nonfinito
nonfinito es una plataforma integral para evaluar y comparar modelos de IA multimodales. Permite a desarrolladores, investigadores y …
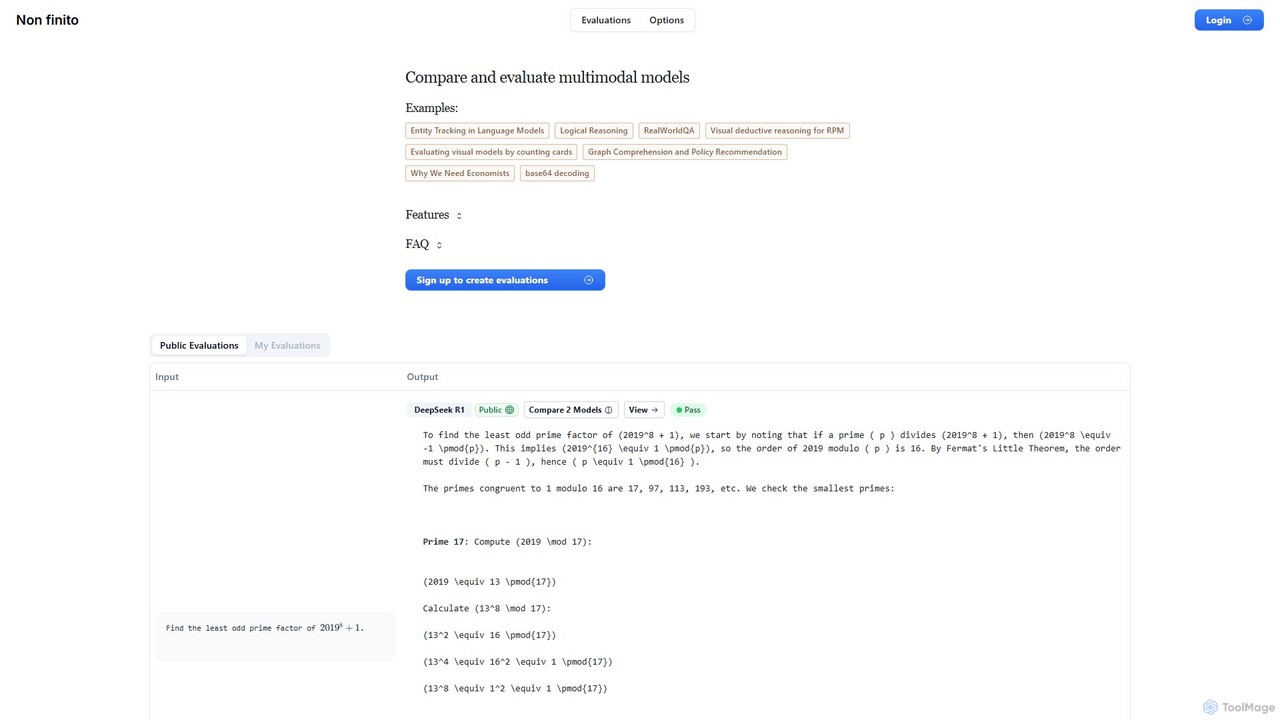
nonfinito es una plataforma integral para evaluar y comparar modelos de IA multimodales. Permite a desarrolladores, investigadores y empresas probar varios LLM lado a lado con prompts personalizados, evaluar su rendimiento con calificaciones de aprobado/fallido y analizar los resultados en bruto. Cree benchmarks públicos o privados para encontrar el mejor modelo para cualquier tarea.
Acerca de Benchmarking
Las herramientas de Benchmarking de IA son plataformas especializadas para evaluar y comparar sistemáticamente el rendimiento de modelos y sistemas de inteligencia artificial. Funcionan ejecutando pruebas estandarizadas o prompts personalizados en diferentes modelos para medir métricas clave como la precisión, velocidad, costo y calidad del resultado. Esto permite a desarrolladores, investigadores y empresas tomar decisiones basadas en datos al seleccionar, ajustar o implementar soluciones de IA. Como parte clave del ecosistema de Productividad, estas herramientas aseguran que los componentes de IA elegidos sean los más efectivos y eficientes para una tarea determinada, optimizando directamente los flujos de trabajo y los resultados.
Funciones Clave
- Métricas de Rendimiento del Modelo: Miden criterios objetivos como precisión, latencia, rendimiento y otras puntuaciones relevantes (p. ej., BLEU, ROUGE).
- Tablas de Clasificación Comparativas: Proporcionan comparaciones lado a lado de múltiples modelos de IA en las mismas tareas para una evaluación clara.
- Conjuntos de Datos Estandarizados: Utilizan benchmarks reconocidos en la industria (p. ej., MMLU, HumanEval) para una evaluación objetiva y reproducible.
- Análisis de Costo-Rendimiento: Calculan y comparan los costos de API frente a la calidad de los resultados de diferentes modelos para determinar el ROI.
- Creación de Pruebas Personalizadas: Permiten a los usuarios construir y ejecutar sus propias pruebas utilizando sus datos, prompts y criterios de evaluación específicos.
Casos de Uso
Estas herramientas son ampliamente utilizadas por desarrolladores de IA para la selección de modelos, científicos de datos para validar modelos ajustados y gerentes de producto para evaluar el ROI de diferentes integraciones de IA. En entornos empresariales, son cruciales para las pruebas de regresión y para garantizar un rendimiento de IA constante a lo largo del tiempo después de las actualizaciones del modelo.
Cómo Elegir
Al seleccionar una herramienta de Benchmarking de IA, considere la gama de modelos compatibles (p. ej., LLMs, modelos de imagen), la disponibilidad de benchmarks relevantes de la industria y la flexibilidad para crear suites de evaluación personalizadas. Además, evalúe sus capacidades de integración con su flujo de trabajo de desarrollo existente y la claridad de sus paneles de informes y análisis.
BenchmarkingEscenario de uso
Selección del mejor LLM para soporte al cliente
Una empresa de tecnología necesita construir un chatbot de IA para gestionar las consultas de los clientes. Utilizan una herramienta de benchmarking para probar tres LLM líderes (p. ej., GPT-4, Claude 3, Gemini Pro) en un conjunto de datos de 1,000 tickets de soporte reales. La herramienta mide automáticamente la precisión de la respuesta, las puntuaciones de cortesía y la latencia de la API para cada modelo. La tabla de clasificación resultante muestra claramente qué modelo ofrece el mejor equilibrio entre calidad y velocidad para sus necesidades específicas, permitiendo una decisión segura y respaldada por datos para su equipo de desarrollo.
Evaluación de mejoras en modelos ajustados
Un equipo de ciencia de datos ajusta un modelo de código abierto para el análisis de documentos legales. Para demostrar su valor, utilizan una plataforma de benchmarking para comparar la versión ajustada con el modelo original y uno propietario. Al ejecutar un conjunto de pruebas personalizado de 200 consultas legales, generan un informe que muestra un aumento del 15% en la precisión en la identificación de cláusulas contractuales. Este resultado cuantitativo justifica la inversión en el ajuste y proporciona una clara evidencia de la mejora del rendimiento a las partes interesadas.
Optimización de prompts para textos de marketing
Un equipo de marketing necesita generar textos publicitarios de alta calidad a gran escala. Utilizan una herramienta de benchmarking para realizar pruebas A/B con 20 variaciones de prompts diferentes en múltiples modelos de IA. La herramienta automatiza el proceso y califica los resultados basándose en criterios de calidad predefinidos, como la claridad y la fuerza de la llamada a la acción. Este enfoque basado en datos les ayuda a identificar la combinación de prompt y modelo con el mejor rendimiento, que luego puede integrarse en su flujo de trabajo de contenido para producir materiales de campaña más efectivos de manera consistente.
Pruebas de regresión de sistemas de IA
Una empresa actualiza el modelo de IA central en su sistema de gestión de conocimiento interno. Antes de la implementación, el equipo de control de calidad utiliza una herramienta de benchmarking para ejecutar un conjunto predefinido de 500 pruebas que cubren funcionalidades clave. La herramienta compara los resultados del nuevo modelo con la línea base de la versión anterior, marcando cualquier caída significativa en el rendimiento. Esto asegura que las actualizaciones no introduzcan regresiones inadvertidamente, manteniendo la fiabilidad del sistema y la confianza del usuario.
Control de costos de API de IA
La aplicación de una startup depende en gran medida de una API de texto a imagen, y los costos están aumentando. Utilizan una herramienta de benchmarking para evaluar tres modelos alternativos más económicos. Prueban todos los modelos con 100 prompts representativos, comparando la calidad de la imagen de salida, la adherencia al estilo y el costo por imagen. El análisis revela un modelo que es un 40% más barato y cumple con el 90% de sus requisitos de calidad. Estos datos les permiten realizar un cambio estratégico, reduciendo significativamente los costos operativos sin un gran compromiso en la calidad del producto.
Investigación académica sobre capacidades de modelos
Investigadores universitarios están estudiando las capacidades de razonamiento de los LLM emergentes. Aprovechan una plataforma de benchmarking para ejecutar sistemáticamente el benchmark ARC (AI2 Reasoning Challenge) en cinco modelos de código abierto diferentes. La plataforma automatiza la ejecución, recopila los resultados y proporciona herramientas de visualización para el análisis. Esto acelera significativamente su proceso de investigación, permitiéndoles centrarse en la interpretación de los datos y la publicación de sus hallazgos comparativos en lugar de en la configuración y ejecución manual de las pruebas.