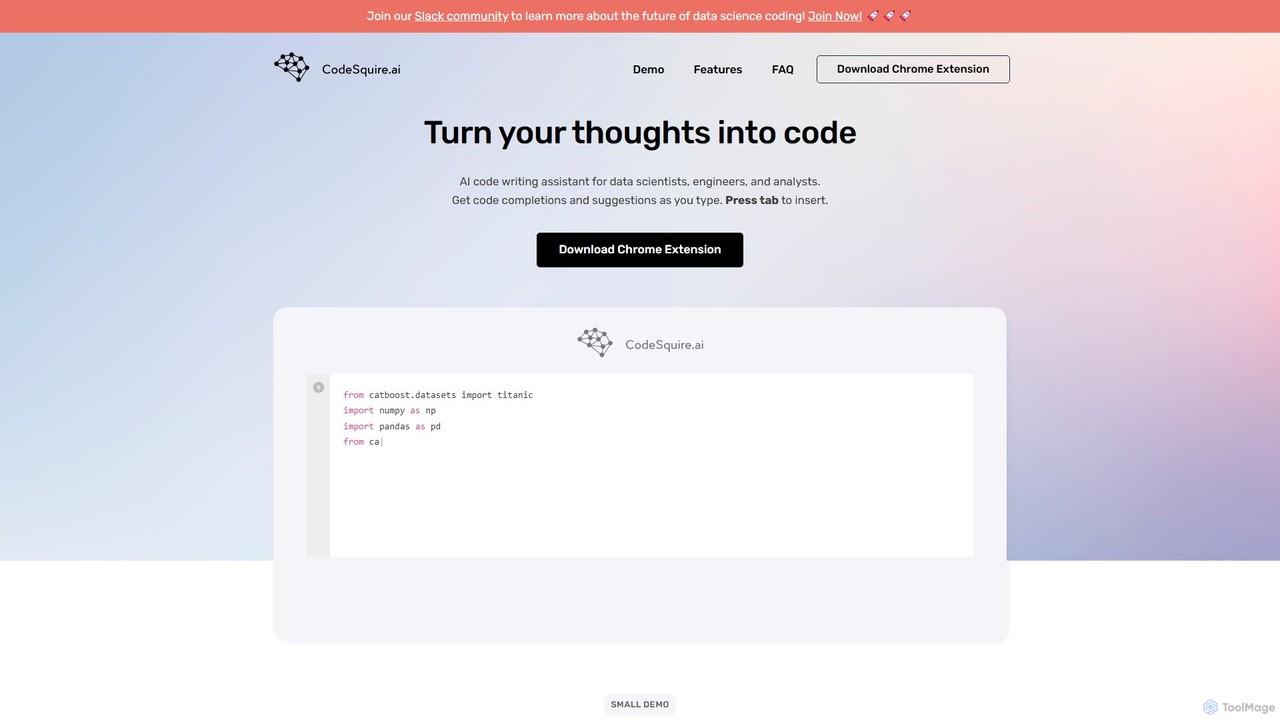
CodeSquire
CodeSquire est un assistant d'écriture de code alimenté par l'IA, conçu pour les data scientists, les ingénieurs et …
CodeSquire est un assistant d'écriture de code alimenté par l'IA, conçu pour les data scientists, les ingénieurs et les analystes. Il accélère le développement en transformant les commentaires en langage naturel en code, en générant des fonctions complexes, en écrivant des requêtes SQL et en fournissant des complétions de code intelligentes directement dans vos environnements web préférés.
À propos de Apprentissage Automatique
Les outils d'Apprentissage Automatique (Machine Learning, ML) sont une catégorie spécialisée de logiciels conçus pour construire, entraîner et déployer des modèles qui apprennent à partir de données pour faire des prédictions ou prendre des décisions. Ces outils utilisent des algorithmes statistiques pour identifier des motifs dans de grands ensembles de données sans être explicitement programmés pour chaque tâche. Ils permettent aux utilisateurs de créer des applications de prévision, de classification et de clustering, transformant les données brutes en intelligence exploitable. En tant que composant essentiel de la Science des Données, l'Apprentissage Automatique se concentre spécifiquement sur les aspects algorithmiques et computationnels de la création de systèmes prédictifs.
Fonctionnalités Clés
- Entraînement et Évaluation de Modèles : Fournit des environnements et des bibliothèques pour entraîner des algorithmes sur des données et évaluer leurs performances avec des métriques comme l'exactitude et la précision.
- Ingénierie des Caractéristiques : Inclut des fonctionnalités pour transformer, nettoyer et sélectionner les caractéristiques de données les plus pertinentes afin d'améliorer les performances du modèle.
- Bibliothèques d'Algorithmes : Offre une collection d'algorithmes pré-construits pour des tâches telles que la régression, la classification, le clustering et la réduction de dimensionnalité.
- Déploiement et MLOps : Facilite l'intégration des modèles entraînés dans les applications de production et gère leur cycle de vie, y compris la surveillance et le réentraînement.
- Exploration et Visualisation des Données : Outils intégrés pour analyser et visualiser les ensembles de données, aidant à comprendre les distributions et les relations des données avant la modélisation.
Cas d'Utilisation
Les outils d'Apprentissage Automatique sont largement utilisés dans diverses industries. Dans la finance, ils sont essentiels pour la notation de crédit et le trading algorithmique. Les professionnels de la santé les utilisent pour le diagnostic de maladies à partir d'images médicales et la prédiction des résultats des patients. Dans le commerce électronique et le marketing, ces outils alimentent les moteurs de recommandation et les modèles de prédiction de l'attrition client, permettant des expériences utilisateur personnalisées et des campagnes ciblées.
Comment Choisir
Lors de la sélection d'un outil d'Apprentissage Automatique, tenez compte de votre expertise technique ; certaines plateformes offrent des interfaces sans code/low-code (AutoML), tandis que d'autres sont centrées sur le code (par ex., les bibliothèques Python). Évaluez la capacité de l'outil à gérer votre volume de données et sa bibliothèque d'algorithmes disponibles pour votre problème spécifique. Évaluez également ses capacités d'intégration avec vos sources de données et environnements de déploiement existants, ainsi que la structure globale des coûts.
Apprentissage AutomatiqueCas d'utilisation
Prédiction de l'Attrition Client pour un Service par Abonnement
Un analyste de données pour une entreprise SaaS doit identifier les clients à haut risque d'annulation de leurs abonnements. En utilisant une plateforme d'apprentissage automatique, il télécharge les données historiques des clients, y compris les modèles d'utilisation, la durée de l'abonnement et l'historique des tickets de support. Il utilise une fonctionnalité AutoML pour tester automatiquement divers algorithmes de classification comme la Régression Logistique et le Gradient Boosting. La plateforme identifie le modèle le plus performant, qui prédit l'attrition avec une précision de 85 %. Cela permet à l'équipe marketing d'engager de manière proactive les clients à risque avec des offres de rétention ciblées, réduisant l'attrition globale de 15 % au trimestre suivant.
Automatisation de l'Analyse d'Images Médicales
Un chercheur en médecine développe un système pour détecter les signes précoces d'une maladie à partir de scanners IRM. En utilisant un framework d'apprentissage automatique avec des capacités d'apprentissage profond, il construit un Réseau de Neurones Convolutifs (CNN). Il entraîne le modèle sur un grand ensemble de données annotées de milliers de scanners. L'outil de ML fournit des fonctionnalités d'augmentation de données pour améliorer la robustesse du modèle. Après l'entraînement et la validation, le modèle déployé peut analyser de nouveaux scanners et mettre en évidence les régions potentiellement anormales avec un haut degré de précision, servant d'outil d'assistance puissant pour les radiologues et accélérant le processus de diagnostic.
Développement d'un Modèle de Prédiction des Prix Immobiliers
Une agence immobilière souhaite fournir des estimations précises de la valeur des biens à ses clients. Un scientifique des données de leur équipe utilise une bibliothèque d'apprentissage automatique comme Scikit-learn dans un environnement de notebook basé sur le cloud. Il rassemble un ensemble de données sur les ventes de biens immobiliers, incluant des caractéristiques telles que la superficie, le nombre de chambres, l'emplacement et l'âge. Il prétraite les données et entraîne plusieurs modèles de régression, tels que la Régression Linéaire et la Forêt Aléatoire, pour prédire les prix de vente. Les fonctionnalités de visualisation de l'outil de ML l'aident à analyser l'importance des caractéristiques et les erreurs du modèle. Le modèle final est intégré au site web de l'agence, fournissant des évaluations immobilières instantanées et basées sur les données.
Création d'un Moteur de Recommandation de Produits Personnalisé
Une plateforme de commerce électronique vise à augmenter l'engagement des utilisateurs et les ventes en affichant des suggestions de produits personnalisées. Un ingénieur ML utilise un service ML cloud pour construire un système de recommandation. Il combine deux approches : le filtrage collaboratif (basé sur ce que des utilisateurs similaires ont aimé) et le filtrage basé sur le contenu (basé sur les attributs du produit). La plateforme fournit une infrastructure gérée pour traiter les journaux d'interaction utilisateur massifs et les catalogues de produits. Après l'entraînement, le modèle est déployé en tant qu'API. Le site web appelle cette API pour obtenir des recommandations en temps réel pour chaque utilisateur, ce qui se traduit par une augmentation de 10 % de la valeur moyenne des commandes et une meilleure satisfaction client.
Mise en Œuvre de la Maintenance Prédictive pour les Machines Industrielles
Le directeur d'une usine de fabrication souhaite minimiser les temps d'arrêt en prédisant les pannes d'équipement avant qu'elles ne surviennent. Un ingénieur ML collecte des données de capteurs (température, vibration, pression) des machines. En utilisant une bibliothèque d'analyse de séries temporelles au sein d'une plateforme ML, il construit un modèle qui apprend les schémas de fonctionnement normaux. Le modèle est entraîné pour détecter les anomalies qui précèdent souvent une panne. Une fois déployé, le système surveille les données des capteurs en temps réel et envoie une alerte à l'équipe de maintenance lorsqu'il prédit une forte probabilité de panne. Cela fait passer la stratégie de maintenance de réactive à proactive, permettant d'économiser des coûts importants et d'améliorer l'efficacité opérationnelle.
Analyse des Sentiments des Retours Clients
Un chef de produit souhaite comprendre l'opinion publique sur une nouvelle fonctionnalité en analysant des milliers d'avis en ligne et de commentaires sur les réseaux sociaux. Il utilise un modèle de Traitement du Langage Naturel (NLP) disponible dans un outil d'apprentissage automatique. Il affine un modèle d'analyse des sentiments pré-entraîné sur un petit ensemble de données spécifique au domaine pour améliorer sa précision. L'outil traite les données textuelles et classe chaque commentaire comme positif, négatif ou neutre. Les résultats agrégés sont affichés sur un tableau de bord, fournissant à l'équipe produit des informations claires et quantitatives sur le sentiment des clients, les aidant à prioriser les futurs efforts de développement.