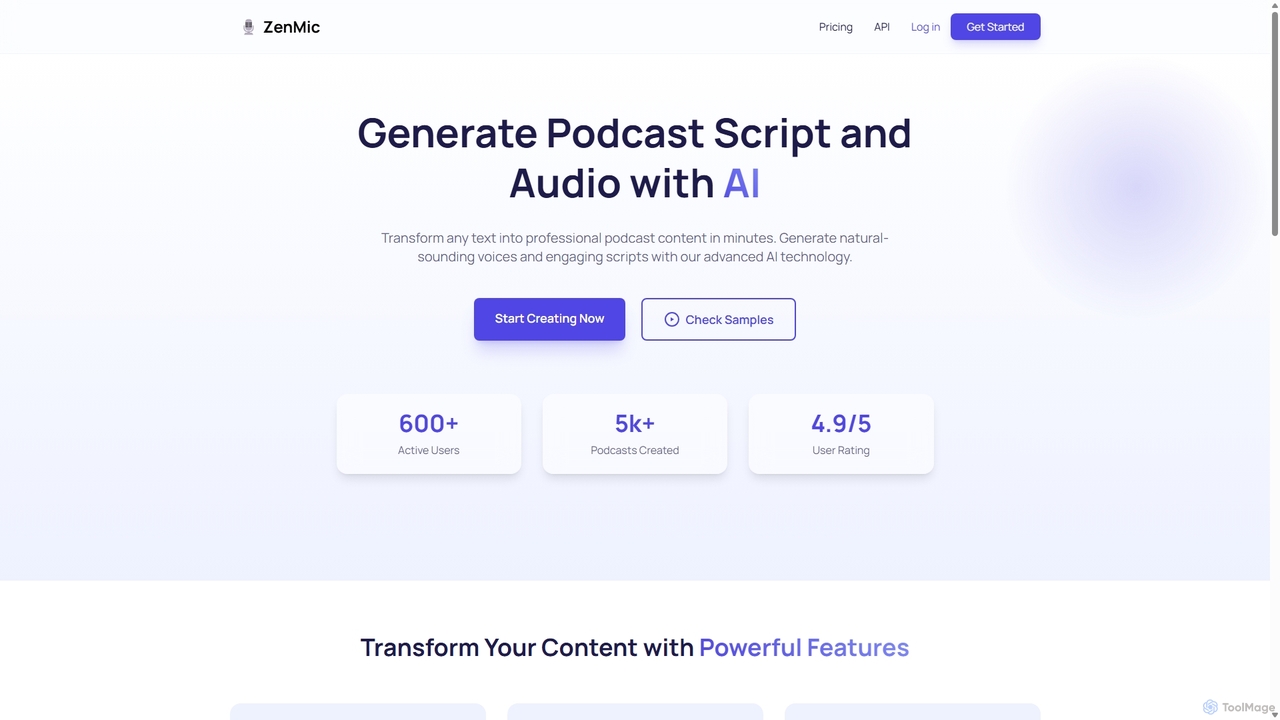
ZenMic ist ein KI-gestützter Podcast-Generator, der jeden Text in wenigen Minuten in professionelle Podcast-Episoden umwandelt. Er automatisiert den …
ZenMic ist ein KI-gestützter Podcast-Generator, der jeden Text in wenigen Minuten in professionelle Podcast-Episoden umwandelt. Er automatisiert den gesamten Prozess, von der Erstellung ansprechender Skripte basierend auf Ihrem Thema oder Inhalt bis hin zur Produktion von natürlich klingendem Audio mit fortschrittlichen KI-Stimmen. Ideal für Content-Ersteller, Vermarkter und Pädagogen, die schriftliches Material mühelos in ein Audioformat umwandeln möchten. ZenMic vereinfacht die Podcast-Produktion und macht sie für jeden zugänglich, ohne dass technische Fähigkeiten oder Aufnahmeausrüstung erforderlich sind.
AIdeaFlow AI Podcast Generator
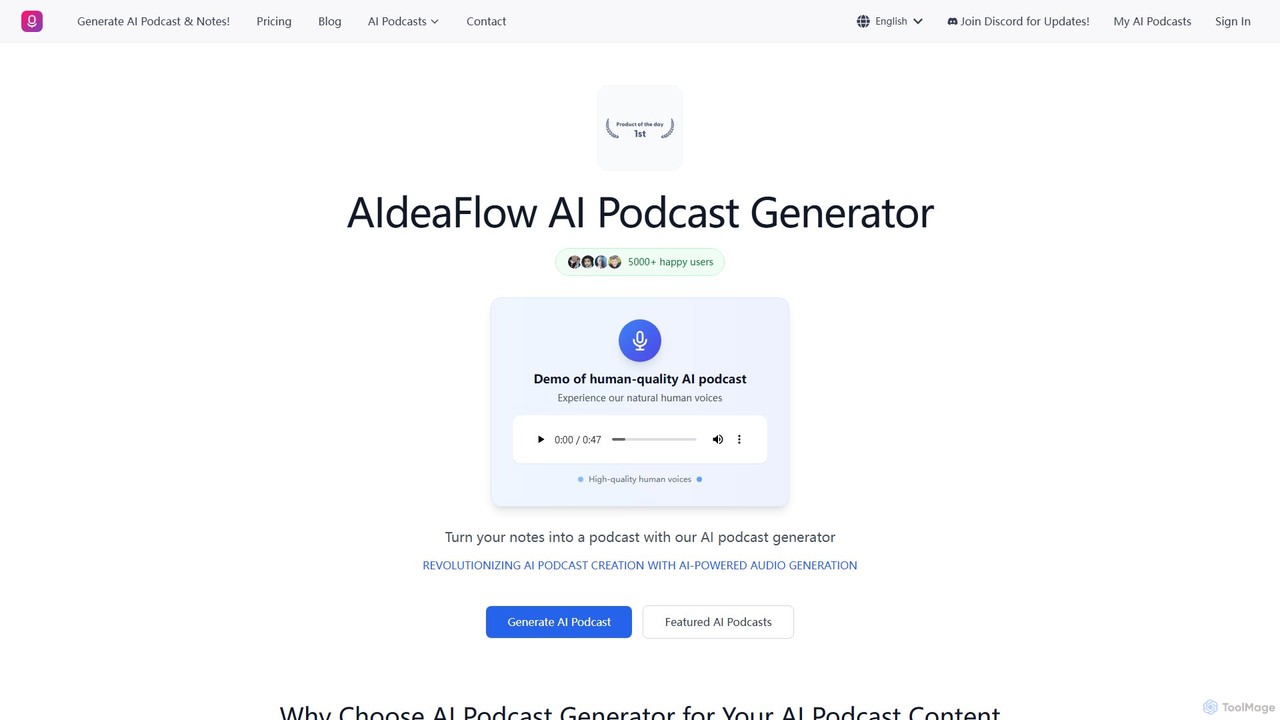
Ein fortschrittliches KI-Tool, das jeden Text in ansprechende Dialog-Podcasts mit mehreren Sprechern umwandelt. Es bietet über 120 natürliche …
Ein fortschrittliches KI-Tool, das jeden Text in ansprechende Dialog-Podcasts mit mehreren Sprechern umwandelt. Es bietet über 120 natürliche Stimmen, unterstützt über 50 Sprachen und ermöglicht tiefgreifende Anpassungen. Ideal für Content-Ersteller, Pädagogen und Vermarkter, um mühelos hochwertige Audioinhalte zu produzieren.
aiclonevoicefree
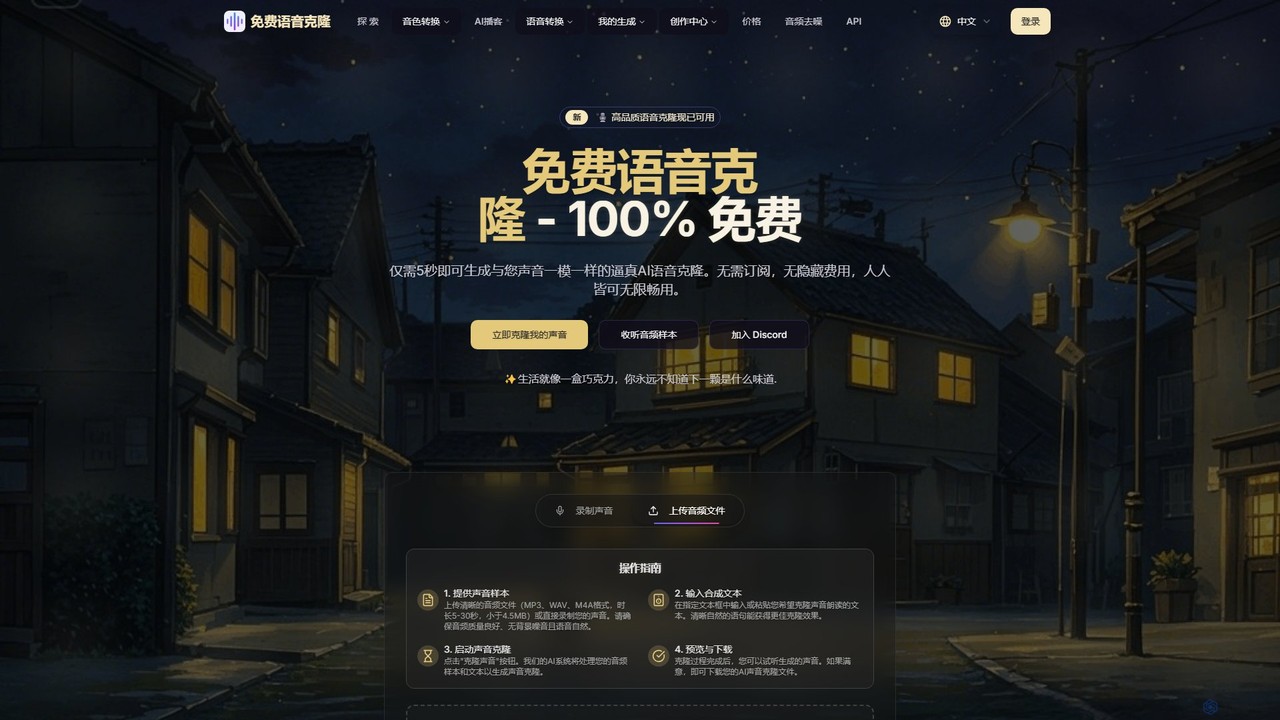
aiclonevoicefree ist ein Freemium-KI-Tool zum Klonen von Stimmen, das realistische Stimmrepliken aus kurzen Audio-Samples (5-30 Sekunden) erzeugt. Es …
aiclonevoicefree ist ein Freemium-KI-Tool zum Klonen von Stimmen, das realistische Stimmrepliken aus kurzen Audio-Samples (5-30 Sekunden) erzeugt. Es bietet hochwertige Text-to-Speech (TTS)-Synthese, unterstützt sprachübergreifendes Klonen und stellt eine Bibliothek mit vorgefertigten Charakterstimmen zur Verfügung. Die kostenlose Version erfordert keine Registrierung und macht fortschrittliche Sprachtechnologie für jeden für persönliche Projekte und die Erstellung von Inhalten zugänglich.
Über Text zu Sprache
Text-zu-Sprache (TTS)-Tools sind KI-gestützte Anwendungen, die geschriebenen Text in natürlich klingende gesprochene Audiodaten umwandeln. Diese Tools nutzen fortschrittliche neuronale Netze und Deep-Learning-Modelle, um menschenähnliche Stimmen mit realistischer Intonation und Emotion zu synthetisieren. Sie werden häufig zur Erstellung von Audioinhalten, zur Verbesserung der Zugänglichkeit digitaler Materialien und zur Erzeugung professioneller Voice-overs ohne Aufnahmegeräte eingesetzt. Moderne TTS-Plattformen bieten eine riesige Auswahl an Stimmen, Sprachen und Akzenten und liefern hochwertige Audioausgaben für vielfältige Anforderungen.
Kernfunktionen
- Umfangreiche Stimmenbibliothek: Zugriff auf eine breite Palette vorgefertigter männlicher, weiblicher und Kinderstimmen in zahlreichen Sprachen und Akzenten.
- Stimmenanpassung & Steuerung: Anpassung von Parametern wie Sprechgeschwindigkeit, Tonhöhe, Lautstärke und Pausen zur Feinabstimmung der Audioausgabe.
- Emotionale Töne: Erzeugung von Sprache mit spezifischen Emotionen wie fröhlich, traurig oder aufgeregt, um dem Kontext des Textes zu entsprechen.
- SSML-Unterstützung: Nutzung der Speech Synthesis Markup Language (SSML) für eine erweiterte Kontrolle über Aussprache, Betonung und Sprachfluss.
Anwendungsfälle
Diese Tools sind wertvoll für Content-Ersteller, die Videokommentare und Podcasts produzieren, für Pädagogen, die E-Learning-Kurse entwickeln, und für Unternehmen, die automatisierte Sprachansagen für IVR-Systeme erstellen. Entwickler integrieren auch TTS-APIs, um Anwendungen und Diensten Sprachfunktionen hinzuzufügen.
Wie man wählt
Bei der Auswahl eines Text-zu-Sprache-Tools bewerten Sie die Natürlichkeit und Qualität der Stimmen. Berücksichtigen Sie die Breite der Sprach- und Akzentunterstützung, den Grad der verfügbaren Anpassung (einschließlich SSML), den API-Zugang für die Integration und die Preisstruktur basierend auf der Zeichennutzung oder einem Abonnement.
Text zu SpracheAnwendungsfälle
Erstellung von Voice-overs für Videoinhalte
Ein Content-Ersteller muss ein YouTube-Video im Dokumentarstil produzieren, verfügt aber nicht über professionelle Aufnahmeausrüstung oder eine geeignete Stimme. Mit einem Text-zu-Sprache-Tool kann er sein Skript in den Editor einfügen, eine tiefe, autoritäre Stimme aus der Bibliothek auswählen und das Tempo an die visuellen Elemente des Videos anpassen. Das Tool generiert eine hochwertige MP3-Audiodatei, die direkt in seine Videobearbeitungssoftware importiert werden kann, was Stunden an Aufnahme- und Bearbeitungszeit spart und eine konsistente, professionelle Erzählung gewährleistet.
Entwicklung barrierefreier E-Learning-Materialien
Ein Instruktionsdesigner in einem Unternehmen hat die Aufgabe, Schulungsmodule für Mitarbeiter mit Sehbehinderungen zugänglich zu machen und auditive Lerner anzusprechen. Er verwendet ein TTS-Tool mit API-Zugang, um alle schriftlichen Kursinhalte – von Folientexten bis hin zu Quizfragen – automatisch in ein Audioformat umzuwandeln. Dies ermöglicht es den Lernenden, das Material unterwegs anzuhören, was das Engagement verbessert und die Einhaltung von Barrierefreiheitsstandards gewährleistet, ohne Hunderte von Textseiten manuell aufnehmen zu müssen.
Automatisierung der Podcast-Produktion
Ein Solo-Podcaster, der Blog-Artikel in Audio-Episoden umwandelt, möchte seine Produktion steigern. Anstatt Stunden mit der Aufnahme jedes Artikels zu verbringen, verwendet er ein TTS-Tool mit einer natürlichen, gesprächigen Stimme. Er kann einen 2.000-Wörter-Artikel schnell in ein 15-minütiges Audiosegment umwandeln. Durch die Verwendung von SSML-Tags kann er strategische Pausen hinzufügen und wichtige Punkte betonen, was ein ausgefeiltes Hörerlebnis schafft, das der menschlichen Erzählung sehr nahe kommt und es ihm ermöglicht, täglich neue Episoden zu veröffentlichen.
Erstellung von IVR-Ansagen für den Kundenservice
Ein Telekommunikationsunternehmen muss sein interaktives Sprachdialogsystem (IVR) mit neuen Menüoptionen und Werbebotschaften aktualisieren. Anstatt für kleine Aktualisierungen Sprecher zu engagieren, verwendet der Systemadministrator ein TTS-Tool. Er gibt die neuen Ansagen ein, wie z. B. „Drücken Sie die 5 für unsere neuen Glasfaser-Tarife“, und generiert klare, konsistente Audiodateien mit einer freundlichen, professionellen Stimme. Dieser Prozess reduziert die Bearbeitungszeit von Wochen auf Minuten und stellt sicher, dass alle Systemansagen einen einheitlichen Klang haben.
Prototyping von Hörbüchern für Autoren
Ein unabhängiger Autor möchte einschätzen, wie sich sein neuer Roman als Hörbuch anhört, bevor er in einen professionellen Sprecher investiert. Er lädt ein Kapitel seines Manuskripts in ein TTS-Tool hoch und wählt eine Stimme, die zum Charakter seines Protagonisten passt. Das Anhören des KI-generierten Audios hilft ihm, umständliche Formulierungen, sich wiederholende Sätze und Tempoprobleme in seinem Dialog zu erkennen. Dies ermöglicht es ihm, den Text für einen besseren auditiven Fluss zu verfeinern und ein stärkeres Manuskript für die endgültige, von Menschen erzählte Produktion zu erstellen.
Hinzufügen von Echtzeit-Erzählungen zu Anwendungen
Ein Entwickler mobiler Apps erstellt eine Sprachlern-App und muss Audio-Aussprachen für Tausende von Wörtern und Phrasen bereitstellen. Jede einzelne manuell aufzunehmen ist unpraktisch. Er integriert eine TTS-API in seine App. Wenn ein Benutzer auf ein Wort tippt, sendet die App eine Anfrage an die API, die sofort einen hochwertigen Audiostream der korrekten Aussprache in der ausgewählten Sprache und dem ausgewählten Akzent zurückgibt. Dies bietet eine skalierbare und kostengünstige Lösung zum Hinzufügen kritischer Audiofunktionen.