Wirestock
Wirestock est un marché connectant les freelances créatifs aux entreprises d'IA, permettant aux créateurs de gagner de l'argent …
Wirestock est un marché connectant les freelances créatifs aux entreprises d'IA, permettant aux créateurs de gagner de l'argent en contribuant des images, vidéos et illustrations de haute qualité pour les ensembles de données d'entraînement de l'IA.
OneNine
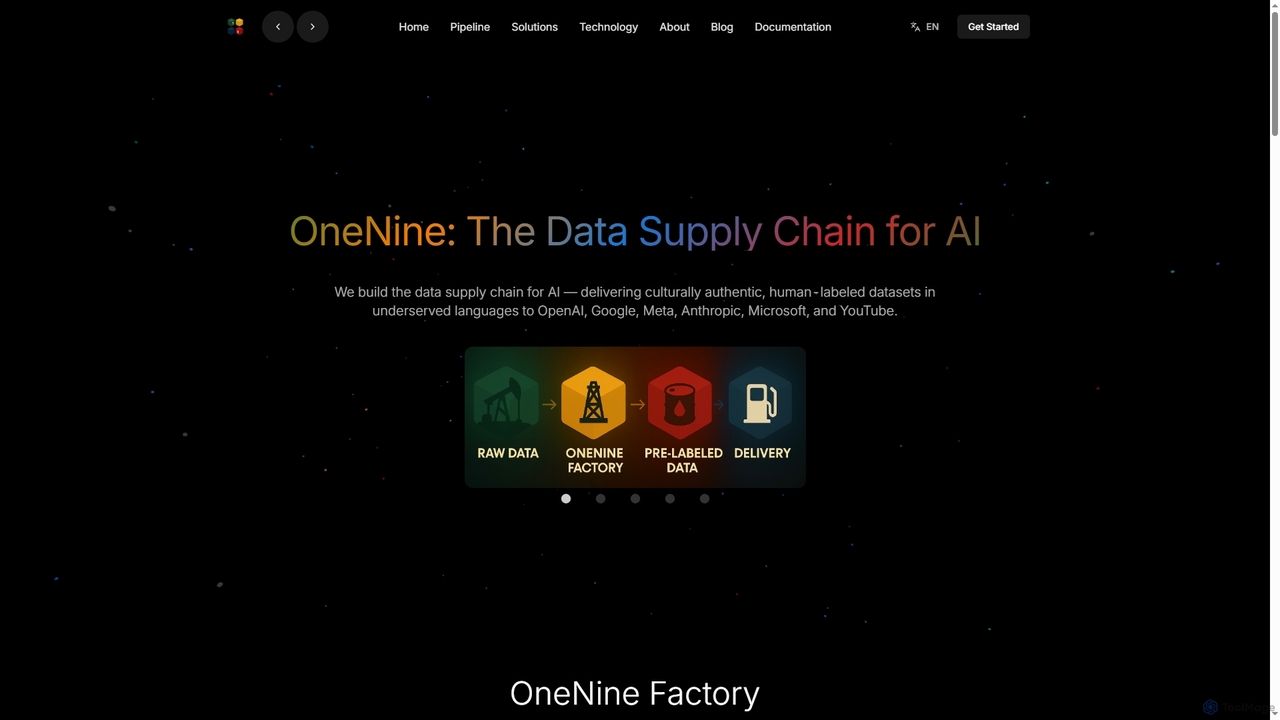
OneNine est la chaîne d'approvisionnement de données pour l'IA, spécialisée dans la livraison de jeux de données étiquetés …
OneNine est la chaîne d'approvisionnement de données pour l'IA, spécialisée dans la livraison de jeux de données étiquetés par des humains, culturellement authentiques et de haute qualité dans des langues sous-représentées aux entreprises d'IA leaders. Il comble le fossé linguistique, permettant des modèles d'IA plus inclusifs et précis à l'échelle mondiale.

Sapien
Sapien est une fonderie de données décentralisée qui fournit des données d'entraînement d'IA de qualité professionnelle. Elle s'appuie …
Sapien est une fonderie de données décentralisée qui fournit des données d'entraînement d'IA de qualité professionnelle. Elle s'appuie sur un réseau mondial de contributeurs humains pour fournir des données spécialisées et de haute qualité pour les systèmes d'IA complexes, y compris l'annotation 3D/4D, le raisonnement expert et la collecte de données à grande échelle.
À propos de Données d'entraînement
Les outils de Données d'entraînement sont des plateformes et des services conçus pour créer, gérer et fournir des ensembles de données de haute qualité pour les modèles d'apprentissage automatique. Ces outils rationalisent le processus critique de préparation des données, offrant des fonctionnalités pour l'annotation de données, la génération de données synthétiques et l'assurance qualité. Leur principale valeur réside dans l'accélération du développement de systèmes d'IA précis et robustes, car la performance de tout modèle dépend fondamentalement de la qualité de ses données d'entraînement. En tant que composant clé du cycle de vie du Développement de l'IA, ils constituent la fondation sur laquelle des modèles efficaces sont construits.
Fonctionnalités Clés
- Annotation et Étiquetage de Données : Fournit des interfaces et des outils automatisés pour étiqueter avec précision divers types de données, tels que les images, le texte et l'audio, afin de créer une vérité terrain pour les modèles.
- Génération de Données Synthétiques : Crée des données artificielles, mais réalistes, pour augmenter des ensembles de données limités, couvrir des cas extrêmes ou protéger des informations sensibles.
- Gestion et Versionnement des Données : Offre une plateforme centralisée pour stocker, suivre et gérer différentes versions d'ensembles de données, garantissant la reproductibilité des expériences.
- Flux de Travail d'Assurance Qualité : Inclut des fonctionnalités de révision, de consensus et de détection d'erreurs pour maintenir des normes élevées de précision et de cohérence des données.
- Approvisionnement en Ensembles de Données : Fournit un accès à des ensembles de données pré-étiquetés et prêts à l'emploi ou des services pour collecter et préparer des données personnalisées.
Cas d'Utilisation
Ces outils sont essentiels dans les industries à forte intensité de données comme les véhicules autonomes pour la détection d'objets, la santé pour l'analyse d'images médicales et le commerce de détail pour la catégorisation de produits. Les ingénieurs en apprentissage automatique, les scientifiques des données et les chercheurs en IA les utilisent quotidiennement pour construire et affiner des ensembles de données pour des tâches allant du traitement du langage naturel à la vision par ordinateur.
Comment Choisir
Lors de la sélection d'un outil de Données d'entraînement, considérez sa prise en charge de vos types de données spécifiques (par ex., vidéo, nuages de points 3D). Évaluez les mécanismes de contrôle qualité, tels que les rôles de réviseur et le score de consensus. Analysez sa capacité à s'adapter à des projets à grande échelle et son aptitude à s'intégrer à votre pipeline MLOps et à votre stockage cloud existants. Enfin, vérifiez ses protocoles de sécurité et sa conformité avec les réglementations sur la confidentialité des données comme le RGPD ou l'HIPAA.
Données d'entraînementCas d'utilisation
Entraînement des Modèles de Perception pour Véhicules Autonomes
Une entreprise de technologie automobile développant des voitures autonomes doit entraîner ses modèles de vision par ordinateur pour identifier avec précision les piétons, les véhicules, les panneaux de signalisation et les marquages au sol. En utilisant une plateforme d'annotation de données, une équipe d'étiqueteurs effectue une segmentation sémantique et une annotation par boîtes englobantes sur des millions d'images et de trames vidéo capturées lors de tests sur route. Les fonctionnalités de contrôle qualité de la plateforme, telles que le score de consensus et les flux de travail de révision, garantissent une grande précision. Cet ensemble de données méticuleusement étiqueté est crucial pour entraîner des modèles de perception capables de naviguer en toute sécurité dans des environnements urbains complexes.
Développement d'une IA de Diagnostic par Imagerie Médicale
Un institut de recherche en santé vise à construire un modèle d'IA pour détecter les tumeurs à un stade précoce dans les scanners IRM. En raison de la rareté des radiologues experts et du coût élevé de l'annotation manuelle, ils utilisent un outil spécialisé d'annotation d'images médicales. Cet outil offre des fonctionnalités telles que le support DICOM et la segmentation semi-automatisée, ce qui accélère le processus. Pour protéger la vie privée des patients, toutes les données sont anonymisées au sein de la plateforme. L'ensemble de données étiquetées de haute qualité qui en résulte permet à l'équipe de science des données d'entraîner un modèle capable d'assister les radiologues en mettant en évidence les zones potentiellement préoccupantes, conduisant à des diagnostics plus précoces et plus précis.
Génération de Données Synthétiques pour la Détection de Fraude
Une entreprise de services financiers souhaite améliorer son modèle de détection de fraude, mais est limitée par le petit nombre d'exemples réels de fraude et des réglementations strictes sur la confidentialité des données. Ils utilisent un outil de génération de données synthétiques pour créer un grand ensemble de données équilibré de transactions financières. L'outil modélise les propriétés statistiques de leurs données réelles pour générer des enregistrements de transactions réalistes mais entièrement artificiels, y compris des scénarios de fraude complexes qui sont rares dans le monde réel. Cela leur permet d'entraîner un modèle plus robuste sans utiliser de données clients sensibles, améliorant les taux de détection tout en maintenant une conformité totale.
Amélioration de la Catégorisation des Produits E-commerce
Un géant de la vente au détail en ligne gère des millions de produits, et la catégorisation manuelle des nouveaux articles est lente et sujette aux erreurs. Ils emploient un service d'étiquetage de données pour classer un vaste ensemble de données d'images et de descriptions de produits. Le service utilise une combinaison d'annotateurs humains et de pré-étiquetage assisté par IA pour classer efficacement les produits dans une taxonomie détaillée. Ces données étiquetées sont ensuite utilisées pour entraîner un modèle d'apprentissage automatique qui attribue automatiquement des catégories aux nouveaux produits téléchargés sur le site, réduisant considérablement l'effort manuel, améliorant la pertinence de la recherche et optimisant l'expérience d'achat du client.
Gestion des Ensembles de Données pour la Reproductibilité des Modèles NLP
Un laboratoire de recherche en IA développe un nouveau modèle de langage et doit effectuer des centaines d'expériences avec différentes versions de son corpus de texte. Pour garantir la reproductibilité de leurs résultats, ils utilisent une plateforme de gestion et de versionnement de données. Cet outil leur permet de suivre chaque modification de l'ensemble de données, de lier des versions spécifiques de l'ensemble de données aux exécutions d'entraînement du modèle et de revenir facilement aux états précédents. Il agit comme un 'Git pour les données', fournissant une piste d'audit claire et évitant la confusion. Cette approche systématique est vitale pour la recherche collaborative et pour la publication de résultats scientifiques vérifiables.
Audit des Ensembles de Données pour les Biais dans les Algorithmes de Recrutement
Une entreprise de technologie des ressources humaines construit un outil d'IA pour aider à trier les CV. Pour éviter de perpétuer les biais historiques, ils utilisent un outil d'assurance qualité des données pour auditer leur ensemble de données d'entraînement. L'outil analyse la distribution des données démographiques (par ex., sexe, origine ethnique) et identifie les déséquilibres ou corrélations potentiels qui pourraient conduire à des résultats inéquitables. Il fournit des visualisations et des rapports statistiques qui aident l'équipe de science des données à identifier et à atténuer les biais avant l'entraînement du modèle. Cette étape proactive est essentielle pour développer des systèmes d'IA responsables et éthiques qui promeuvent des pratiques de recrutement équitables.