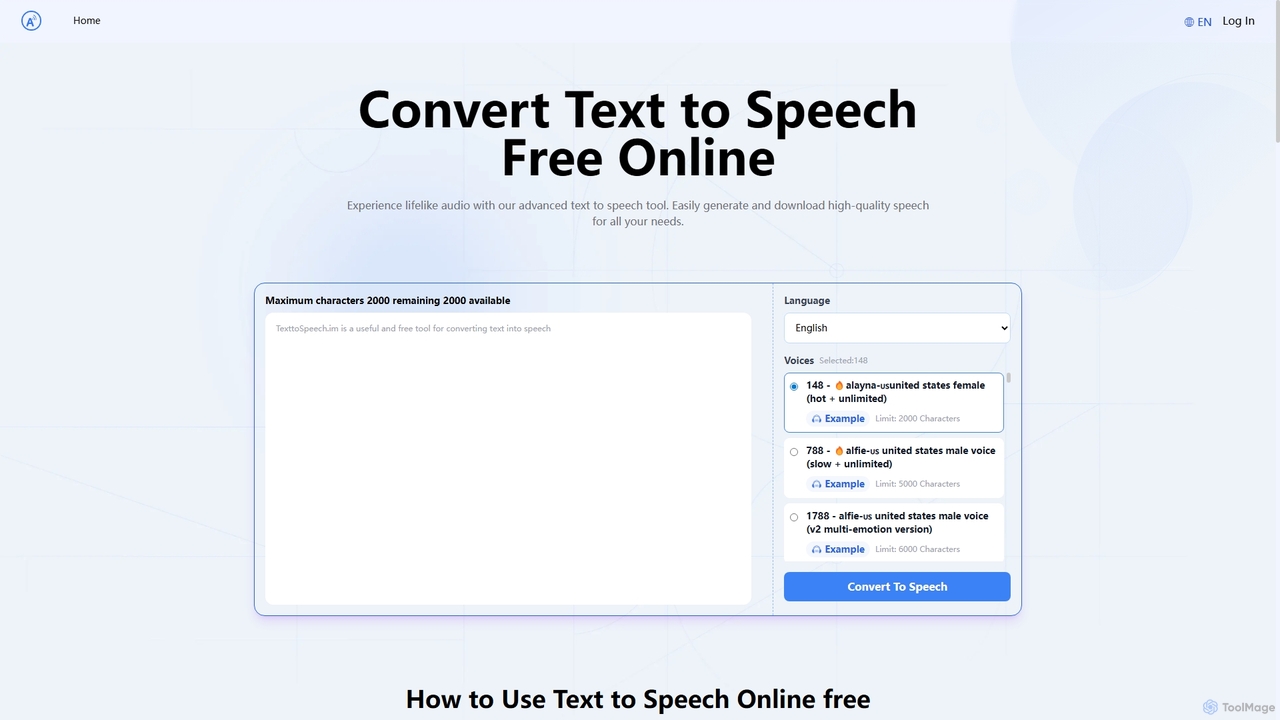
Text to Speech.im
Text to Speech.im est un outil d'IA en ligne gratuit qui convertit le texte en parole au son …
Text to Speech.im est un outil d'IA en ligne gratuit qui convertit le texte en parole au son naturel. Il prend en charge une vaste gamme de langues et de voix, permettant aux utilisateurs de générer un son de haute qualité pour les vidéos, l'e-learning, l'accessibilité, et plus encore. Personnalisez la vitesse et le volume de la voix, puis téléchargez facilement l'audio généré en tant que fichier MP3.

Voice Isolator
Voice Isolator est une suite audio complète alimentée par l'IA, conçue pour une qualité sonore irréprochable. Il excelle …
Voice Isolator est une suite audio complète alimentée par l'IA, conçue pour une qualité sonore irréprochable. Il excelle dans la suppression du bruit de fond, l'isolation des voix et des instruments de n'importe quelle piste, le nettoyage des enregistrements vocaux pour plus de clarté et la génération de parole au son naturel à partir de texte. Idéal pour les podcasteurs, les musiciens et les créateurs de contenu à la recherche d'un traitement audio de qualité professionnelle avec une interface web simple, rapide et intuitive.
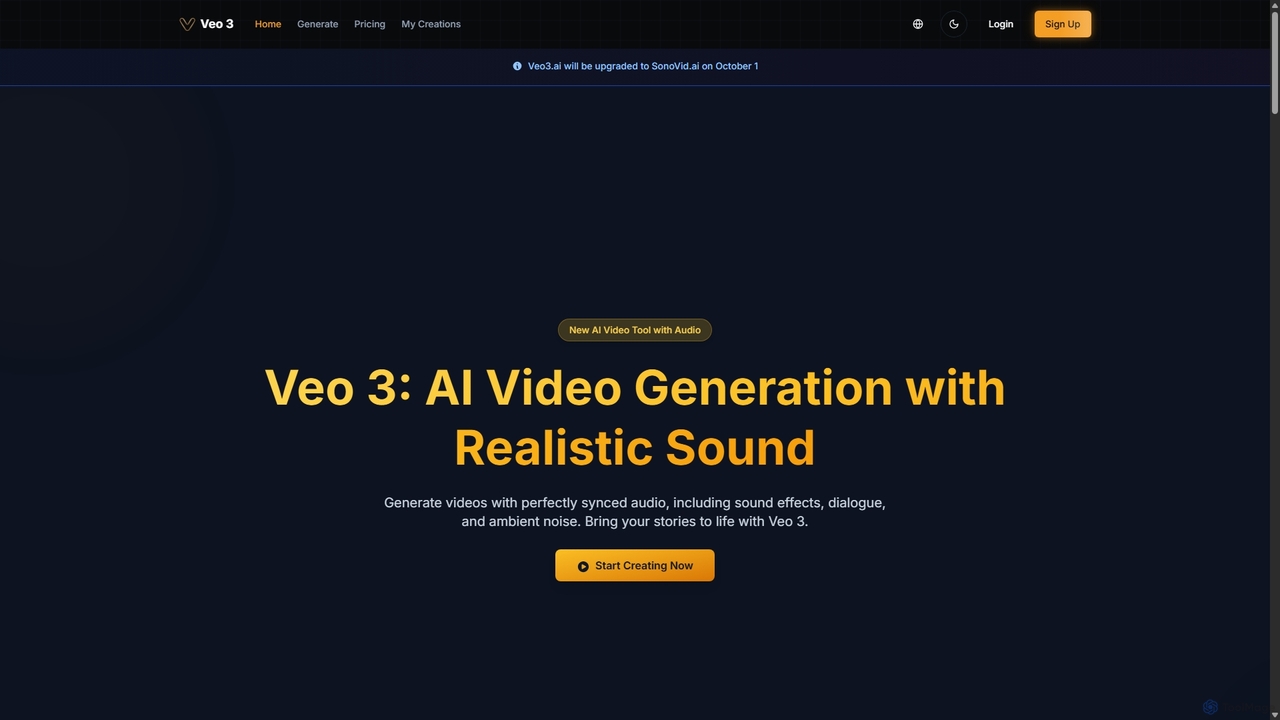
Veo 3
Veo 3 est un générateur de vidéos par IA avancé, alimenté par le modèle Veo 3 de Google. …
Veo 3 est un générateur de vidéos par IA avancé, alimenté par le modèle Veo 3 de Google. Il se spécialise dans la création de vidéos 1080p de haute qualité, d'une durée maximale de 8 secondes, avec un son parfaitement synchronisé et généré nativement. Les utilisateurs peuvent générer du contenu à partir de prompts textuels ou d'images, avec des dialogues réalistes, des effets sonores, des bruits d'ambiance et une synchronisation labiale précise, ce qui le rend idéal pour les créateurs et les spécialistes du marketing.
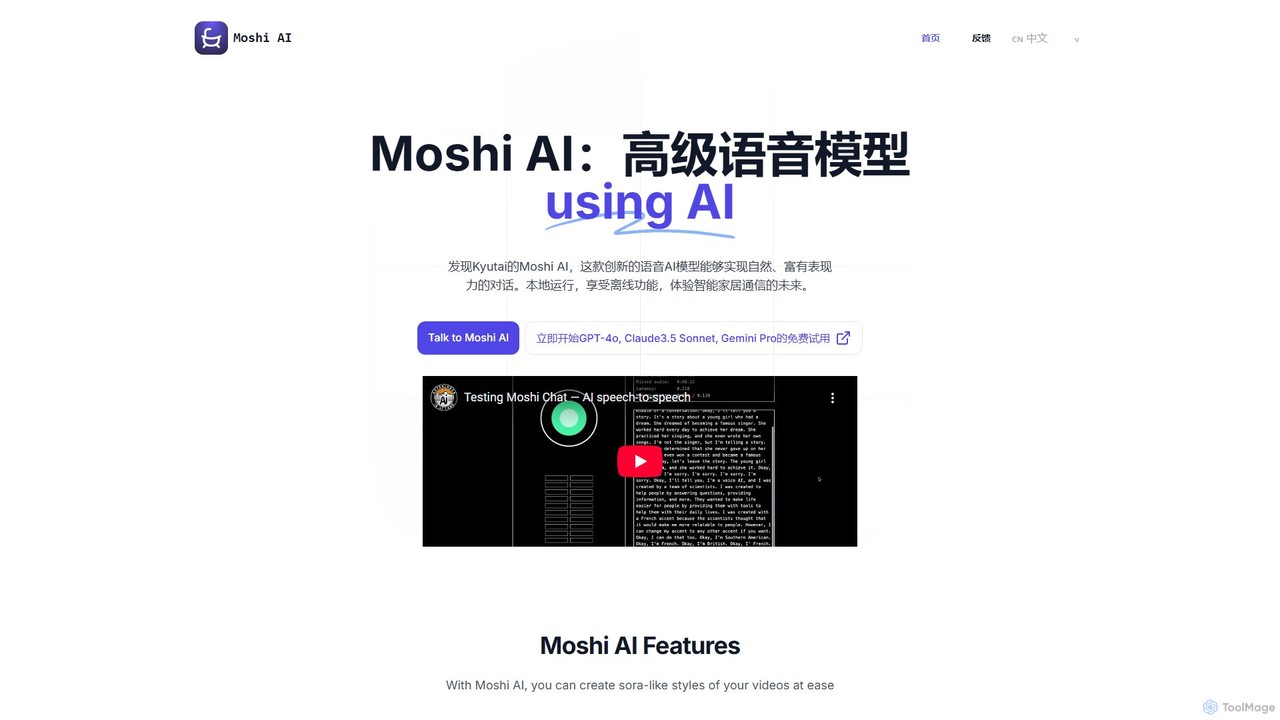
Moshi AI
Moshi AI est un modèle d'IA vocale conversationnelle avancé à faible latence développé par Kyutai. Il permet des …
Moshi AI est un modèle d'IA vocale conversationnelle avancé à faible latence développé par Kyutai. Il permet des dialogues naturels, expressifs et interruptibles, conçu pour fonctionner localement sur divers matériels pour une utilisation hors ligne. Cela le rend idéal pour les applications axées sur la confidentialité comme les appareils domestiques intelligents et les systèmes embarqués.
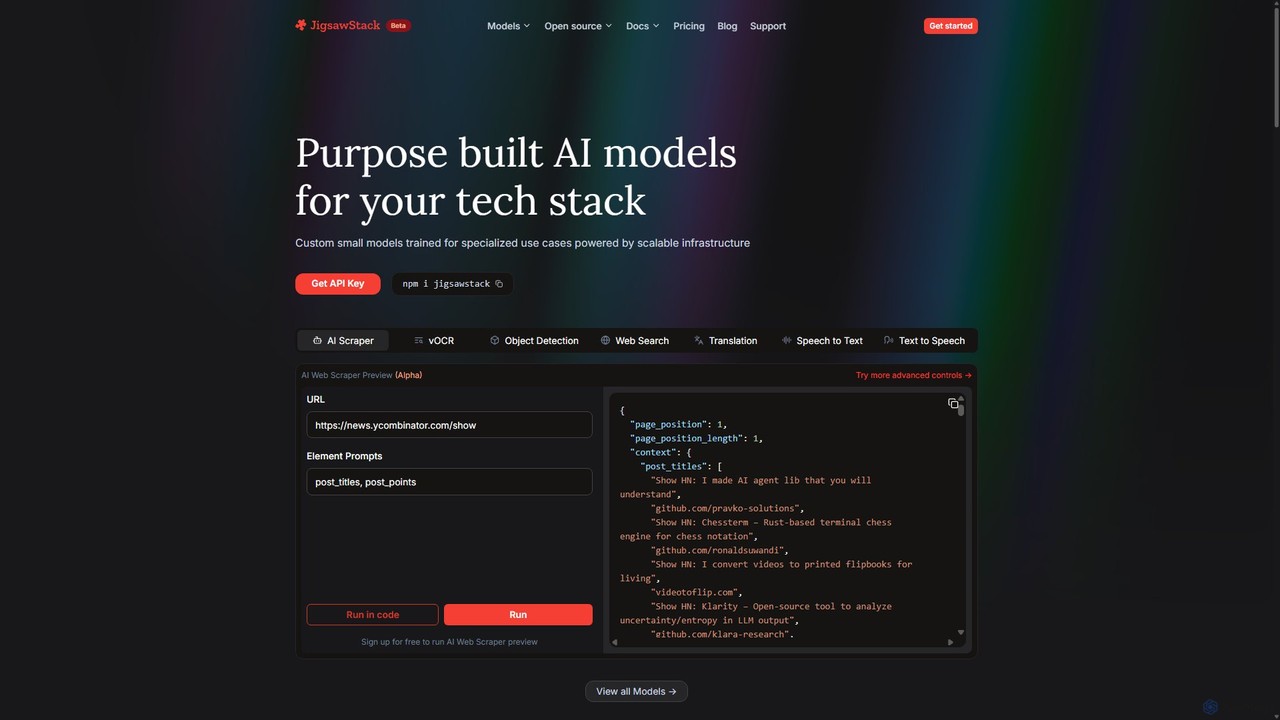
JigsawStack
JigsawStack propose une suite de petits modèles d'IA spécialisés pour les développeurs, accessibles via une seule API. Il …
JigsawStack propose une suite de petits modèles d'IA spécialisés pour les développeurs, accessibles via une seule API. Il simplifie les tâches backend complexes comme le web scraping, l'OCR, la traduction et la conversion de la parole en texte avec une infrastructure rapide, fiable et évolutive. Conçu pour une intégration transparente, il offre une expérience axée sur le développeur, avec une sortie de données structurées et un support mondial, permettant aux équipes de créer et de livrer des fonctionnalités plus rapidement.
Speechllect
Speechllect est une plateforme avancée de conversion de la parole en texte (STT) et du texte en parole …
Speechllect est une plateforme avancée de conversion de la parole en texte (STT) et du texte en parole (TTS) alimentée par l'IA. Elle utilise une "Théorie du Sens" unique pour non seulement transcrire et synthétiser la parole, mais aussi pour comprendre et générer le ton et l'intonation émotionnels. Cela la rend idéale pour créer des interactions vocales humaines pour les entreprises, les développeurs et les créateurs de contenu.
TextSynth
TextSynth offre aux développeurs un accès puissant et économique à une suite de modèles d'IA, y compris de …
TextSynth offre aux développeurs un accès puissant et économique à une suite de modèles d'IA, y compris de grands modèles de langage (LLM), de la conversion texte-image, texte-parole et parole-texte, via une API REST flexible et un terrain de jeu interactif. Il propose des modèles comme Llama, Mistral, Stable Diffusion et Whisper, optimisés pour la vitesse et l'accessibilité.
WaveSpeedAI
WaveSpeedAI est une plateforme API unifiée et haute performance conçue pour accélérer la génération d'images, de vidéos et …
WaveSpeedAI est une plateforme API unifiée et haute performance conçue pour accélérer la génération d'images, de vidéos et d'audio par l'IA. Elle offre aux développeurs et aux créateurs un point d'accès unique à une vaste bibliothèque de modèles de pointe de fournisseurs tels que Google, ByteDance et Kuaishou, permettant de construire, créer et mettre à l'échelle plus rapidement des applications d'IA multimodales.
ChattyTutor
ChattyTutor est un tuteur linguistique IA hautement configurable, alimenté par GPT et spécialement optimisé pour les apprenants de …
ChattyTutor est un tuteur linguistique IA hautement configurable, alimenté par GPT et spécialement optimisé pour les apprenants de l'anglais. Il propose des fonctionnalités interactives comme le "dialogue shadowing", l'évaluation de la prononciation et la construction de vocabulaire avec des images générées par IA, disponible sur macOS et les navigateurs web.
Kippy
Kippy est un tuteur de langue IA conçu pour vous aider à maîtriser l'expression orale et la prononciation. …
Kippy est un tuteur de langue IA conçu pour vous aider à maîtriser l'expression orale et la prononciation. Pratiquez des conversations réelles dans 10 langues avec des retours instantanés, une correction grammaticale et des réponses guidées pour développer votre fluidité et votre confiance. C'est le complément parfait pour les apprenants qui veulent dépasser les manuels et commencer à parler naturellement.
Text Generator
Text Generator est une plateforme d'IA polyvalente et très abordable offrant une génération illimitée de texte, de code …
Text Generator est une plateforme d'IA polyvalente et très abordable offrant une génération illimitée de texte, de code et de parole. Elle fournit une API puissante, incluant un point de terminaison compatible avec OpenAI pour une migration facile, ce qui en fait une solution rentable pour les développeurs, les marketeurs et les créateurs de contenu.

MiniMax
MiniMax est une société de recherche en IA fournissant une plateforme complète de modèles de fondation alimentés par …
MiniMax est une société de recherche en IA fournissant une plateforme complète de modèles de fondation alimentés par l'AGI. Elle propose des API de pointe pour le texte (MiniMax-M1 avec 1M de contexte), la vidéo (Hailuo 02) et la parole (Speech 02), ainsi qu'une suite d'applications natives IA gratuites comme MiniMax Chat, Agent et des outils créatifs. Elle se concentre sur la haute performance, l'efficacité de calcul et la rentabilité pour les développeurs et les utilisateurs finaux.
À propos de Synthèse vocale
Les outils de Synthèse Vocale sont des technologies basées sur l'IA qui convertissent le texte écrit en parole humaine au son naturel. Ces systèmes utilisent des modèles d'apprentissage profond avancés et des réseaux neuronaux pour générer une sortie audio avec des voix, des émotions et des langues personnalisables. Ils sont largement utilisés pour automatiser les voix off, améliorer les fonctionnalités d'accessibilité et créer des expériences utilisateur interactives sur diverses plateformes numériques.
Fonctionnalités Clés
- Text-to-Speech (TTS) : Convertit le texte d'entrée en audio parlé, souvent avec des options pour différentes voix et styles de parole.
- Personnalisation Vocale : Permet aux utilisateurs de choisir parmi une gamme de voix prédéfinies ou même de créer des profils vocaux personnalisés pour correspondre à des identités de marque spécifiques.
- Prise en Charge Multilingue : Génère de la parole dans de nombreuses langues et dialectes, répondant aux publics mondiaux et aux divers besoins en contenu.
- Expression Émotionnelle : Incorpore des nuances émotionnelles comme la joie, la tristesse ou la colère dans la parole synthétisée, rendant les interactions plus réalistes.
- Prise en Charge SSML (Speech Synthesis Markup Language) : Offre un contrôle précis sur la prononciation, l'emphase, les pauses et le débit de parole pour une sortie audio hautement personnalisée.
Scénarios d'Application
Les outils de Synthèse Vocale sont inestimables pour les créateurs de contenu, les développeurs et les entreprises. Ils permettent la production rapide de contenu audio pour les modules d'e-learning, les podcasts et les narrations vidéo. Les développeurs intègrent ces outils pour créer des applications accessibles aux utilisateurs malvoyants ou pour concevoir des interfaces vocales plus engageantes pour les appareils intelligents et les chatbots.
Comment Choisir
Lors de la sélection d'un outil de Synthèse Vocale, tenez compte du naturel et de la qualité des voix générées, de l'étendue du support linguistique et des accents, ainsi que de la disponibilité de l'expression émotionnelle. Évaluez la facilité d'intégration via les API, la flexibilité des options de personnalisation vocale et le modèle de tarification basé sur votre volume d'utilisation et vos exigences spécifiques en matière de fonctionnalités.
Synthèse vocaleCas d'utilisation
Automatisation de la Narration d'Audiolivres et de Podcasts
Les créateurs de contenu et les éditeurs peuvent utiliser des outils de synthèse vocale pour convertir rapidement des manuscrits écrits en livres audio ou épisodes de podcast de haute qualité. En sélectionnant une voix appropriée et en ajustant des paramètres comme le rythme et le ton, ils peuvent produire un contenu audio engageant sans avoir recours à des acteurs vocaux humains, réduisant considérablement le temps et les coûts de production tout en élargissant leur portée d'audience.
Amélioration de l'Accessibilité pour les Utilisateurs Malvoyants
Les développeurs intègrent des API de synthèse vocale dans les applications, les sites web et les systèmes d'exploitation pour offrir des capacités de lecture d'écran. Cela permet aux utilisateurs malvoyants de faire lire à haute voix le contenu textuel numérique, comme des articles, des e-mails ou des instructions de navigation. Cette application améliore considérablement l'accessibilité numérique et l'inclusion, permettant à un public plus large d'interagir avec l'information de manière autonome.
Création de Voix Off pour Contenu Vidéo et E-learning
Les producteurs vidéo et les créateurs de cours d'e-learning utilisent la synthèse vocale pour générer des voix off au son professionnel pour leurs projets multimédias. Au lieu d'engager des talents vocaux ou de s'enregistrer, ils peuvent saisir des scripts et recevoir des fichiers audio dans différentes langues et voix. Cela simplifie le processus de localisation pour le contenu mondial et assure une qualité vocale constante sur tous les modules d'apprentissage ou segments vidéo.
Développement de Systèmes de Réponse Vocale Interactive (IVR)
Les entreprises exploitent la synthèse vocale pour alimenter leurs systèmes de Réponse Vocale Interactive (IVR), offrant un service client et un support automatisés. Au lieu de pré-enregistrer chaque phrase possible, les entreprises peuvent générer dynamiquement des réponses basées sur les requêtes des clients. Cela assure une voix de marque cohérente, réduit le besoin de vastes bibliothèques de talents vocaux et permet des mises à jour rapides des scripts IVR, améliorant l'expérience client et l'efficacité opérationnelle.
Création d'Alertes et de Notifications Vocales Dynamiques
Les applications et les appareils intelligents peuvent utiliser la synthèse vocale pour générer des alertes et des notifications vocales en temps réel pour les utilisateurs. Par exemple, un système de maison intelligente peut annoncer l'ouverture d'une porte, ou une application de navigation peut fournir des directions étape par étape. Cela offre aux utilisateurs un moyen mains libres et sans les yeux pour recevoir des informations critiques, améliorant la commodité et la sécurité dans divers contextes, de la conduite aux tâches ménagères quotidiennes.
Personnalisation des Assistants Numériques et Chatbots
Les développeurs et les chefs de produit utilisent la synthèse vocale pour donner aux assistants numériques (comme Siri ou Alexa) et aux chatbots des voix et des personnalités uniques et reconnaissables. En personnalisant la voix, le ton et même les inflexions émotionnelles, ils peuvent créer une expérience d'interaction plus engageante et humaine. Cette personnalisation contribue à renforcer la confiance des utilisateurs et rend la technologie plus intuitive et moins robotique, améliorant la satisfaction globale des utilisateurs.