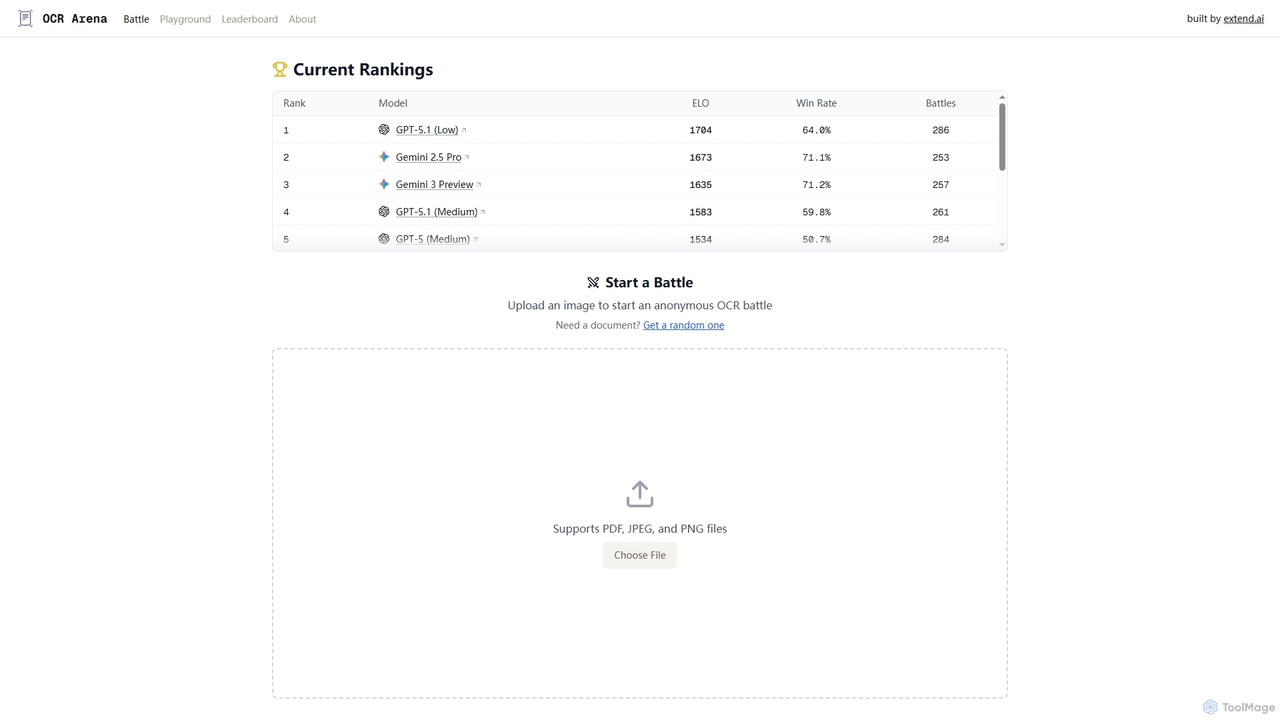
OCR Arena
OCR Arena es una plataforma en línea gratuita diseñada para probar y evaluar los principales Modelos de Lenguaje …
OCR Arena es una plataforma en línea gratuita diseñada para probar y evaluar los principales Modelos de Lenguaje Visual (VLM) y modelos de Reconocimiento Óptico de Caracteres (OCR) de código abierto. Permite a los usuarios cargar documentos, medir la precisión y comparar el rendimiento de los modelos en una tabla de clasificación pública.
Reliable Agents
Una guía definitiva y plataforma de benchmarking para la automatización agéntica. Proporciona a los desarrolladores mapas de mercado …
Una guía definitiva y plataforma de benchmarking para la automatización agéntica. Proporciona a los desarrolladores mapas de mercado interactivos, análisis de rendimiento e informes sobre herramientas para la navegación web y el control de computadoras, ayudándoles a construir agentes de IA fiables.
Acerca de Evaluación comparativa
Las herramientas de evaluación comparativa (Benchmarking) de IA son utilidades especializadas para desarrolladores que permiten evaluar y comparar sistemáticamente el rendimiento de modelos, algoritmos y hardware de IA. Funcionan ejecutando pruebas estandarizadas en conjuntos de datos comunes para medir métricas clave como la precisión, la velocidad de inferencia, la latencia y el consumo de recursos. Este proceso proporciona información objetiva y basada en datos, permitiendo a los desarrolladores identificar cuellos de botella de rendimiento, validar mejoras y seleccionar los componentes más adecuados para sus sistemas de IA. Estas herramientas son cruciales para garantizar la reproducibilidad y seguir el progreso frente a los estándares de la industria.
Funciones Clave
- Suites de Pruebas Estandarizadas: Proporciona benchmarks y conjuntos de datos preconfigurados para tareas comunes como la clasificación de imágenes o el procesamiento del lenguaje natural.
- Seguimiento de Métricas de Rendimiento: Mide una amplia gama de métricas, incluyendo precisión, puntuación F1, latencia, rendimiento (throughput) y uso de memoria.
- Análisis Comparativo: Ofrece paneles de control para comparar lado a lado el rendimiento de diferentes modelos, frameworks o configuraciones de hardware.
- Control del Entorno: Asegura condiciones de prueba consistentes y reproducibles para garantizar comparaciones justas y fiables.
- Generación de Tablas de Clasificación: Clasifica automáticamente modelos o sistemas según las métricas de rendimiento seleccionadas, facilitando una evaluación clara.
Casos de Uso
Estas herramientas son esenciales para ingenieros de MLOps que monitorean modelos en producción, investigadores de IA que comparan algoritmos novedosos y fabricantes de hardware que evalúan la eficiencia de nuevos aceleradores de IA. También se utilizan con frecuencia en pipelines de CI/CD para pruebas de regresión de rendimiento automatizadas.
Cómo Elegir
Al seleccionar una herramienta de benchmarking, considere su compatibilidad con sus frameworks de IA específicos (p. ej., TensorFlow, PyTorch), la amplitud de las métricas que puede rastrear, su capacidad para escalar en experimentos grandes y sus capacidades de integración con su flujo de trabajo de desarrollo e infraestructura existentes.
Evaluación comparativaEscenario de uso
Selección de Modelos para Despliegue en Producción
Un equipo de MLOps necesita desplegar un nuevo modelo de detección de fraude. Utilizan una herramienta de benchmarking para evaluar tres modelos candidatos en un conjunto de datos estandarizado. La herramienta mide no solo la precisión de la predicción, sino también la latencia de inferencia y el consumo de memoria. Basándose en el informe comparativo que muestra que un modelo ofrece el mejor equilibrio entre precisión y velocidad para su API en tiempo real, el equipo lo selecciona con confianza para el despliegue.
Evaluación de Hardware Acelerador de IA
Una empresa de semiconductores está lanzando una nueva GPU para cargas de trabajo de IA. Para demostrar su superioridad, su equipo utiliza una suite de benchmarking estándar de la industria para ejecutar pruebas como MLPerf. Comparan el rendimiento de su GPU (rendimiento y eficiencia energética) con el de la competencia en modelos como BERT y ResNet-50. Las tablas de clasificación generadas se convierten en activos de marketing clave para demostrar el valor de su hardware.
Garantizar la Reproducibilidad en la Investigación Académica
Un laboratorio de investigación universitario desarrolla un novedoso algoritmo de optimización. Para publicar sus hallazgos, deben demostrar su eficacia frente a los métodos existentes. Utilizan un marco de benchmarking para ejecutar todos los experimentos en un entorno controlado, rastreando meticulosamente el tiempo de entrenamiento, la velocidad de convergencia y la precisión final del modelo. Esto asegura que sus resultados sean reproducibles y proporciona una comparación justa y verificable para la revisión por pares.
Pruebas de Regresión Automatizadas en CI/CD
Una empresa de software integra una herramienta de benchmarking en su pipeline de CI/CD para una función impulsada por IA. Cada vez que un desarrollador confirma nuevo código, el pipeline activa automáticamente una prueba de benchmark en un conjunto de datos de referencia. La herramienta comprueba si los cambios han afectado negativamente la velocidad de procesamiento o la calidad de la salida. Si se detecta una regresión de rendimiento, la compilación falla, evitando que el código más lento llegue a producción.
Optimización de Costos de Infraestructura en la Nube
Una startup está desplegando un servicio de visión por computadora y quiere minimizar los gastos operativos. Utilizan una herramienta de benchmarking para probar el rendimiento de su modelo en varios tipos de instancias en la nube (p. ej., diferentes configuraciones de CPU/GPU). La herramienta mide el costo por inferencia al correlacionar los datos de rendimiento con los precios de la nube pública. Este análisis les ayuda a identificar la instancia más rentable que aún cumple con sus SLAs de latencia.
Validación y Comparación de APIs de LLM
Un equipo de producto está construyendo una aplicación que depende de una API de un Modelo de Lenguaje Grande (LLM). Están considerando varios proveedores y utilizan una herramienta de benchmarking para enviar un conjunto curado de prompts a cada API. La herramienta evalúa y compara a los proveedores basándose en la calidad de la respuesta (usando un modelo de evaluación), la latencia y los límites de tasa, permitiendo al equipo tomar una decisión informada y respaldada por datos sobre qué API integrar.