Edgee
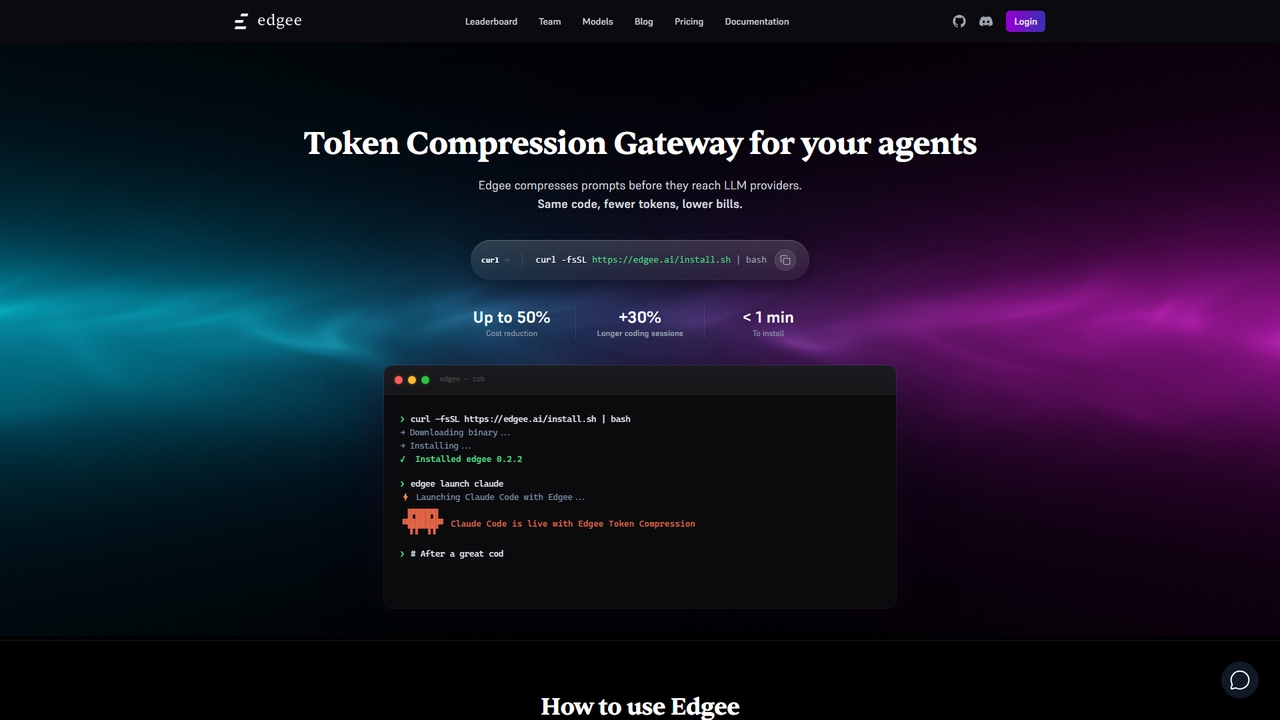
Edgee es una puerta de enlace de compresión de tokens que reduce los costos de prompts LLM hasta …
Edgee es una puerta de enlace de compresión de tokens que reduce los costos de prompts LLM hasta en un 50%. Funciona de forma transparente con agentes de codificación como Claude, Codex y Cursor.
APIPark
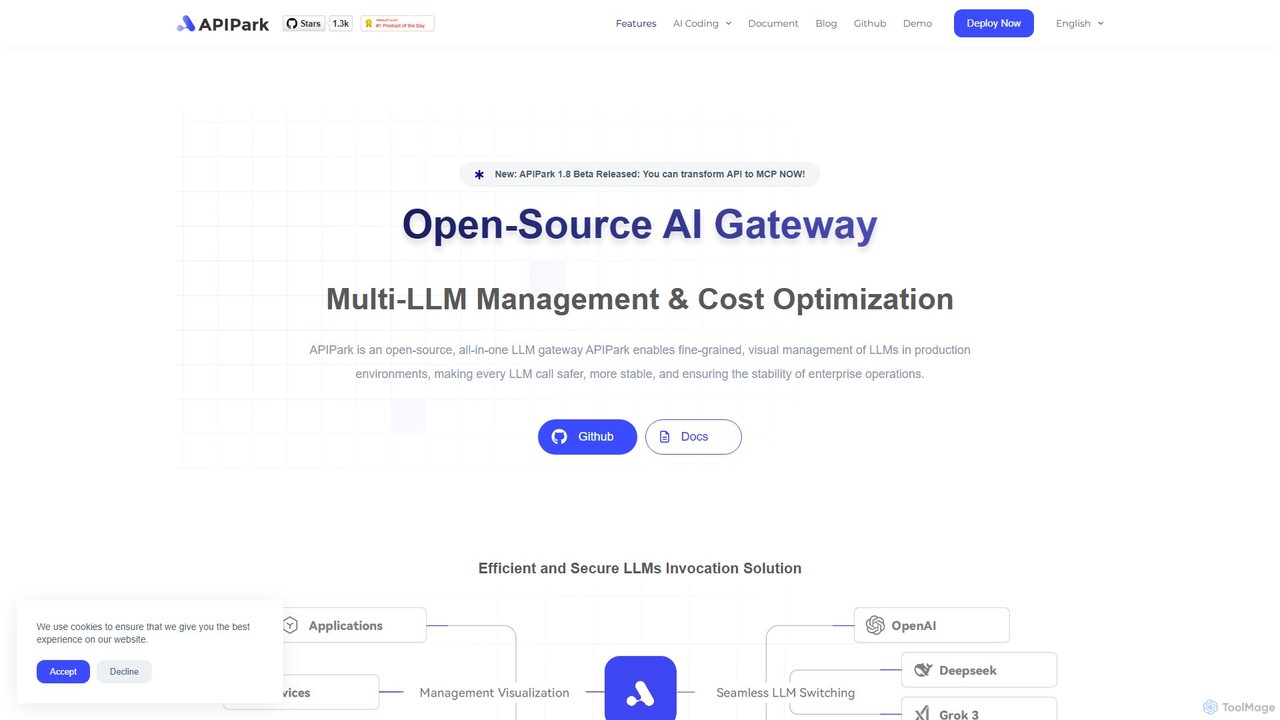
APIPark es un gateway de IA de código abierto y un portal para desarrolladores diseñado para ayudar a …
APIPark es un gateway de IA de código abierto y un portal para desarrolladores diseñado para ayudar a las empresas a gestionar, integrar y desplegar servicios de IA de forma eficiente. Centraliza las llamadas a LLM, reduce costes y proporciona herramientas para compartir, monitorizar y securizar APIs.
Acerca de Pasarela LLM
Las Pasarelas LLM (LLM Gateways) son herramientas de middleware especializadas que gestionan y optimizan el acceso a múltiples Modelos de Lenguaje Grandes (LLMs). Funcionan como una capa de API unificada, situada entre las aplicaciones y diversos proveedores de LLM como OpenAI, Anthropic o Google. Este control centralizado permite a los desarrolladores enrutar solicitudes, gestionar claves de API y monitorear el uso sin estar atados a un único ecosistema de modelos. Como parte clave de la Infraestructura de IA, las Pasarelas LLM son esenciales para construir aplicaciones impulsadas por IA que sean escalables, rentables y resilientes.
Funcionalidades Clave
- Punto de Acceso API Unificado: Acceda a diversos LLMs de múltiples proveedores a través de una única interfaz consistente.
- Enrutamiento Inteligente y Conmutación por Error: Dirija automáticamente las solicitudes al modelo óptimo según el costo, la latencia o la disponibilidad, con conmutación por error transparente.
- Gestión y Control de Costos: Rastree el uso de tokens en tiempo real, establezca presupuestos y aplique límites de tasa para prevenir gastos inesperados.
- Caché de Rendimiento: Almacene y reutilice respuestas para consultas frecuentes para reducir la latencia y minimizar llamadas a la API redundantes.
- Observabilidad Centralizada: Consolide registros, métricas y trazas de todas las interacciones con LLMs para simplificar el monitoreo y la depuración.
Casos de Uso
Las Pasarelas LLM son ampliamente utilizadas por empresas de tecnología que construyen productos nativos de IA, corporaciones que integran IA generativa en flujos de trabajo existentes y equipos de desarrollo que requieren flexibilidad de modelos. Son particularmente valiosas en entornos de producción para gestionar estrategias multi-nube o multi-modelo, optimizar costos operativos y garantizar la fiabilidad de la aplicación.
Cómo Elegir
Al seleccionar una Pasarela LLM, considere la gama de proveedores de LLM soportados, las opciones de despliegue (en la nube vs. auto-alojado), la sofisticación de las reglas de enrutamiento y caché, y sus capacidades de integración con su pila de observabilidad existente (por ejemplo, herramientas de registro y monitoreo). Además, evalúe las características de seguridad y la sobrecarga de latencia que introduce la pasarela.
Pasarela LLMEscenario de uso
Integración de IA Multi-Modelo para Empresas
Un equipo de desarrollo empresarial necesita integrar funciones de IA generativa en múltiples aplicaciones internas, como un CRM y una base de conocimientos. En lugar de construir integraciones separadas para cada proveedor de LLM, implementan una Pasarela LLM. Esto proporciona un único punto de acceso seguro para todas las aplicaciones. La pasarela se configura para enrutar las consultas de datos sensibles a un modelo privado y auto-alojado, mientras que las tareas generales de creación de contenido se envían al modelo comercial más rentable. Este enfoque simplifica el mantenimiento, aplica políticas de seguridad de forma centralizada y evita la dependencia de un solo proveedor.
Control de Costos para una Aplicación SaaS
Una empresa SaaS ofrece una función de resumen de contenido impulsada por IA a sus clientes en diferentes niveles de precios. Para gestionar los costos operativos, utilizan una Pasarela LLM. La pasarela impone límites estrictos de tokens mensuales para cada cliente según su plan de suscripción. También proporciona análisis detallados sobre los patrones de uso, ayudando al equipo de producto a comprender los costos por función y ajustar los precios. Además, configuran una regla para enrutar las solicitudes de los usuarios del nivel gratuito a un modelo más barato y ligeramente menos potente, reservando los modelos premium para los clientes de pago.
Garantizar Alta Disponibilidad con Conmutación por Error de Modelos
Una plataforma de servicio al cliente depende de un chatbot de IA que debe estar disponible 24/7. Para evitar el tiempo de inactividad causado por interrupciones del proveedor de LLM o degradación del rendimiento, el equipo de DevOps implementa una Pasarela LLM. Configuran un modelo principal para todas las solicitudes, pero establecen un modelo secundario de un proveedor diferente como respaldo. La pasarela monitorea continuamente la salud y la latencia del modelo principal. Si detecta un problema, redirige de forma automática y transparente todo el tráfico al modelo de respaldo hasta que se restablezca el servicio principal, garantizando un servicio ininterrumpido para los usuarios finales.
Pruebas A/B de LLMs para un Rendimiento Óptimo
Un equipo de producto quiere determinar si un nuevo modelo de código abierto, afinado, proporciona mejores resultados para su caso de uso específico que su LLM comercial actual. Usando una Pasarela LLM, configuran una prueba A/B. La pasarela se configura para enrutar el 10% del tráfico de usuarios al nuevo modelo, mientras que el otro 90% continúa usando el existente. A través del registro centralizado de la pasarela, el equipo puede comparar fácilmente métricas clave como la calidad de la respuesta (a través de los comentarios de los usuarios), la latencia y el costo por consulta para ambos modelos. Este enfoque basado en datos les permite tomar una decisión informada sin interrumpir la experiencia del usuario.
Gestión y Versionado Centralizado de Prompts
Un gran equipo de desarrolladores e ingenieros de prompts trabaja en una aplicación con docenas de funciones impulsadas por IA. Gestionar y actualizar los prompts directamente en el código de la aplicación es lento y propenso a errores. Adoptan una Pasarela LLM que incluye un sistema de gestión de prompts. Esto les permite almacenar, versionar y desplegar plantillas de prompts desde un panel central. Cuando un prompt necesita ser mejorado, un ingeniero de prompts puede actualizarlo en la interfaz de usuario de la pasarela, y el cambio se refleja instantáneamente en la aplicación sin requerir un nuevo despliegue de código. Esto desacopla la ingeniería de prompts del ciclo de vida del desarrollo de software.
Implementación de Caché Semántico para el Rendimiento
Una plataforma de análisis de noticias financieras realiza llamadas a la API frecuentes y similares a un LLM para resumir artículos de noticias de última hora. Para reducir la latencia y recortar costos, utilizan una Pasarela LLM con capacidades de caché semántico. Cuando llega una solicitud para resumir un nuevo artículo, la pasarela primero verifica su caché en busca de solicitudes semánticamente similares. Si ya existe un resumen suficientemente similar, devuelve la respuesta en caché al instante, evitando una costosa llamada al LLM. Esto mejora significativamente los tiempos de respuesta para los usuarios que ven noticias populares y reduce el gasto general en API en más del 40%.