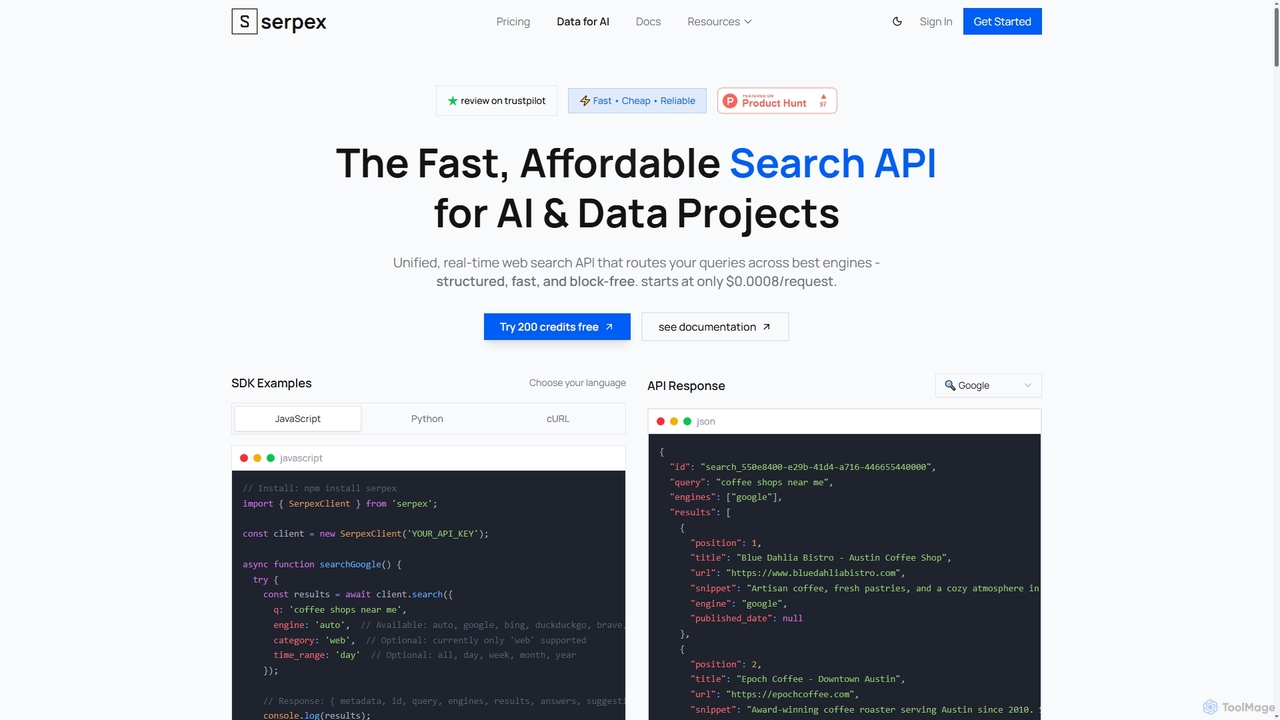
Serpex
Serpex es una API de búsqueda rápida, asequible y confiable diseñada para proyectos de IA y datos. Proporciona …
Serpex es una API de búsqueda rápida, asequible y confiable diseñada para proyectos de IA y datos. Proporciona resultados de búsqueda web estructurados y en tiempo real de múltiples motores de búsqueda principales, superando desafíos comunes como CAPTCHAs y bloqueos geográficos.
Acerca de Fuente de Datos
Las herramientas de Fuente de Datos son plataformas y servicios que proporcionan conjuntos de datos curados y de alta calidad, esenciales para entrenar, validar y probar modelos de IA. Estas herramientas ofrecen acceso a una amplia gama de tipos de datos, incluyendo imágenes, texto, audio y datos estructurados, a menudo preprocesados y anotados para acelerar los flujos de trabajo de aprendizaje automático. Son un componente fundamental del desarrollo de IA, permitiendo a desarrolladores e investigadores construir sistemas robustos y precisos sin el costo y tiempo prohibitivos de recolectar y etiquetar datos desde cero. Al proporcionar conjuntos de datos listos para usar o personalizables, estas herramientas reducen significativamente la barrera de entrada para crear aplicaciones de IA sofisticadas.
Características Clave
- Bibliotecas de Conjuntos de Datos Diversos: Acceso a extensas colecciones de conjuntos de datos preexistentes y etiquetados en diversos dominios como visión por computadora y PNL.
- Generación de Datos Sintéticos: Capacidad para crear datos artificiales para aumentar conjuntos de datos del mundo real, cubrir casos extremos o proteger la privacidad.
- Servicios de Anotación de Datos: Servicios integrados o asociados para etiquetar datos brutos y hacerlos adecuados para modelos de aprendizaje supervisado.
- Calidad y Versionado de Datos: Funciones para garantizar la consistencia de los datos, gestionar diferentes versiones de conjuntos de datos y rastrear la procedencia de los datos para la reproducibilidad.
- Acceso a API y SDK: Acceso programático para descargar, transmitir y gestionar conjuntos de datos directamente en los entornos de desarrollo.
Casos de Uso
Las herramientas de Fuente de Datos son críticas para Ingenieros de Aprendizaje Automático, Científicos de Datos e Investigadores de IA. Se utilizan para entrenar modelos de visión por computadora para la detección de objetos, desarrollar aplicaciones de procesamiento de lenguaje natural con grandes corpus de texto y comparar el rendimiento de nuevos algoritmos con los estándares establecidos de la industria. Estas herramientas son invaluables en sectores como vehículos autónomos, atención médica para el análisis de imágenes médicas y finanzas para el modelado de detección de fraudes.
Cómo Elegir
Al seleccionar una herramienta de Fuente de Datos, considere la relevancia y calidad de los conjuntos de datos para su problema específico. Evalúe las licencias y los derechos de uso para asegurarse de que se alineen con los objetivos comerciales o de investigación de su proyecto. Analice la facilidad de integración a través de APIs y las características de gestión de datos de la plataforma, como el versionado. Finalmente, compare los modelos de precios, ya sean de código abierto, basados en suscripción o de pago por uso, para encontrar una solución que se ajuste a su presupuesto y escala de proyecto.
Fuente de DatosEscenario de uso
Entrenamiento de un modelo de visión por computadora para conducción autónoma
Una startup de IA que desarrolla sistemas de percepción para vehículos autónomos necesita un conjunto de datos vasto y diverso de escenas de carretera. En lugar de gastar meses y un capital significativo en la recolección y anotación manual de imágenes, su equipo de ML utiliza una plataforma de Fuente de Datos. Acceden a un conjunto de datos pre-etiquetado con millones de imágenes que contienen peatones, vehículos y señales de tráfico. Esto les permite entrenar e iterar rápidamente en sus modelos de detección de objetos, acelerando significativamente su ciclo de desarrollo y mejorando la precisión del modelo en casos extremos críticos.
Ajuste fino de un modelo de PNL para soporte al cliente
Una empresa quiere construir un chatbot especializado para su soporte técnico. Los modelos de lenguaje de propósito general carecen de la jerga específica y el contexto de resolución de problemas de su industria. Un científico de datos del equipo utiliza una herramienta de Fuente de Datos para adquirir un gran corpus de conversaciones y documentación de soporte técnico anonimizadas. Al ajustar su modelo de lenguaje base con estos datos específicos del dominio, crean un chatbot que entiende los problemas de los usuarios con alta precisión y proporciona soluciones relevantes, reduciendo la carga de trabajo de los agentes humanos.
Generación de datos sintéticos para imágenes médicas
Un instituto de investigación está desarrollando un modelo de IA para detectar una enfermedad rara a partir de escáneres de resonancia magnética. Debido a la privacidad del paciente y la escasez de casos, tienen un conjunto de datos muy pequeño, lo que conduce al sobreajuste del modelo. El equipo de investigación utiliza una herramienta de Fuente de Datos con capacidades de generación de datos sintéticos. Generan miles de escáneres de resonancia magnética realistas, pero artificiales, que muestran diversas etapas de la enfermedad. Este conjunto de datos aumentado les permite entrenar un modelo más robusto y generalizado, mejorando significativamente su precisión diagnóstica sin comprometer la confidencialidad del paciente.
Evaluación comparativa de un nuevo algoritmo de recomendación
El equipo de ciencia de datos de una empresa de comercio electrónico ha desarrollado un novedoso algoritmo de recomendación. Para demostrar su eficacia, necesitan compararlo con los métodos existentes en un conjunto de datos estandarizado. Utilizan un centro de Fuentes de Datos para descargar conjuntos de datos públicos conocidos como MovieLens o Amazon Reviews. Esto les permite realizar un experimento justo y reproducible, midiendo métricas como la precisión y el recall. Los resultados, evaluados en un conjunto de datos público, proporcionan una base creíble para decidir si implementar el nuevo algoritmo en producción.
Entrenamiento de un modelo de detección de fraude con datos transaccionales
Una empresa fintech tiene como objetivo mejorar su sistema de detección de fraude en tiempo real. Sus datos internos son limitados y pueden no cubrir patrones fraudulentos emergentes. Se suscriben a un servicio de Fuente de Datos que proporciona conjuntos de datos transaccionales grandes, anonimizados y actualizados regularmente. Al entrenar sus modelos de aprendizaje automático con estos datos extensos, pueden identificar correlaciones sutiles y anomalías indicativas de fraude de manera más efectiva. Este acceso a datos externos permite que su sistema se mantenga a la vanguardia de las amenazas en evolución y reduzca las pérdidas financieras para sus clientes.
Localización de un asistente de voz para nuevos mercados
Una empresa de tecnología está expandiendo su asistente de voz impulsado por IA al sudeste asiático. Para garantizar que el asistente entienda los acentos y dialectos locales, necesitan grandes cantidades de datos de voz de alta calidad. Utilizando un proveedor de Fuentes de Datos especializado en audio, licencian conjuntos de datos de voz multilingües que cubren varios idiomas y acentos regionales. Esto permite a su equipo de reconocimiento de voz entrenar y ajustar modelos para cada nuevo mercado de manera eficiente, garantizando una experiencia de usuario de alta calidad desde el primer día y acelerando su estrategia de expansión global.