VoiceOS
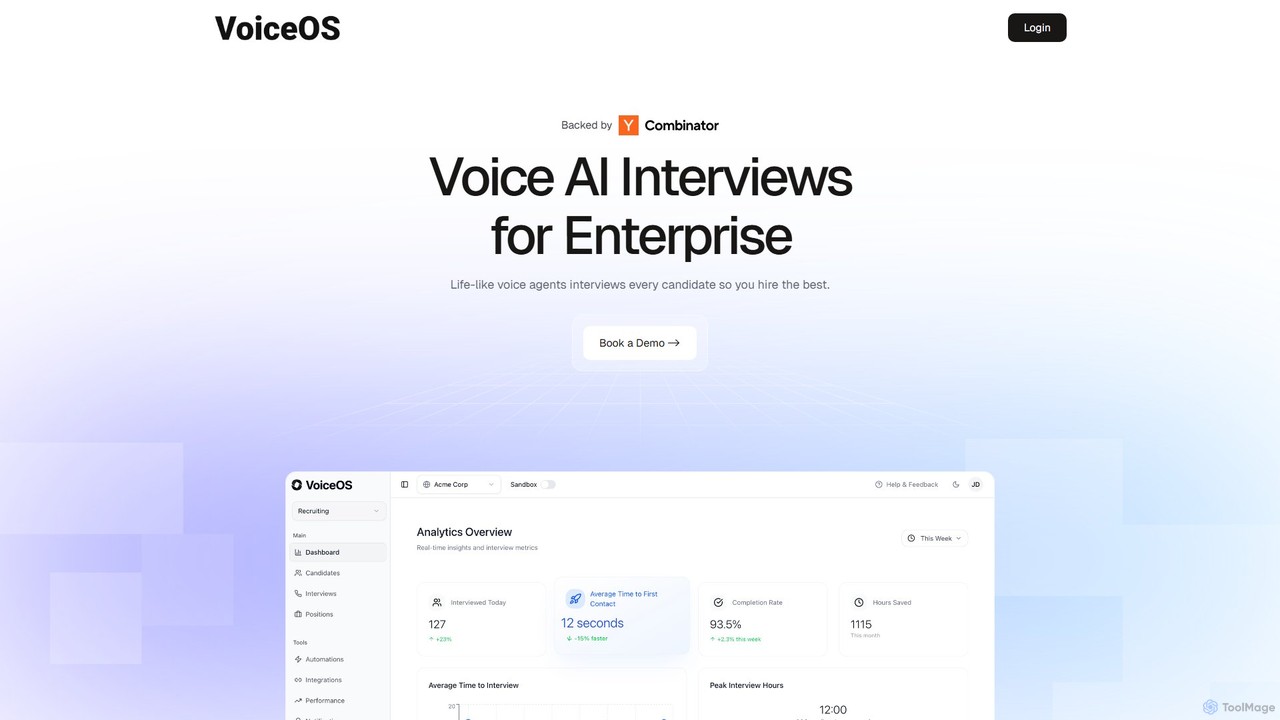
VoiceOS ist eine KI-gestützte Plattform für Unternehmen, die die Vorauswahl von Kandidaten durch lebensechte Sprachinterviews automatisiert. Es integriert …
VoiceOS ist eine KI-gestützte Plattform für Unternehmen, die die Vorauswahl von Kandidaten durch lebensechte Sprachinterviews automatisiert. Es integriert sich in jedes ATS, führt rund um die Uhr Interviews durch und liefert erweiterte Analysen zu Stimmung, kultureller Passung und Erfahrung. Dies optimiert die Personalbeschaffung in großem Umfang, reduziert Voreingenommenheit und ermöglicht es den Einstellungsteams, sich auf die qualifiziertesten Bewerber zu konzentrieren, was den Einstellungsprozess beschleunigt.
Über Stimme & Sprache
Stimme & Sprache-Tools sind KI-gestützte Lösungen, die menschliche Sprache erzeugen, umwandeln und analysieren. Diese Tools nutzen Kerntechnologien wie Text-to-Speech (TTS), um Audio aus Text zu erstellen, und Speech-to-Text (STT), um gesprochene Worte in schriftliche Form zu transkribieren. Sie werden weithin eingesetzt, um realistische Voiceovers zu erstellen, Transkriptionen zu automatisieren, Sprachassistenten zu entwickeln und die Barrierefreiheit zu verbessern. Die Fähigkeit, Nuancen in Ton, Akzent und Emotion zu verarbeiten und zu replizieren, macht sie äußerst effektiv für Kommunikation und Inhaltserstellung.
Kernfunktionen
- Text-to-Speech (TTS): Wandelt geschriebenen Text in natürlich klingendes, menschenähnliches gesprochenes Audio in verschiedenen Sprachen und Stimmen um.
- Speech-to-Text (STT) / Transkription: Transkribiert gesprochene Sprache aus Audio- oder Videodateien präzise in durchsuchbaren, bearbeitbaren Text.
- Stimmklonung: Erstellt eine digitale Replik einer bestimmten Stimme aus einer kurzen Audio-Probe, was die Erzeugung neuer Sprache in dieser Stimme ermöglicht.
- Spracherkennung: Identifiziert und interpretiert gesprochene Befehle oder authentifiziert Benutzer anhand ihrer einzigartigen stimmlichen Merkmale.
- Sprachanalyse: Analysiert Audiogespräche, um Einblicke in Stimmung, Schlüsselwörter, Tonfall und Sprecherleistung zu gewinnen.
Anwendungsfälle
Diese Tools sind in Branchen wie Medien und Unterhaltung für die Voiceover-Produktion, im Kundenservice für den Aufbau von interaktiven Sprachdialogsystemen (IVR) und im Gesundheitswesen für die klinische Dokumentation unerlässlich. Content-Ersteller, Podcaster, Vermarkter, Entwickler und Forscher nutzen sie, um Arbeitsabläufe zu automatisieren, barrierefreie Inhalte zu erstellen und gesprochene Daten zu analysieren.
Wie man wählt
Bei der Auswahl eines Stimme & Sprache-Tools bewerten Sie die Natürlichkeit und Qualität der erzeugten Stimme oder die Genauigkeit der Transkription. Berücksichtigen Sie die Bandbreite der unterstützten Sprachen, Dialekte und Akzente. Für Entwickler sind die Verfügbarkeit und Dokumentation einer API entscheidend. Bewerten Sie auch Anpassungsoptionen wie Stimmklonung, Geschwindigkeitsanpassung und Preismodelle, die auf Zeichen, Minuten oder Abonnementstufen basieren.
Stimme & SpracheAnwendungsfälle
Erstellung realistischer Voiceovers für Videoinhalte
Ein Videoersteller oder Vermarkter muss ein Werbevideo in mehreren Sprachen produzieren, hat aber nicht das Budget für professionelle Sprecher. Durch die Verwendung eines Text-to-Speech (TTS)-Tools können sie ihr Skript eingeben und hochwertiges, natürlich klingendes Audio für jede erforderliche Sprache generieren. Dieser Prozess ermöglicht es ihnen, Ton, Geschwindigkeit und Emotion an den Kontext des Videos anzupassen. Das Ergebnis sind professionell lokalisierte Videoinhalte, die schnell und kostengünstig produziert werden und es ihnen ermöglichen, ein globales Publikum ohne erhebliche Investitionen in Aufnahmestudios oder Talente zu erreichen.
Automatisierung der Transkription von Meetings und Interviews
Ein Journalist, Forscher oder Projektmanager, der täglich mehrere Interviews oder Meetings durchführt, benötigt genaue schriftliche Aufzeichnungen zur Analyse. Das manuelle Transkribieren von stundenlangem Audiomaterial ist zeitaufwändig und fehleranfällig. Durch das Hochladen von Audioaufnahmen in ein Speech-to-Text (STT)-Tool erhalten sie innerhalb von Minuten ein automatisiertes, mit Zeitstempeln versehenes Transkript. Viele Tools können auch zwischen verschiedenen Sprechern unterscheiden. Diese Automatisierung spart Stunden manueller Arbeit, beschleunigt den Prozess der Inhaltserstellung oder Forschung und liefert ein durchsuchbares Textdokument zur einfachen Referenz und Datenextraktion.
Entwicklung von interaktiven Sprachdialogsystemen (IVR)
Ein Kundendienstleiter möchte die Effizienz des Callcenters durch die Automatisierung häufiger Anfragen verbessern. Mithilfe von Spracherkennungs- und TTS-Tools können Entwickler ein interaktives Sprachdialogsystem (IVR) erstellen. Das System verwendet Spracherkennung, um die mündliche Anfrage eines Kunden zu verstehen (z. B. „meinen Kontostand prüfen“). Anschließend verarbeitet es die Anfrage und verwendet TTS, um eine klare, gesprochene Antwort zu geben. Dies entlastet menschliche Agenten, die sich um komplexere Probleme kümmern können, reduziert die Wartezeiten der Kunden und bietet rund um die Uhr Support, was letztendlich die allgemeine Kundenzufriedenheit und die betriebliche Effizienz verbessert.
Erstellung von Hörbüchern und Podcast-Inhalten
Ein Autor oder Verleger möchte ein geschriebenes Buch in ein Hörbuch umwandeln, um ein breiteres Publikum zu erreichen. Anstatt der hohen Kosten und des Zeitaufwands für die Anstellung eines Sprechers und die Buchung eines Studios können sie ein hochwertiges TTS-Tool verwenden. Durch die Eingabe des Buchtextes können sie den gesamten Audioinhalt mit einer ausdrucksstarken, konsistenten KI-Stimme generieren. In ähnlicher Weise kann ein Podcaster TTS verwenden, um Segmente, Einführungen oder sogar ganze Episoden mit einer synthetischen Stimme zu erstellen, was eine schnelle Inhaltsproduktion und das Experimentieren mit verschiedenen Stimmstilen ermöglicht, ohne die eigene Stimme aufnehmen zu müssen.
Personalisierung der Markenstimme durch Stimmklonung
Ein Marketingdirektor möchte eine einzigartige und konsistente Audio-Identität für seine Marke auf allen Plattformen etablieren, von Werbung bis hin zu In-App-Assistenten. Anstatt sich auf generische Standardstimmen zu verlassen, können sie ein Stimmklonungstool verwenden. Durch die Bereitstellung einer kurzen, hochwertigen Aufnahme eines ausgewählten Sprechers erstellt das Tool ein benutzerdefiniertes KI-Stimmmodell. Dieses Modell kann dann verwendet werden, um neue Audioinhalte zu generieren, wodurch sichergestellt wird, dass jede Markennachricht in derselben wiedererkennbaren und proprietären Stimme übermittelt wird. Dies verbessert die Markenerinnerung und schafft eine persönlichere Verbindung zum Publikum.
Verbesserung der Barrierefreiheit für sehbehinderte Benutzer
Ein Webentwickler oder Content-Ersteller muss seine digitalen Inhalte, wie Artikel und Lehrmaterialien, für Benutzer mit Sehbehinderungen zugänglich machen. Durch die Integration einer Text-to-Speech (TTS)-API können sie ihrer Website oder Anwendung eine „Vorlese“-Funktion hinzufügen. Dies ermöglicht es den Benutzern, den Text auf dem Bildschirm anzuhören, anstatt ihn zu lesen. Dies hilft nicht nur bei der Einhaltung von Barrierefreiheitsstandards wie WCAG, sondern bietet auch eine inklusivere Benutzererfahrung und stellt sicher, dass wertvolle Informationen für jeden zugänglich sind, unabhängig von seinen visuellen Fähigkeiten.