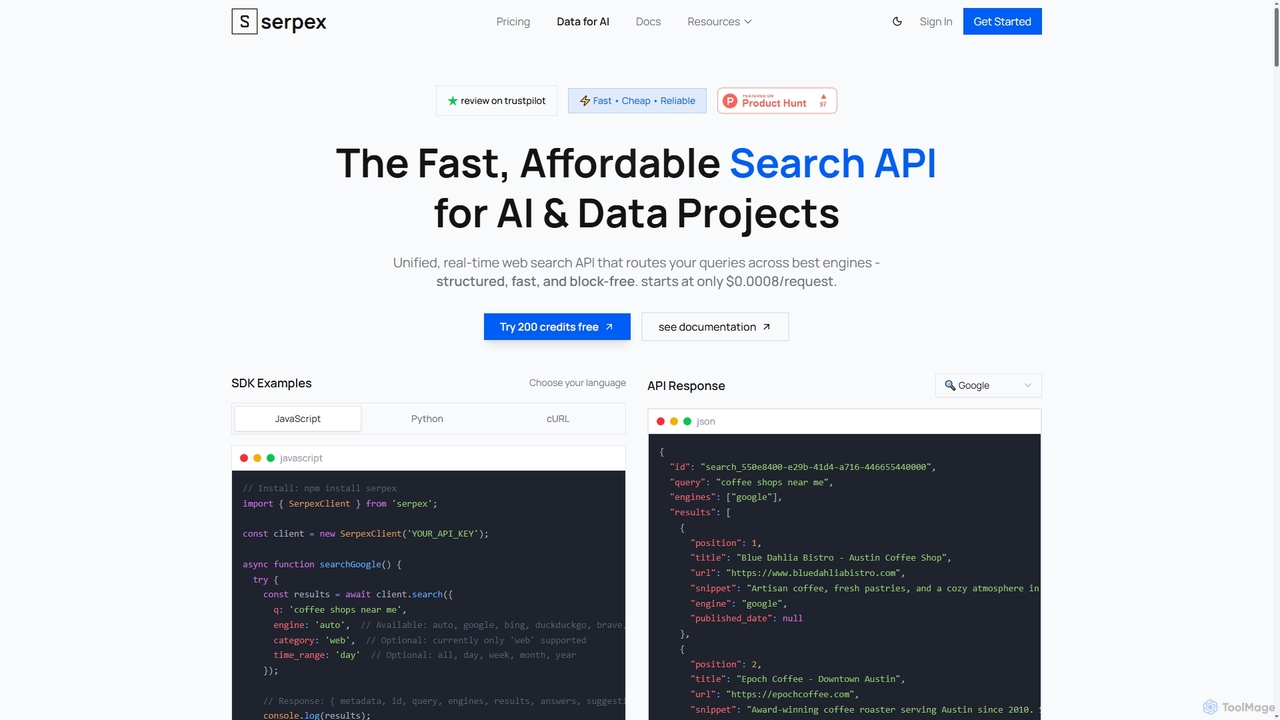
Serpex
Serpex est une API de recherche rapide, abordable et fiable, conçue pour les projets d'IA et de données. …
Serpex est une API de recherche rapide, abordable et fiable, conçue pour les projets d'IA et de données. Elle fournit des résultats de recherche web structurés et en temps réel provenant de plusieurs moteurs de recherche majeurs, surmontant les défis courants comme les CAPTCHAs et les blocages géographiques.
À propos de Source de données
Les outils de Source de Données sont des plateformes et des services qui fournissent des ensembles de données organisés et de haute qualité, essentiels pour l'entraînement, la validation et le test des modèles d'IA. Ces outils offrent un accès à une vaste gamme de types de données, y compris des images, du texte, de l'audio et des données structurées, souvent prétraitées et annotées pour accélérer les flux de travail de l'apprentissage automatique. Ils constituent un composant fondamental du développement de l'IA, permettant aux développeurs et aux chercheurs de construire des systèmes robustes et précis sans le coût et le temps prohibitifs de la collecte et de l'étiquetage des données à partir de zéro. En fournissant des ensembles de données prêts à l'emploi ou personnalisables, ces outils abaissent considérablement la barrière à l'entrée pour la création d'applications d'IA sophistiquées.
Fonctionnalités Clés
- Bibliothèques de Données Diversifiées : Accès à de vastes collections d'ensembles de données préexistants et étiquetés dans divers domaines comme la vision par ordinateur et le NLP.
- Génération de Données Synthétiques : Capacité à créer des données artificielles pour augmenter les ensembles de données réels, couvrir des cas limites ou protéger la vie privée.
- Services d'Annotation de Données : Services intégrés ou partenaires pour l'étiquetage des données brutes afin de les rendre adaptées aux modèles d'apprentissage supervisé.
- Qualité et Versionnement des Données : Fonctionnalités pour assurer la cohérence des données, gérer différentes versions d'ensembles de données et suivre la provenance des données pour la reproductibilité.
- Accès API et SDK : Accès programmatique pour télécharger, diffuser et gérer des ensembles de données directement dans les environnements de développement.
Cas d'Utilisation
Les outils de Source de Données sont essentiels pour les ingénieurs en apprentissage automatique, les scientifiques des données et les chercheurs en IA. Ils sont utilisés pour entraîner des modèles de vision par ordinateur pour la détection d'objets, développer des applications de traitement du langage naturel avec de grands corpus de texte, et évaluer les performances de nouveaux algorithmes par rapport aux normes établies de l'industrie. Ces outils sont inestimables dans des secteurs tels que les véhicules autonomes, la santé pour l'analyse d'images médicales, et la finance pour la modélisation de la détection de fraude.
Comment Choisir
Lors de la sélection d'un outil de Source de Données, tenez compte de la pertinence et de la qualité des ensembles de données pour votre problème spécifique. Évaluez les licences et les droits d'utilisation pour vous assurer qu'ils correspondent aux objectifs commerciaux ou de recherche de votre projet. Analysez la facilité d'intégration via les API et les fonctionnalités de gestion des données de la plateforme, telles que le versionnement. Enfin, comparez les modèles de tarification, qu'ils soient open-source, basés sur un abonnement ou à l'utilisation, pour trouver une solution adaptée à votre budget et à l'échelle de votre projet.
Source de donnéesCas d'utilisation
Entraînement d'un modèle de vision par ordinateur pour la conduite autonome
Une startup en IA développant des systèmes de perception pour véhicules autonomes a besoin d'un vaste et diversifié ensemble de données de scènes routières. Au lieu de passer des mois et d'investir un capital important dans la collecte et l'annotation manuelle d'images, leur équipe de ML utilise une plateforme de Source de Données. Ils accèdent à un ensemble de données pré-étiqueté contenant des millions d'images de piétons, de véhicules et de panneaux de signalisation. Cela leur permet d'entraîner et d'itérer rapidement sur leurs modèles de détection d'objets, accélérant considérablement leur cycle de développement et améliorant la précision du modèle sur les cas limites critiques.
Affinage d'un modèle NLP pour le support client
Une entreprise souhaite créer un chatbot spécialisé pour son support technique. Les modèles de langage à usage général manquent du jargon spécifique et du contexte de résolution de problèmes de leur secteur. Un scientifique des données de l'équipe utilise un outil de Source de Données pour acquérir un grand corpus de conversations et de documentations de support technique anonymisées. En affinant leur modèle de langage de base sur ces données spécifiques au domaine, ils créent un chatbot qui comprend les problèmes des utilisateurs avec une grande précision et fournit des solutions pertinentes, réduisant ainsi la charge de travail des agents humains.
Génération de données synthétiques pour l'imagerie médicale
Un institut de recherche développe un modèle d'IA pour détecter une maladie rare à partir de scanners IRM. En raison de la confidentialité des patients et de la rareté des cas, ils disposent d'un très petit ensemble de données, ce qui entraîne un surajustement du modèle. L'équipe de recherche utilise un outil de Source de Données doté de capacités de génération de données synthétiques. Ils génèrent des milliers de scanners IRM réalistes, mais artificiels, montrant différents stades de la maladie. Cet ensemble de données augmenté leur permet d'entraîner un modèle plus robuste et généralisé, améliorant considérablement sa précision diagnostique sans compromettre la confidentialité des patients.
Évaluation comparative d'un nouvel algorithme de recommandation
L'équipe de science des données d'une entreprise de commerce électronique a développé un nouvel algorithme de recommandation. Pour prouver son efficacité, ils doivent le comparer aux méthodes existantes sur un ensemble de données standardisé. Ils utilisent un hub de Sources de Données pour télécharger des ensembles de données publics bien connus comme MovieLens ou Amazon Reviews. Cela leur permet de mener une expérience juste et reproductible, en mesurant des métriques comme la précision et le rappel. Les résultats, évalués sur un ensemble de données public, fournissent une base crédible pour décider de déployer ou non le nouvel algorithme en production.
Entraînement d'un modèle de détection de fraude avec des données transactionnelles
Une entreprise de technologie financière vise à améliorer son système de détection de fraude en temps réel. Leurs données internes sont limitées et peuvent ne pas couvrir les nouveaux schémas de fraude. Ils s'abonnent à un service de Source de Données qui fournit de grands ensembles de données transactionnelles anonymisées et régulièrement mises à jour. En entraînant leurs modèles d'apprentissage automatique sur ces données étendues, ils peuvent identifier plus efficacement les corrélations subtiles et les anomalies indicatives de fraude. Cet accès à des données externes permet à leur système de devancer les menaces en évolution et de réduire les pertes financières pour leurs clients.
Localisation d'un assistant vocal pour de nouveaux marchés
Une entreprise technologique étend son assistant vocal alimenté par l'IA en Asie du Sud-Est. Pour s'assurer que l'assistant comprend les accents et dialectes locaux, ils ont besoin de grandes quantités de données vocales de haute qualité. En utilisant un fournisseur de Sources de Données spécialisé dans l'audio, ils obtiennent une licence pour des ensembles de données vocales multilingues couvrant diverses langues et accents régionaux. Cela permet à leur équipe de reconnaissance vocale d'entraîner et d'affiner efficacement des modèles pour chaque nouveau marché, garantissant une expérience utilisateur de haute qualité dès le premier jour et accélérant leur stratégie d'expansion mondiale.