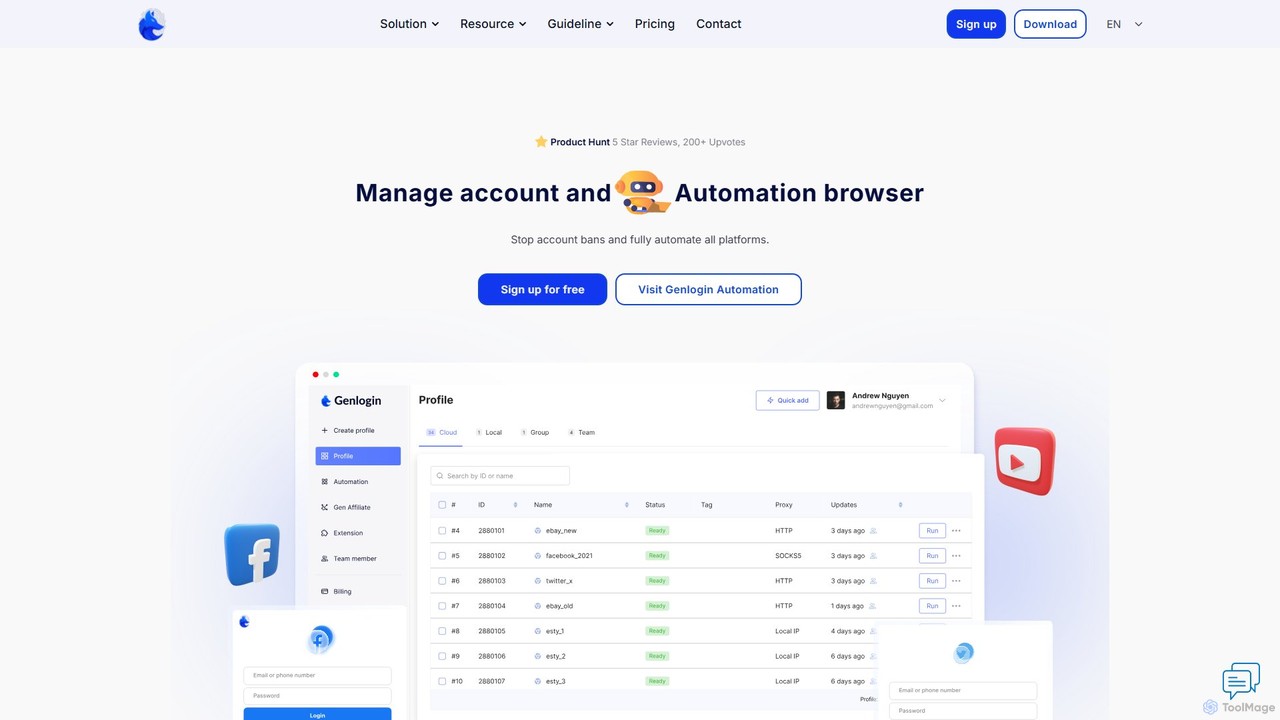
Genlogin
Genlogin es un navegador antidetección avanzado diseñado para gestionar múltiples cuentas en línea de forma segura y eficiente. …
Genlogin es un navegador antidetección avanzado diseñado para gestionar múltiples cuentas en línea de forma segura y eficiente. Evita los bloqueos de cuentas creando huellas dactilares de navegador únicas y basadas en datos reales para cada perfil. Con funciones como automatización sin código, sincronización de acciones en tiempo real y un servicio de proxy integrado, Genlogin es ideal para comercio electrónico, marketing en redes sociales, extracción de datos y marketing de afiliados, capacitando a los usuarios para escalar sus operaciones en línea.
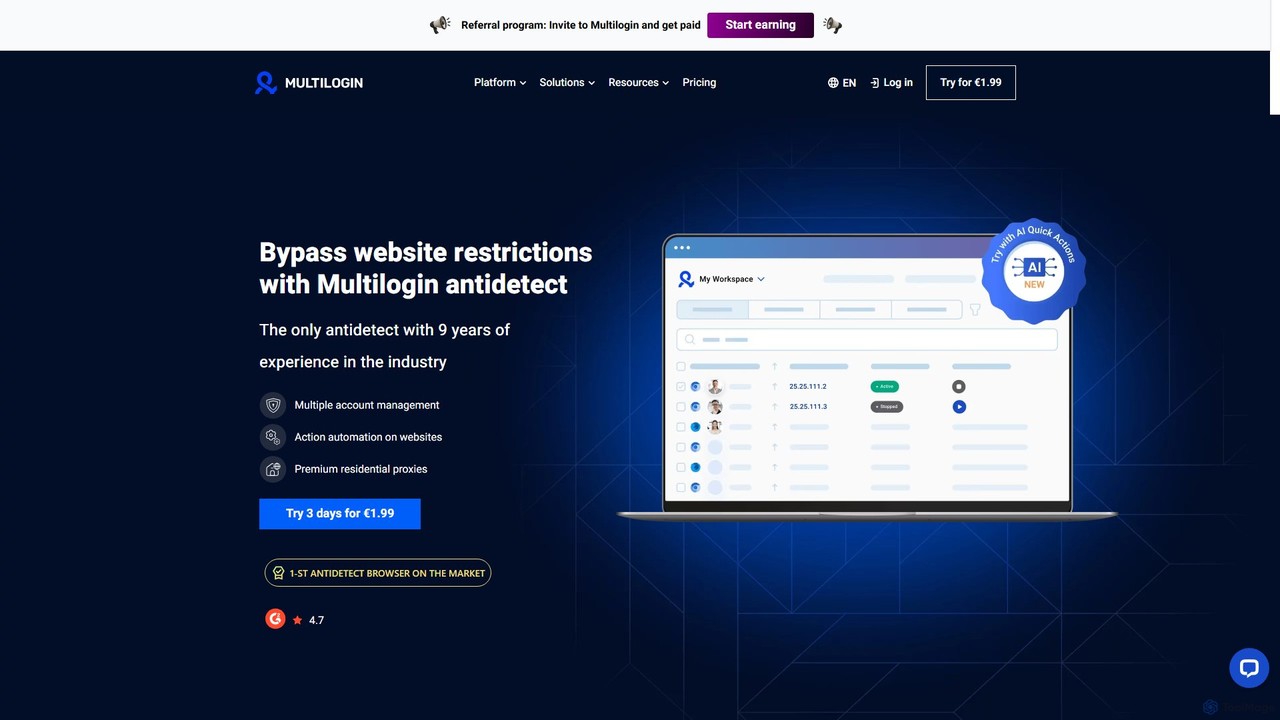
Multilogin
Multilogin es un navegador antidetección líder que permite a los usuarios crear y gestionar múltiples perfiles de navegador …
Multilogin es un navegador antidetección líder que permite a los usuarios crear y gestionar múltiples perfiles de navegador únicos. Está diseñado para evitar restricciones de sitios web y bloqueos de cuentas enmascarando las huellas digitales, lo que lo hace ideal para marketing en redes sociales, comercio electrónico, web scraping y otras operaciones con múltiples cuentas. Incluye funciones como colaboración en equipo, soporte de automatización y proxies residenciales integrados.
Horseman
Horseman es un rastreador web de escritorio infinitamente configurable para desarrolladores, SEOs y analistas de rendimiento. Aprovecha fragmentos …
Horseman es un rastreador web de escritorio infinitamente configurable para desarrolladores, SEOs y analistas de rendimiento. Aprovecha fragmentos de JavaScript personalizados y la integración de GPT-3.5 para extraer, analizar y manipular datos de sitios web, ofreciendo información profunda en sitios enteros sin requerir conocimientos avanzados de codificación.
Acerca de Web Scraping
Las herramientas de Web Scraping son soluciones impulsadas por IA diseñadas para extraer datos automáticamente de sitios web. Estas herramientas aprovechan algoritmos avanzados, a menudo incorporando procesamiento de lenguaje natural y aprendizaje automático, para navegar por páginas web, identificar y recopilar información estructurada o no estructurada. Son esenciales para automatizar la tediosa recopilación manual de datos, proporcionando una adquisición de datos escalable y eficiente para diversas necesidades analíticas. Esta capacidad las hace invaluables para empresas e investigadores que buscan obtener información de la vasta cantidad de datos web públicos.
Características Principales
- Extracción Automatizada de Datos: Recopila sistemáticamente puntos de datos específicos como texto, imágenes y enlaces de páginas web.
- Manejo de Contenido Dinámico: Interactúa con contenido renderizado con JavaScript, formularios y paginación para acceder a todos los datos relevantes.
- Elusión de Medidas Anti-Scraping: Emplea técnicas para sortear medidas comunes anti-bot como CAPTCHAs y bloqueo de IP.
- Estructuración y Exportación de Datos: Organiza los datos extraídos en formatos utilizables como CSV, JSON o XML para facilitar el análisis y la integración.
- Programación y Monitoreo: Permite a los usuarios programar tareas de scraping y monitorear sitios web para obtener información nueva o actualizada.
Escenarios de Aplicación
Las herramientas de web scraping se utilizan ampliamente en la recopilación de inteligencia de mercado para empresas, permitiéndoles monitorear los precios y la información de productos de la competencia en tiempo real. También son cruciales para los investigadores académicos que recopilan grandes conjuntos de datos de fuentes públicas para análisis estadísticos. Las plataformas de comercio electrónico utilizan estas herramientas para el monitoreo de precios en tiempo real y el seguimiento de inventario en varios minoristas en línea.
Cómo Elegir
Al seleccionar una herramienta de web scraping, considere su capacidad para manejar la complejidad de los sitios web objetivo, incluido el contenido dinámico y las medidas anti-scraping. Evalúe su escalabilidad y capacidades de programación en función del volumen y la frecuencia de datos requeridos. Evalúe la facilidad de uso, ya sea a través de una interfaz sin código o una API robusta para desarrolladores. Finalmente, asegúrese de que la herramienta admita prácticas de scraping éticas y el cumplimiento de las regulaciones de privacidad de datos.
Web ScrapingEscenario de uso
Monitoreo de Precios Competitivos para E-commerce
Las empresas de comercio electrónico utilizan herramientas de web scraping para monitorear continuamente los precios de la competencia en varias plataformas en línea. Esto les permite rastrear cambios de precios, identificar ofertas promocionales y ajustar sus propias estrategias de precios en tiempo real para seguir siendo competitivas. Al automatizar este proceso, las empresas pueden ahorrar un esfuerzo manual significativo y asegurar que sus ofertas de productos siempre tengan un precio óptimo, lo que lleva a un aumento de las ventas y la cuota de mercado.
Generación de Leads e Inteligencia de Ventas
Los equipos de ventas y marketing aprovechan el web scraping para extraer información valiosa de leads de directorios públicos, sitios de redes profesionales o portales específicos de la industria. Esto incluye detalles de contacto, perfiles de empresas y cargos, que luego se utilizan para construir listas de prospectos dirigidas. La automatización de la generación de leads reduce significativamente el tiempo dedicado a la entrada manual de datos, permitiendo a los profesionales de ventas centrarse en el compromiso y la conversión, mejorando así la eficiencia del embudo de ventas.
Investigación de Mercado y Análisis de Tendencias
Investigadores y analistas utilizan el web scraping para recopilar grandes cantidades de datos públicos de artículos de noticias, foros, redes sociales y sitios de reseñas. Estos datos se procesan luego para análisis de sentimientos, identificación de tendencias e inteligencia competitiva. Al automatizar la recopilación de datos, pueden adquirir rápidamente información actualizada sobre opiniones de consumidores, tendencias de mercado emergentes y percepción pública de marcas o productos, lo que permite tomar decisiones estratégicas más informadas.
Agregación de Contenido para Portales de Noticias
Las empresas de medios y los agregadores de noticias emplean herramientas de web scraping para recopilar automáticamente artículos, titulares, imágenes y videos de diversas fuentes de noticias y blogs. Esto les permite poblar sus propios feeds de noticias o plataformas de contenido con contenido fresco y diverso sin curación manual. La automatización asegura un flujo constante de información, manteniendo a su audiencia comprometida e informada, al tiempo que reduce significativamente la carga de trabajo editorial.
Análisis de Listados de Bienes Raíces
Los profesionales e inversores inmobiliarios utilizan el web scraping para recopilar listados de propiedades de múltiples plataformas en línea, incluidos portales inmobiliarios y anuncios clasificados. Estos datos agregados permiten un análisis de mercado exhaustivo, identificando tendencias en los valores de las propiedades, las tasas de alquiler y la disponibilidad en diferentes regiones. Al automatizar esta recopilación de datos, pueden tomar decisiones más rápidas y mejor informadas sobre adquisiciones de propiedades, ventas y estrategias de inversión, obteniendo una ventaja competitiva.
Recopilación de Datos para Investigación Académica
Académicos e investigadores utilizan con frecuencia el web scraping para construir grandes conjuntos de datos para sus estudios. Esto implica extraer información de publicaciones científicas, bases de datos gubernamentales, archivos públicos y foros especializados. La capacidad de recopilar y estructurar rápidamente grandes cantidades de datos de diversas fuentes en línea es crucial para la investigación empírica, el análisis estadístico y la validación de hipótesis, acelerando significativamente el proceso de investigación y permitiendo conocimientos más profundos.