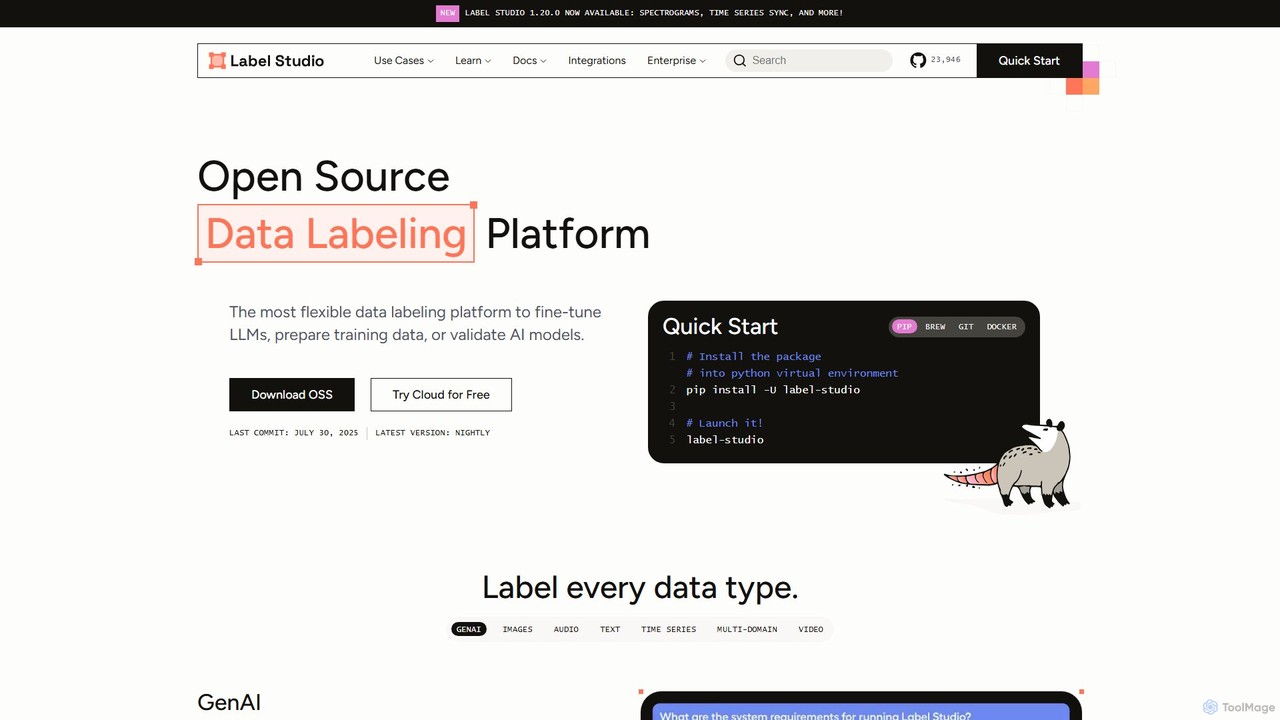
Label Studio
Label Studio est une plateforme polyvalente d'étiquetage de données open source conçue pour une large gamme de types …
Label Studio est une plateforme polyvalente d'étiquetage de données open source conçue pour une large gamme de types de données. Elle permet aux utilisateurs d'annoter des images, du texte, de l'audio, de la vidéo et des données de séries chronologiques pour affiner les LLM, préparer des données d'entraînement pour l'apprentissage automatique et valider les modèles d'IA avec une rétroaction humaine dans la boucle.
À propos de Données d'entraînement
Les outils de Données d'entraînement sont des plateformes spécialisées alimentées par l'IA, conçues pour collecter, annoter et préparer des ensembles de données de haute qualité, essentiels au développement et à l'affinage des modèles d'apprentissage automatique. Ces outils rationalisent la phase initiale cruciale du développement de modèles d'IA en garantissant que les données sont étiquetées et formatées avec précision. Ils permettent aux praticiens de l'IA de construire des modèles robustes qui fonctionnent de manière fiable dans diverses applications, de la vision par ordinateur au traitement du langage naturel.
Fonctionnalités Clés
- Collecte et Sourcing de Données: Facilite la collecte de données brutes diverses et pertinentes provenant de diverses sources.
- Annotation et Étiquetage de Données: Fournit des interfaces et des fonctionnalités assistées par l'IA pour le marquage, la catégorisation et la segmentation précis des données.
- Augmentation de Données: Génère des données synthétiques ou modifie des données existantes pour augmenter la taille et la diversité de l'ensemble de données.
- Assurance Qualité et Validation: Met en œuvre des mécanismes pour vérifier la précision de l'annotation et la cohérence des données.
- Gestion et Versioning des Données: Suit les modifications apportées aux ensembles de données, assurant la reproductibilité et les flux de travail collaboratifs.
Cas d'Utilisation
Ces outils sont indispensables pour les chercheurs en IA, les data scientists et les ingénieurs en apprentissage automatique. Ils sont utilisés pour préparer des ensembles de données pour l'entraînement de modèles de vision par ordinateur pour la détection d'objets, l'annotation de texte pour la compréhension du langage naturel, ou l'étiquetage de données de capteurs pour les systèmes de conduite autonome. L'objectif est de transformer les informations brutes en formats structurés et utilisables pour l'ingestion par le modèle.
Comment Choisir
Lors de la sélection d'une plateforme de données d'entraînement, tenez compte des types de données que vous devez traiter (images, texte, audio, vidéo), de la complexité des tâches d'annotation et des exigences d'évolutivité pour les grands ensembles de données. Évaluez ses capacités d'intégration avec les pipelines ML existants, le niveau d'automatisation offert pour l'annotation et la robustesse de ses fonctionnalités de contrôle qualité. Les modèles de tarification et le support des flux de travail collaboratifs sont également des facteurs importants.
Données d'entraînementCas d'utilisation
Annotation d'Images pour les Modèles de Vision par Ordinateur
Un ingénieur en apprentissage automatique doit entraîner un modèle de détection d'objets pour les véhicules autonomes. Il utilise une plateforme de données d'entraînement pour étiqueter précisément des milliers d'images avec des boîtes englobantes autour des piétons, des véhicules et des panneaux de signalisation. Cette annotation détaillée garantit que le modèle identifie et localise avec précision les objets dans des scénarios de conduite réels, ce qui est crucial pour la sécurité et la performance.
Préparation de Données Textuelles pour le Traitement du Langage Naturel
Un data scientist construit un modèle NLP pour l'analyse des sentiments des avis clients. Il utilise des outils de données d'entraînement pour annoter des données textuelles, catégorisant les phrases ou expressions comme positives, négatives ou neutres. Ce processus implique l'identification des entités clés et des relations au sein du texte, permettant au modèle de comprendre et de classer avec précision le ton émotionnel des retours clients.
Génération de Données Synthétiques pour les Scénarios Rares
Dans des secteurs comme la santé ou la finance, les données réelles pour des événements rares mais critiques (par exemple, des épidémies spécifiques, des schémas de fraude) sont rares. Les ingénieurs de données utilisent des outils de données d'entraînement avec des capacités d'augmentation pour générer des données synthétiques qui imitent ces scénarios rares. Cela élargit l'ensemble de données, permettant aux modèles d'IA d'être entraînés sur un éventail plus complet de situations, améliorant leur capacité à détecter et à réagir aux anomalies.
Transcription et Annotation Audio pour la Reconnaissance Vocale
Une entreprise développant un assistant vocal a besoin de données audio de haute qualité pour l'entraînement. Elle utilise des outils de données d'entraînement pour transcrire le langage parlé en texte et annoter des éléments spécifiques comme les tours de parole, le bruit de fond ou le ton émotionnel. Ce processus méticuleux garantit que le modèle de reconnaissance vocale peut convertir avec précision diverses entrées audio en texte, améliorant la compréhension et la réactivité de l'assistant.
Validation et Nettoyage des Ensembles de Données pour la Robustesse du Modèle
Avant de déployer un modèle d'IA, un spécialiste de la qualité des données utilise des outils de données d'entraînement pour valider et nettoyer les ensembles de données préparés. Cela implique d'identifier et de corriger les incohérences, de supprimer les entrées en double et de gérer les valeurs manquantes. S'assurer que les données sont propres et précises empêche le modèle d'apprendre des schémas erronés, ce qui conduit à des performances de système d'IA plus robustes, équitables et fiables dans les environnements de production.
Préparation de Données Géospatiales pour la Surveillance Environnementale
Les scientifiques de l'environnement utilisent des outils de données d'entraînement pour traiter et étiqueter des données géospatiales, telles que des images satellite ou des séquences de drones, pour les modèles d'IA qui surveillent la déforestation, l'expansion urbaine ou les impacts du changement climatique. Cela implique de segmenter les types de couverture terrestre, d'identifier des caractéristiques spécifiques et de suivre les changements au fil du temps. Des données géospatiales étiquetées de haute qualité sont essentielles pour développer des modèles prédictifs précis pour la conservation de l'environnement et la gestion des ressources.