Tygra
Tygra est un outil de traitement de documents par IA axé sur la confidentialité qui fonctionne entièrement sur …
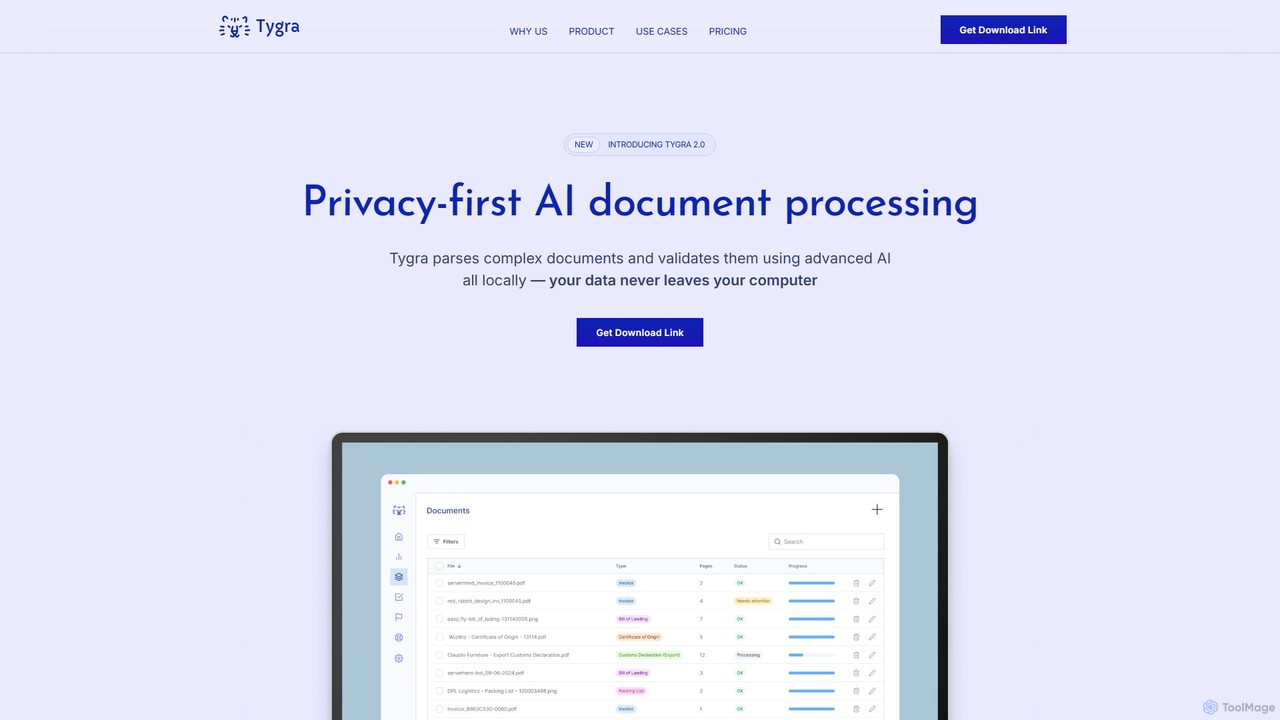
Tygra est un outil de traitement de documents par IA axé sur la confidentialité qui fonctionne entièrement sur votre machine locale. Il analyse, extrait et valide automatiquement les données de documents tels que les PDF, JPG et PNG sans que vos informations sensibles ne quittent jamais votre ordinateur, garantissant une sécurité et une conformité maximales.
À propos de Extraction de données
Les outils d'Extraction de données sont des applications basées sur l'IA conçues pour identifier et extraire automatiquement des informations spécifiques à partir de sources non structurées ou semi-structurées. Ils utilisent des technologies telles que la Reconnaissance Optique de Caractères (OCR) et le Traitement du Langage Naturel (NLP) pour analyser des sites web, des PDF, des images et des documents. Cette automatisation transforme le processus fastidieux de collecte manuelle de données, permettant aux entreprises de recueillir efficacement des informations sur le marché, des données financières ou des commentaires de clients pour analyse. Contrairement aux scrapers traditionnels, ces outils d'IA peuvent comprendre le contexte et s'adapter à des mises en page de données complexes ou changeantes avec une plus grande précision.
Fonctionnalités Clés
- Web Scraping Automatisé : Extrait des données de sites web dynamiques, gérant les connexions, la pagination et les éléments JavaScript complexes.
- Traitement de Documents (OCR) : Reconnaît et extrait du texte, des tableaux et des paires clé-valeur à partir de documents numérisés, de PDF et d'images.
- Sortie de Données Structurées : Convertit les données extraites non structurées en formats organisés comme JSON, CSV ou Excel pour une analyse facile.
- Traitement du Langage Naturel (NLP) : Identifie et extrait des entités spécifiques telles que des noms, des dates, des lieux ou des sentiments à partir de blocs de texte.
- Extraction Programmée et Évolutive : Permet aux utilisateurs de configurer des tâches d'extraction récurrentes et de traiter de grands volumes de sources de données en parallèle.
Cas d'Utilisation
Ces outils sont largement utilisés dans les études de marché pour la surveillance des prix des concurrents, dans la vente pour la génération automatisée de prospects à partir d'annuaires en ligne, et dans la finance pour extraire des données de factures et de rapports financiers. Ils sont également précieux pour l'agrégation de contenu, la recherche universitaire et tout flux de travail nécessitant la conversion de grandes quantités d'informations non structurées en données structurées et exploitables.
Comment Choisir
Lors de la sélection d'un outil d'Extraction de données, tenez compte des types de sources de données que vous devez traiter (sites web, PDF, API). Évaluez l'interface utilisateur — s'il s'agit d'une solution sans code de type pointer-cliquer ou si elle nécessite des connaissances en programmation. Évaluez son évolutivité pour gérer de grands volumes de données et vérifiez les formats de sortie disponibles (par exemple, CSV, JSON, intégration API). Enfin, considérez la capacité de l'outil à gérer des scénarios complexes comme les mesures anti-scraping ou les mises en page de documents irrégulières.
Extraction de donnéesCas d'utilisation
Surveillance des Prix des Concurrents en E-commerce
Un responsable e-commerce doit maintenir des prix compétitifs. Il utilise un outil d'extraction de données pour scraper automatiquement les prix des produits, la disponibilité des stocks et les avis clients de dizaines de sites web concurrents chaque jour. L'outil est programmé pour s'exécuter chaque matin, et les données extraites sont exportées directement dans un fichier CSV. Cela permet à l'équipe de tarification d'analyser le paysage du marché dans un tableau de bord et d'ajuster ses propres prix de manière dynamique, maximisant ainsi les ventes et les marges bénéficiaires sans des heures de recherche manuelle.
Saisie Automatisée des Données de Factures
Un service comptable reçoit des centaines de factures au format PDF par e-mail chaque semaine. La saisie manuelle des données de ces factures dans leur logiciel de comptabilité est chronophage et sujette aux erreurs. Ils mettent en œuvre un outil d'extraction de données avec des capacités OCR. L'outil surveille automatiquement une boîte de réception d'e-mails, extrait des informations clés comme le numéro de facture, le nom du fournisseur, le montant dû et la date de chaque pièce jointe PDF, puis utilise une API pour pousser ces données structurées directement dans le système comptable. Cela réduit la saisie manuelle des données de plus de 90% et améliore la précision.
Génération de Prospects pour les Équipes de Vente
Une équipe de vente B2B doit constituer une liste de clients potentiels dans le secteur manufacturier. Au lieu de parcourir manuellement les annuaires d'entreprises en ligne et les réseaux professionnels, ils utilisent un outil d'extraction de données. Ils le configurent pour crawler des sites web spécifiques, à la recherche d'entreprises correspondant à leurs critères (par exemple, emplacement, taille, secteur). L'outil extrait les noms d'entreprises, les sites web, les numéros de téléphone, ainsi que les noms et titres des contacts. La liste structurée résultante est ensuite importée dans leur CRM, fournissant à l'équipe de vente une source riche de prospects qualifiés et économisant des dizaines d'heures de prospection chaque semaine.
Agrégation d'Annonces Immobilières
Un analyste immobilier souhaite créer une base de données complète des annonces immobilières dans une ville spécifique. Il utilise un outil d'extraction de données pour scraper les informations de plusieurs sites web immobiliers. L'outil est configuré pour extraire les détails de chaque annonce, y compris l'adresse, le prix, le nombre de chambres, la superficie et les coordonnées de l'agent. En programmant l'outil pour qu'il s'exécute quotidiennement, l'analyste maintient une base de données à jour, qu'il utilise pour identifier les tendances du marché, générer des rapports d'évaluation et fournir aux clients les informations immobilières les plus récentes disponibles.
Étude de Marché et Analyse des Sentiments
Une équipe de marketing produit lance un nouveau produit et souhaite comprendre la perception du public. Elle utilise un outil d'extraction de données avec des capacités de NLP pour recueillir des milliers d'avis de clients, de commentaires sur les réseaux sociaux et de publications sur des forums liés à des produits similaires. L'outil n'extrait pas seulement le texte brut, mais analyse également le sentiment (positif, négatif, neutre) et identifie les sujets clés discutés (par exemple, 'autonomie de la batterie', 'prix', 'service client'). Cela fournit à l'équipe des informations structurées et exploitables sur les besoins et les points de douleur des consommateurs, les aidant à affiner leur message marketing et leur stratégie produit.
Collecte de Données pour la Recherche Académique
Un chercheur universitaire mène une méta-analyse qui nécessite des données provenant de centaines d'articles scientifiques publiés. Trouver et extraire manuellement des points de données spécifiques (comme la taille des échantillons, les résultats statistiques et les méthodologies) de chaque PDF est une tâche monumentale. En utilisant un outil d'extraction de données, le chercheur peut traiter par lots l'ensemble de la collection de PDF. Les capacités d'OCR et de reconnaissance de formes de l'outil sont entraînées pour identifier et extraire les données requises dans une feuille de calcul structurée. Cela automatise la partie la plus laborieuse de la recherche, permettant au chercheur de se concentrer sur l'analyse et l'interprétation.