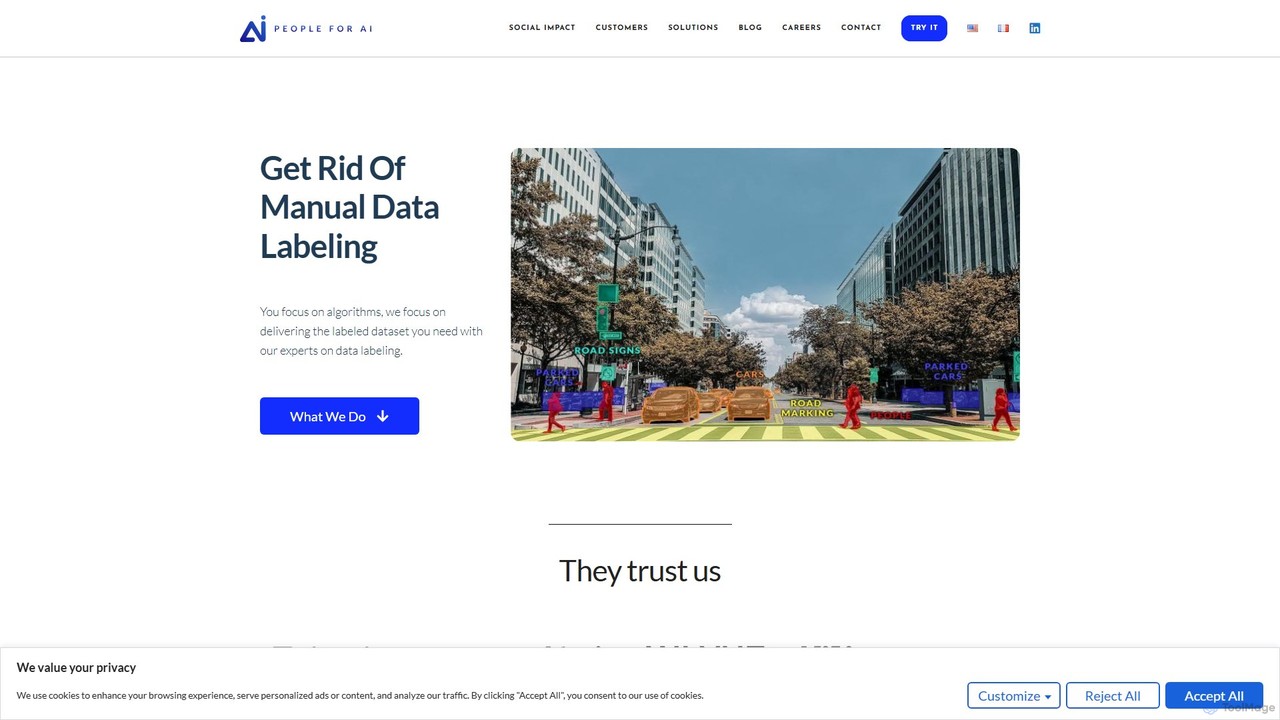
People For AI
People For AI proporciona servicios de etiquetado de datos dirigidos por expertos para proyectos de machine learning. Se …
People For AI proporciona servicios de etiquetado de datos dirigidos por expertos para proyectos de machine learning. Se especializan en anotaciones seguras y de alta calidad para conjuntos de datos complejos de imágenes y texto. Al utilizar etiquetadores internos a largo plazo en lugar de crowdsourcing, garantizan una precisión, flexibilidad y seguridad de datos superiores. Sus servicios se dirigen a diversas industrias, incluyendo vehículos autónomos, microscopía, retail e infraestructura, ayudando a las empresas a acelerar su desarrollo de IA con datos de entrenamiento fiables.
Acerca de Datos de Entrenamiento
Las herramientas de Datos de Entrenamiento son plataformas diseñadas para crear, gestionar y adquirir conjuntos de datos de alta calidad para entrenar modelos de inteligencia artificial. Como componente fundamental de la Infraestructura de IA, estas herramientas proporcionan la información estructurada necesaria para que los algoritmos de aprendizaje automático aprendan patrones y realicen predicciones precisas. Son esenciales para mejorar el rendimiento del modelo, reducir el sesgo y acelerar el ciclo de vida del desarrollo de aplicaciones de IA. Las funcionalidades clave van desde la anotación y el etiquetado de datos hasta la generación de datos sintéticos y el aseguramiento de la calidad.
Funciones Clave
- Anotación y Etiquetado de Datos: Proporciona interfaces intuitivas para etiquetar con precisión diversos tipos de datos, como imágenes, texto, audio y video, con técnicas como cuadros delimitadores, segmentación semántica y etiquetado de entidades.
- Generación de Datos Sintéticos: Crea datos artificiales pero realistas para aumentar o reemplazar conjuntos de datos del mundo real, superando problemas de escasez de datos, privacidad y casos extremos.
- Gestión de Conjuntos de Datos: Ofrece una plataforma centralizada para versionar, buscar y rastrear conjuntos de datos, garantizando la trazabilidad y la colaboración entre los equipos de aprendizaje automático.
- Flujos de Trabajo de Aseguramiento de Calidad: Incluye funciones de revisión, puntuación por consenso y detección de errores para mantener altos estándares de precisión en las etiquetas y consistencia de los datos.
Escenarios de Aplicación
Estas herramientas son críticas en industrias que dependen de modelos de IA personalizados. Por ejemplo, en el sector automotriz para entrenar coches autónomos con escenas de carretera anotadas, en la atención médica para desarrollar modelos de diagnóstico a partir de imágenes médicas etiquetadas, y en el comercio minorista para construir motores de recomendación de productos basados en datos de comportamiento del usuario.
Criterios de Selección
Al elegir una herramienta de Datos de Entrenamiento, considere los tipos de datos específicos con los que trabaja (p. ej., video, nubes de puntos 3D). Evalúe la calidad y eficiencia de las interfaces de anotación, la capacidad de la plataforma para escalar con grandes conjuntos de datos y sus capacidades de integración con su canal de MLOps existente. Además, evalúe las funciones de colaboración y los mecanismos de control de calidad.
Datos de EntrenamientoEscenario de uso
Anotación de Escenas de Carretera para Conducción Autónoma
Un ingeniero de ML en una empresa de tecnología automotriz tiene la tarea de mejorar el modelo de percepción de un vehículo autónomo. Usando una plataforma de datos de entrenamiento, su equipo anota miles de horas de metraje de video de vehículos de prueba. Utilizan herramientas de segmentación semántica para etiquetar cada píxel de la carretera, carriles y aceras, y cuadros delimitadores para la detección de objetos para identificar peatones, vehículos y señales de tráfico. Este conjunto de datos meticulosamente etiquetado se utiliza luego para entrenar y validar la IA, mejorando significativamente su capacidad para navegar de forma segura en entornos urbanos complejos.
Etiquetado de Imágenes Médicas para Detección de Enfermedades
Un equipo de investigación médica está desarrollando un modelo de IA para detectar signos tempranos de cáncer a partir de tomografías computarizadas. Debido a la naturaleza crítica de la tarea, la precisión de los datos es primordial. Utilizan una plataforma de datos de entrenamiento especializada que admite formatos de imagen DICOM y proporciona herramientas de anotación de alta precisión. Los radiólogos colaboran en la plataforma para contornear tumores potenciales y etiquetar anomalías. Las funciones de aseguramiento de la calidad de la plataforma, como la revisión por pares y la puntuación por consenso, garantizan que el conjunto de datos final sea altamente fiable, lo que conduce a una IA de diagnóstico más precisa y confiable.
Generación de Datos Sintéticos para Detección de Fraude Financiero
Una empresa fintech quiere construir un modelo de detección de fraude más robusto, pero está limitada por regulaciones de privacidad (como el RGPD) que restringen el uso de datos de transacciones de clientes reales. Para superar esto, su equipo de ciencia de datos utiliza una herramienta de generación de datos sintéticos. La herramienta analiza las propiedades estadísticas de sus datos reales anonimizados y genera un nuevo conjunto de datos mucho más grande de transacciones artificiales que imita los patrones del mundo real sin contener ninguna información de identificación personal. Esto les permite entrenar su modelo en escenarios de fraude diversos y complejos, mejorando las tasas de detección mientras se mantienen en total cumplimiento con las leyes de privacidad.
Curación de Conjuntos de Datos para Procesamiento de Lenguaje Natural (PLN)
Una startup de IA conversacional está construyendo un chatbot de próxima generación. Para entrenar al modelo para que entienda la intención del usuario con precisión, necesitan un conjunto de datos de texto anotado grande y diverso. Usando una plataforma de datos, recopilan y cargan miles de consultas de usuarios. Luego, un equipo de anotadores utiliza las herramientas de anotación de texto de la plataforma para etiquetar cada consulta con intenciones específicas (p. ej., 'consultar_saldo', 'realizar_pago') e identificar y etiquetar entidades (p. ej., fechas, cantidades, nombres). El control de versiones de la plataforma les permite rastrear cambios y gestionar múltiples versiones del conjunto de datos a medida que el modelo evoluciona, asegurando un enfoque sistemático para la mejora del modelo.
Mejora de la Búsqueda en E-commerce con Etiquetado de Productos
Un gigante del comercio minorista en línea tiene como objetivo mejorar su motor de búsqueda y recomendación de productos. Su equipo de datos utiliza un servicio de datos de entrenamiento para etiquetar millones de imágenes de productos con atributos detallados. Los anotadores etiquetan los artículos con categorías (p. ej., 'ropa de mujer'), subcategorías ('vestidos'), estilos ('bohemio') y características específicas ('estampado floral', 'cuello en V'). Estos datos estructurados y de alta calidad se utilizan para entrenar un modelo de visión por computadora que puede categorizar automáticamente nuevos productos y potenciar una función de 'búsqueda visual' más intuitiva, lo que conduce a un mejor descubrimiento de productos y un aumento de las ventas.
Entrenamiento de un Asistente de Voz con Transcripción de Audio
Una empresa de tecnología está desarrollando un nuevo asistente de voz para el hogar inteligente. Para asegurarse de que entienda varios acentos y comandos, recopilan miles de clips de audio de personas hablando. Usando una plataforma de anotación de datos, un equipo distribuido de lingüistas transcribe el habla a texto y etiqueta ruidos de fondo como 'timbre' o 'ladrido_de_perro'. También etiquetan la emoción o intención del hablante. Este rico conjunto de datos de audio permite a los ingenieros entrenar un modelo de reconocimiento de voz robusto que funciona bien en entornos domésticos ruidosos del mundo real, proporcionando una experiencia de usuario superior.