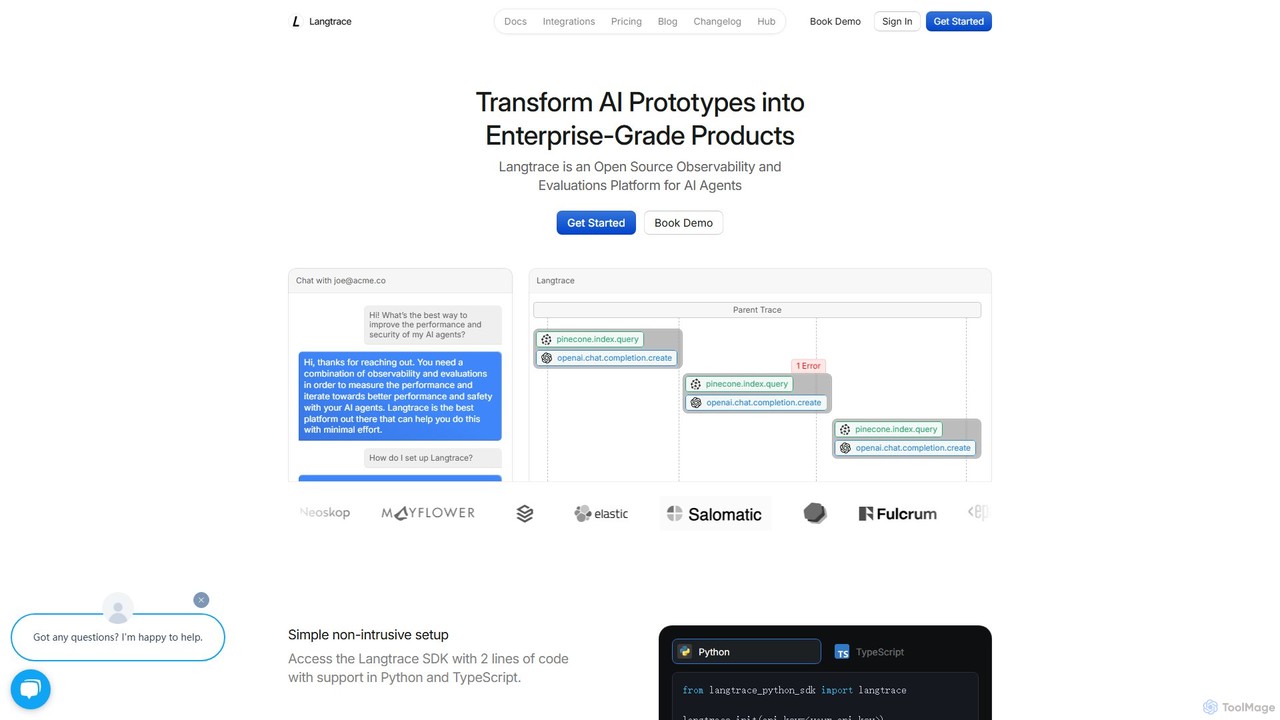
Langtrace
Langtrace es una plataforma de código abierto de observabilidad y evaluación para agentes de IA y aplicaciones LLM. …
Langtrace es una plataforma de código abierto de observabilidad y evaluación para agentes de IA y aplicaciones LLM. Ayuda a los desarrolladores a monitorear, depurar y mejorar el rendimiento, transformando prototipos de IA en productos de nivel empresarial con funciones como trazado, gestión de prompts y seguridad robusta.
Acerca de Entrenamiento y Evaluación de Modelos
Las herramientas de Entrenamiento y Evaluación de Modelos son plataformas de IA especializadas diseñadas para construir, refinar y evaluar el rendimiento de los modelos de aprendizaje automático. Estas herramientas proporcionan entornos completos para la preparación de datos, selección de algoritmos, ajuste de hiperparámetros y pruebas rigurosas, asegurando que los modelos sean robustos, precisos y estén listos para su implementación. Son cruciales para científicos de datos, ingenieros de aprendizaje automático y desarrolladores que buscan crear soluciones de IA de alto rendimiento dentro del contexto más amplio de la mejora de la productividad.
Características Principales
- Preprocesamiento Automatizado de Datos: Herramientas para limpiar, transformar y normalizar datos brutos, haciéndolos adecuados para la ingesta del modelo y reduciendo el esfuerzo manual.
- Selección y Ajuste de Algoritmos: Ofrece una gama de algoritmos de aprendizaje automático y facilita la optimización de hiperparámetros para lograr un rendimiento óptimo del modelo.
- Métricas de Rendimiento y Visualización: Proporciona varias métricas (ej. precisión, recall, F1-score) y ayudas visuales (ej. matrices de confusión, curvas ROC) para una evaluación profunda del modelo.
- Control de Versiones y Seguimiento de Experimentos: Gestiona diferentes iteraciones del modelo y rastrea los parámetros, resultados y metadatos de los experimentos para la reproducibilidad y comparación.
- Infraestructura Escalable: Soporta el entrenamiento distribuido y aprovecha los recursos en la nube para manejar grandes conjuntos de datos y modelos complejos de manera eficiente.
Casos de Uso
Estas herramientas son esenciales para las organizaciones que desarrollan aplicaciones de IA personalizadas, desde análisis predictivo hasta procesamiento de lenguaje natural. Permiten a los equipos de ciencia de datos iterar rápidamente en los diseños de modelos, comparar diferentes enfoques y asegurar que los modelos implementados cumplan con estrictos estándares de rendimiento y fiabilidad. Por ejemplo, una institución financiera podría usar estas herramientas para entrenar y evaluar modelos de detección de fraude, mientras que un proveedor de atención médica podría desarrollar sistemas de IA de diagnóstico.
Cómo Elegir
Al seleccionar una herramienta de Entrenamiento y Evaluación de Modelos, considere su compatibilidad con su infraestructura de datos y lenguajes de programación existentes. Evalúe el rango de algoritmos soportados, la flexibilidad del ajuste de hiperparámetros y la exhaustividad de las métricas de evaluación. La escalabilidad para el crecimiento futuro de los datos y la disponibilidad de funciones de colaboración para proyectos en equipo también son factores críticos. Finalmente, evalúe la facilidad de integración con los pipelines de implementación y la rentabilidad general.
Entrenamiento y Evaluación de ModelosEscenario de uso
Optimización de Modelos de Análisis Predictivo
Un científico de datos en una empresa de comercio electrónico utiliza estas herramientas para entrenar y ajustar un modelo de predicción de abandono de clientes. Al experimentar con diferentes algoritmos e hiperparámetros, pueden lograr una mayor precisión en la identificación de clientes en riesgo, lo que permite al equipo de marketing implementar estrategias de retención dirigidas y reducir significativamente la deserción de clientes.
Desarrollo de Sistemas Robustos de Visión por Computadora
Un ingeniero de IA en una empresa de vehículos autónomos aprovecha las plataformas de entrenamiento y evaluación de modelos para desarrollar y probar modelos de detección de objetos. Pueden gestionar eficientemente grandes conjuntos de datos de imágenes, entrenar modelos en diversas arquitecturas y evaluar rigurosamente métricas de rendimiento como la Precisión Media Promedio (mAP) para garantizar la seguridad y fiabilidad del sistema de percepción del vehículo.
Refinamiento de Modelos de Procesamiento de Lenguaje Natural (PLN)
Un investigador de aprendizaje automático en una empresa tecnológica utiliza estas herramientas para entrenar y evaluar un modelo de análisis de sentimientos para el monitoreo de redes sociales. Pueden preprocesar grandes cantidades de datos de texto, experimentar con diferentes modelos de transformadores y evaluar la capacidad del modelo para clasificar con precisión los sentimientos positivos, negativos y neutrales, proporcionando información valiosa para la gestión de la reputación de la marca.
Automatización del Control de Calidad en la Fabricación
Un ingeniero de fabricación emplea herramientas de entrenamiento y evaluación de modelos para construir un sistema de IA para la detección de defectos en las líneas de montaje. Al entrenar modelos con imágenes de productos impecables y defectuosos, pueden automatizar el proceso de inspección, reducir significativamente los errores manuales y mejorar la consistencia de la calidad del producto, lo que lleva a ahorros de costos y una mayor eficiencia.
Personalización de Experiencias de Usuario en Aplicaciones
Un gerente de producto en un servicio de streaming utiliza estas plataformas para entrenar y evaluar motores de recomendación. Pueden experimentar con filtrado colaborativo y modelos basados en contenido, medir métricas como las tasas de clics y la participación del usuario, y refinar continuamente los algoritmos para ofrecer sugerencias de contenido altamente personalizadas, mejorando la satisfacción y retención del usuario.
Benchmarking y Comparación del Rendimiento de Modelos de IA
Un investigador académico o un equipo de IA competitivo utiliza estas herramientas para entrenar sistemáticamente múltiples modelos en un conjunto de datos estandarizado y comparar su rendimiento en varias métricas. Esto permite una evaluación comparativa objetiva de nuevos algoritmos frente a soluciones de vanguardia existentes, contribuyendo a los avances en el campo e identificando enfoques superiores para tareas específicas.