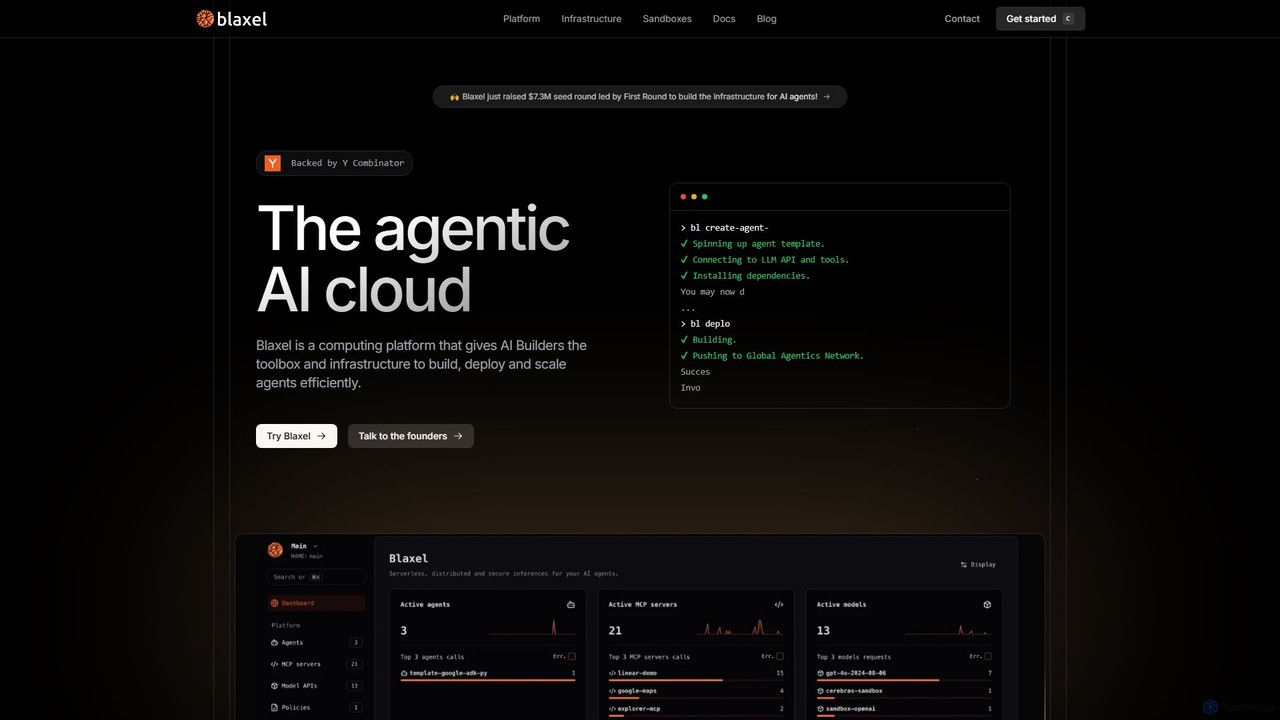
Blaxel
Blaxel es una plataforma de computación sin servidor diseñada para desarrolladores de IA, que proporciona la infraestructura y …
Blaxel es una plataforma de computación sin servidor diseñada para desarrolladores de IA, que proporciona la infraestructura y las herramientas para construir, desplegar y escalar aplicaciones de IA agéntica de manera eficiente. Ofrece VMs en sandbox, una pasarela LLM unificada y observabilidad profunda.
Acerca de Computación en la Nube
Las plataformas de computación en la nube proporcionan acceso bajo demanda a recursos informáticos escalables, esenciales para desarrollar e implementar aplicaciones de IA. Estas plataformas ofrecen hardware virtualizado, como potentes GPU y TPU, junto con vastas capacidades de almacenamiento y redes, eliminando la necesidad de una inversión inicial significativa en infraestructura física. Esto permite a los equipos entrenar modelos complejos, procesar conjuntos de datos masivos y alojar servicios de IA con alta disponibilidad y flexibilidad. El modelo de pago por uso hace que el desarrollo de IA de vanguardia sea accesible para todos, desde investigadores individuales hasta grandes empresas.
Características Principales
- Aceleración por GPU/TPU: Proporciona acceso a procesadores especializados diseñados para acelerar las tareas de entrenamiento e inferencia de modelos de aprendizaje automático.
- Almacenamiento de datos escalable: Ofrece soluciones de almacenamiento de objetos (como Amazon S3 o Google Cloud Storage) capaces de albergar petabytes de datos para conjuntos de entrenamiento.
- Plataformas de IA/ML gestionadas: Ofrece entornos integrados (p. ej., SageMaker, Azure ML) que agilizan todo el ciclo de vida del aprendizaje automático, desde la preparación de datos hasta la implementación del modelo.
- Computación sin servidor (Serverless): Permite el despliegue de modelos de IA como puntos finales que se escalan automáticamente según la demanda, optimizando el costo y el rendimiento para la inferencia.
- Computación de alto rendimiento (HPC): Ofrece clústeres de computadoras interconectadas para ejecutar simulaciones a gran escala y tareas computacionales complejas requeridas para la investigación avanzada en IA.
Casos de Uso
La computación en la nube es fundamental para científicos de datos, ingenieros de aprendizaje automático y startups centradas en la IA. Se utiliza para entrenar grandes modelos de lenguaje (LLM) que requieren una inmensa potencia computacional, desplegar API de visión por computadora en tiempo real para aplicaciones como la conducción autónoma, y ejecutar pipelines de análisis de big data para extraer información para la construcción de modelos.
Cómo Elegir
Al seleccionar un proveedor de computación en la nube para IA, considere la disponibilidad y el rendimiento de modelos específicos de GPU/TPU. Evalúe la madurez y el conjunto de características de sus plataformas de IA/ML gestionadas. Analice los modelos de precios tanto para trabajos de entrenamiento de larga duración como para cargas de trabajo de inferencia esporádicas. Además, evalúe la seguridad de los datos, las certificaciones de cumplimiento y la integración con las herramientas MLOps existentes.
Computación en la NubeEscenario de uso
Entrenamiento de un modelo de aprendizaje profundo a gran escala
Un equipo de ciencia de datos en una empresa de tecnología necesita entrenar un nuevo modelo de visión por computadora en un conjunto de datos de más de 10 millones de imágenes. Usar un servidor local llevaría semanas. En su lugar, utilizan una plataforma de computación en la nube para crear un clúster de 16 instancias de GPU de alto rendimiento. Usan el almacenamiento de datos gestionado de la plataforma para alojar el conjunto de datos y un entorno de aprendizaje profundo preconfigurado para gestionar las dependencias. Esta capacidad de procesamiento paralelo reduce el tiempo de entrenamiento de semanas a solo 48 horas, permitiendo una iteración y mejora del modelo más rápidas.
Despliegue de una API de inferencia de IA escalable
Una startup ha desarrollado una herramienta de corrección gramatical impulsada por IA y necesita servirla a miles de usuarios concurrentes. Construir y mantener la infraestructura para manejar el tráfico fluctuante es complejo y costoso. Optan por un servicio de computación sin servidor de un importante proveedor de la nube. Empaquetan su modelo en un contenedor y lo despliegan como una función sin servidor. La plataforma se encarga automáticamente del escalado, el aprovisionamiento y el mantenimiento. Este enfoque les permite pagar solo por el tiempo de cómputo que realmente utilizan, reduciendo significativamente los costos operativos y asegurando una experiencia receptiva para todos los usuarios, incluso durante los picos de demanda.
Ejecución de procesamiento de Big Data para ingeniería de características
Un ingeniero de ML necesita procesar terabytes de datos de registro de usuarios sin procesar para crear características para un motor de recomendación. Una sola máquina no puede manejar este volumen. El ingeniero utiliza un servicio de big data gestionado en la nube, como Apache Spark en EMR o Dataproc. Escribe un script para limpiar, transformar y agregar los datos, y luego lo ejecuta en un clúster de docenas de máquinas aprovisionado dinámicamente. El servicio en la nube se encarga de la gestión del clúster, y el trabajo finaliza en unas pocas horas en lugar de días. El conjunto de características resultante se almacena en el almacenamiento en la nube, listo para el entrenamiento del modelo.
Construcción de un pipeline de MLOps de extremo a extremo
Un equipo de IA empresarial quiere automatizar todo su flujo de trabajo de aprendizaje automático para garantizar la reproducibilidad y acelerar la implementación. Utilizan una plataforma de IA gestionada de un proveedor de la nube. Esta plataforma integra herramientas para el versionado de datos, el seguimiento de experimentos, el entrenamiento de modelos automatizado (AutoML), el registro de modelos y CI/CD para la implementación. Un ingeniero de ML define todo el pipeline, desde la ingesta de datos hasta la monitorización del modelo en producción. Cuando hay nuevos datos disponibles, el pipeline se activa automáticamente, reentrena el modelo, ejecuta pruebas y despliega la nueva versión si cumple con los criterios de rendimiento, todo dentro de un entorno de nube unificado.
Afinamiento de un modelo de lenguaje fundamental
Una startup de tecnología legal quiere crear un asistente de IA especializado para el análisis de contratos. En lugar de construir un gran modelo de lenguaje (LLM) desde cero, deciden afinar un potente modelo de código abierto en su conjunto de datos propietario de documentos legales. Utilizan una plataforma en la nube para alquilar una instancia de GPU de alta memoria (como una A100) durante unos días. Suben su conjunto de datos a un almacenamiento seguro en la nube y utilizan un marco de entrenamiento popular para ejecutar el proceso de afinamiento. La nube proporciona la potencia computacional necesaria de forma temporal y rentable, permitiéndoles crear un activo de IA altamente especializado y valioso sin poseer hardware costoso.
Alojamiento de un entorno de ciencia de datos colaborativo
Un equipo distribuido de científicos de datos necesita un entorno centralizado para colaborar en un proyecto. La configuración de entornos locales individuales conduce a conflictos de versiones e inconsistencias. El líder del equipo utiliza un servicio de cuadernos gestionado de un proveedor de la nube (como Amazon SageMaker Studio o Google Vertex AI Workbench). Esto proporciona a cada miembro del equipo una instancia de JupyterLab en contenedores y basada en la nube con acceso compartido a conjuntos de datos y repositorios de código. Esto asegura que todos trabajen con las mismas herramientas y datos, agiliza la colaboración y permite al líder monitorear fácilmente el progreso y gestionar los recursos sin ninguna configuración de infraestructura.