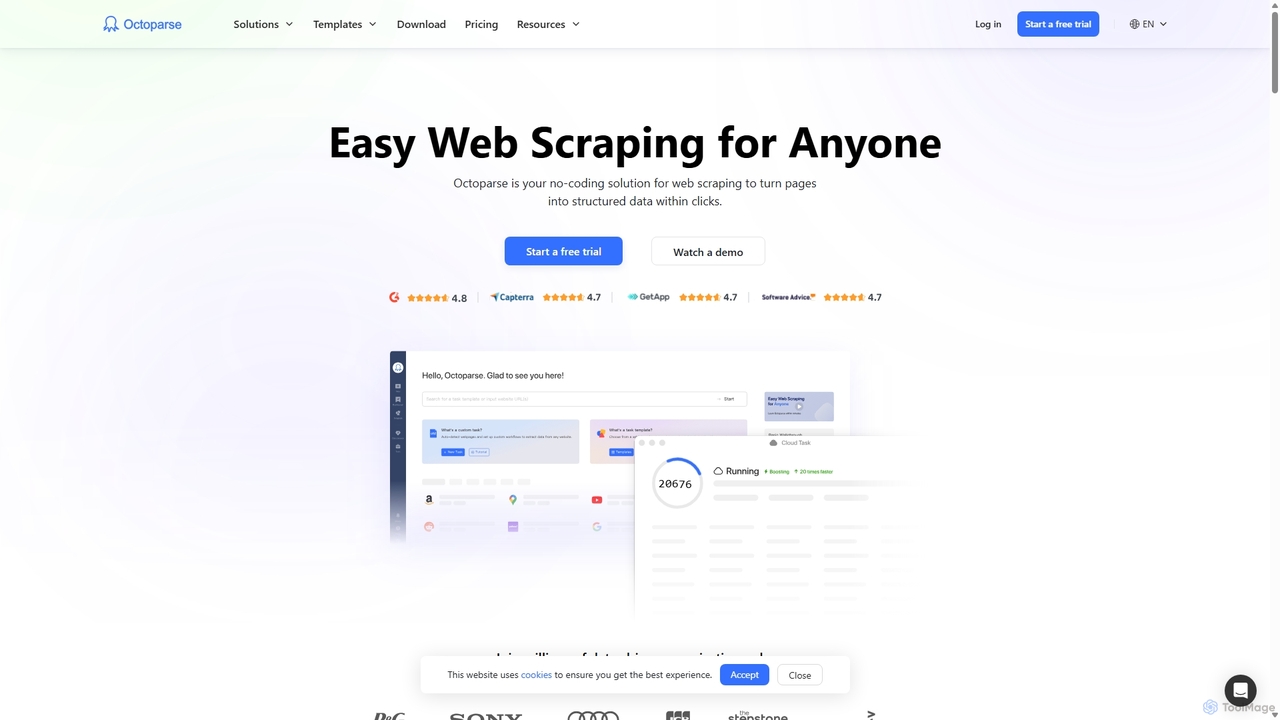
Octoparse
Octoparse est un puissant outil de web scraping sans code qui permet à quiconque d'extraire des données de …
Octoparse est un puissant outil de web scraping sans code qui permet à quiconque d'extraire des données de sites web sans programmation. Il dispose d'un concepteur de flux de travail visuel, d'un assistant IA pour une configuration facile et de centaines de modèles prédéfinis pour les sites populaires. Grâce à l'automatisation basée sur le cloud, à la rotation d'IP et à la résolution de CAPTCHA, Octoparse gère efficacement les tâches de scraping complexes, transformant les pages web en données structurées pour la génération de leads, les études de marché, et plus encore.
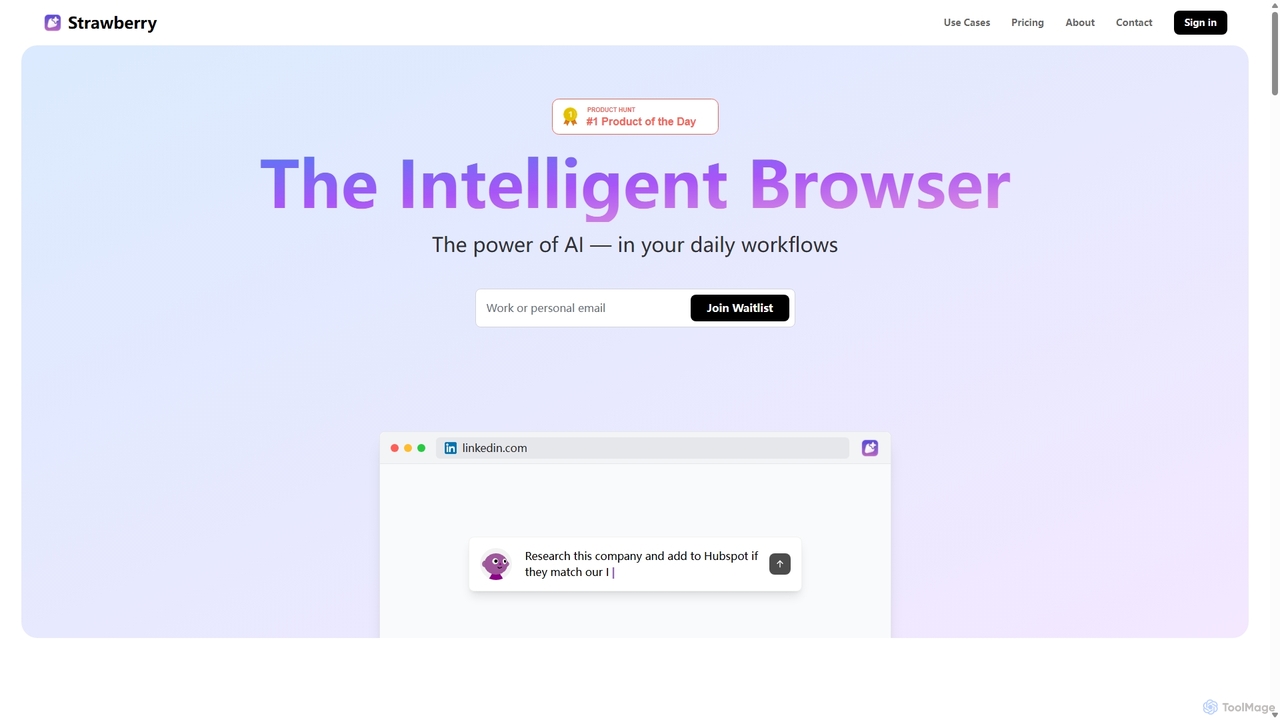
Strawberry Browser
Strawberry Browser est un navigateur intelligent alimenté par l'IA, conçu pour automatiser vos flux de travail quotidiens. Il …
Strawberry Browser est un navigateur intelligent alimenté par l'IA, conçu pour automatiser vos flux de travail quotidiens. Il vous permet de créer une équipe d'assistants IA personnalisables qui gèrent les tâches répétitives comme la recherche, l'extraction de données et la génération de leads directement dans votre navigateur. Éliminez les tâches ingrates, restez concentré et améliorez votre productivité.
Octoparse AI
Octoparse AI est une plateforme sans code pour créer des flux de travail personnalisés alimentés par l'IA et …
Octoparse AI est une plateforme sans code pour créer des flux de travail personnalisés alimentés par l'IA et des robots RPA. Elle permet aux utilisateurs d'automatiser des tâches, d'extraire des données web et de s'intégrer à diverses applications sans écrire de code. Avec une riche bibliothèque d'applications d'automatisation prêtes à l'emploi, elle rationalise les processus de vente, de marketing et de gestion des données, augmentant la productivité des individus et des équipes.
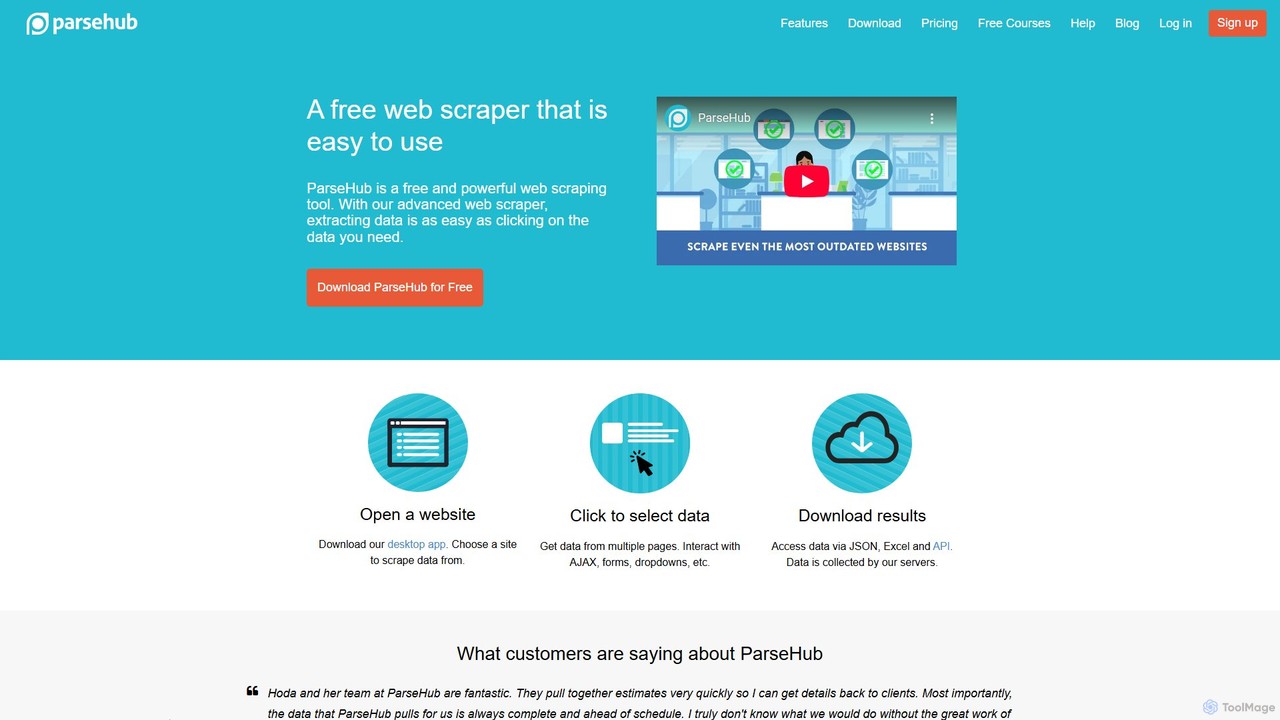
ParseHub
ParseHub est un puissant outil de web scraping sans code qui permet aux utilisateurs d'extraire des données de …
ParseHub est un puissant outil de web scraping sans code qui permet aux utilisateurs d'extraire des données de n'importe quel site web avec une simple interface pointer-cliquer. Il est conçu pour gérer des sites complexes et dynamiques avec JavaScript, AJAX, des formulaires et un défilement infini. Les données peuvent être collectées selon un calendrier, exportées en JSON/Excel ou consultées via une API, ce qui le rend idéal pour la génération de leads, les études de marché et l'agrégation de données.
À propos de Web scraping
Les outils de Web Scraping IA sont des applications conçues pour extraire automatiquement de grands volumes de données à partir de sites web. Ils exploitent l'IA pour naviguer dans des structures de site complexes, gérer les mesures anti-scraping comme les CAPTCHAs, et analyser le HTML non structuré en formats structurés tels que JSON ou CSV. Cela permet aux entreprises et aux chercheurs de collecter des données de marché en temps réel, de surveiller les concurrents et d'agréger des informations sans intervention manuelle. L'IA améliore le scraping traditionnel en s'adaptant aux changements des sites web et en interprétant les mises en page visuelles pour une collecte de données plus robuste.
Fonctionnalités Clés
- Extraction Automatisée de Données : Récolte automatiquement le texte, les images, les prix et d'autres points de données spécifiés à partir de pages web à grande échelle.
- Analyse par IA : Identifie et structure intelligemment les champs de données à partir de mises en page complexes, même lorsque les structures HTML changent.
- Contournement des Anti-Bots : Utilise des techniques comme la rotation de proxys, la simulation d'agents utilisateurs et la résolution de CAPTCHAs pour éviter la détection et le blocage.
- Scraping Planifié : Permet aux utilisateurs de configurer des tâches récurrentes pour collecter des données fraîches à intervalles réguliers (par ex., quotidien, horaire).
- Exportation et Intégration de Données : Exporte les données collectées dans divers formats (CSV, JSON, Excel) et s'intègre à d'autres applications via des API ou des webhooks.
Cas d'Utilisation
Ces outils sont largement utilisés dans le e-commerce pour la surveillance des prix, le marketing pour la génération de leads, la finance pour la collecte de données alternatives, et l'immobilier pour l'analyse de marché. Par exemple, un analyste du commerce de détail peut utiliser un web scraper IA pour suivre quotidiennement les prix et les niveaux de stock de centaines de produits concurrents, alimentant directement ces données dans ses modèles de tarification.
Comment Choisir
Lors de la sélection d'un outil, considérez sa capacité à gérer des sites web dynamiques et riches en JavaScript, ainsi que sa résilience face aux technologies anti-scraping. Évaluez l'interface utilisateur — si vous avez besoin d'une solution sans code de type pointer-cliquer ou d'une API plus puissante axée sur les développeurs. Évaluez également son évolutivité pour l'extraction de grands volumes de données et l'adéquation du modèle de tarification à votre fréquence d'utilisation et à vos besoins en données.
Web scrapingCas d'utilisation
Surveillance des Prix et des Stocks en E-commerce
Un responsable e-commerce doit maintenir des prix compétitifs pour des milliers de produits. Il utilise un outil de web scraping IA pour scanner automatiquement les sites web des concurrents toutes les quelques heures. L'outil identifie les pages de produits, extrait les prix actuels, la disponibilité des stocks et les offres promotionnelles, puis structure ces données dans un tableau de bord. Ce processus automatisé remplace des heures de vérification manuelle, permettant au responsable d'ajuster sa propre stratégie de prix en temps quasi réel, de réagir aux ruptures de stock et de maximiser les opportunités de vente.
Génération de Leads Commerciaux à partir d'Annuaires en Ligne
Un représentant en développement commercial (SDR) est chargé de constituer une liste de clients potentiels dans un secteur spécifique. Au lieu de parcourir manuellement les annuaires d'entreprises en ligne ou les réseaux professionnels, le SDR configure un outil de web scraping pour cibler ces sites. L'outil extrait les noms d'entreprises, les e-mails de contact, les numéros de téléphone et les titres des postes des décideurs clés. La liste structurée qui en résulte peut être directement importée dans un CRM, ce qui permet au SDR d'économiser plus de 80% de son temps de prospection et de se concentrer sur la prise de contact et l'engagement.
Étude de Marché et Analyse des Sentiments
Un analyste de marché pour une marque d'électronique grand public souhaite comprendre le sentiment du public concernant le lancement d'un nouveau produit. Il utilise un outil de web scraping pour collecter des milliers d'avis de clients sur des sites de vente au détail, des blogs technologiques et des plateformes de médias sociaux. Les capacités d'IA de l'outil aident à analyser le texte non structuré pour identifier les sujets clés (par ex., « autonomie de la batterie », « qualité de l'écran ») et le sentiment associé (positif, négatif, neutre). Ces données agrégées fournissent un aperçu complet du marché, mettant en évidence les forces et les faiblesses du produit beaucoup plus rapidement que l'analyse manuelle ou les enquêtes.
Agrégation de Données du Marché Immobilier
Une société d'investissement immobilier a besoin d'informations à jour sur les annonces immobilières dans plusieurs villes. Elle déploie un agent de web scraping pour agréger les données de divers portails immobiliers comme Zillow, Redfin et les sites d'agences locales. Le scraper extrait des détails tels que l'adresse de la propriété, le prix, la superficie, le nombre de chambres et les jours sur le marché. Ces données sont compilées dans une base de données centrale, permettant aux analystes d'identifier les propriétés sous-évaluées, de suivre les tendances du marché et de prendre des décisions d'investissement basées sur les données sans vérifier manuellement des dizaines de sites web.
Collecte de Données Alternatives Financières
Un analyste quantitatif dans un fonds spéculatif recherche des sources de données alternatives pour obtenir un avantage commercial. Il utilise un outil de web scraping pour surveiller et extraire des informations de sites d'actualités financières, de dépôts réglementaires et de médias sociaux pour les mentions d'actions spécifiques. L'outil est programmé pour fonctionner en continu, capturant les dernières nouvelles et les changements de sentiment du public en temps réel. Ce flux de données est ensuite injecté dans des modèles de trading algorithmique pour identifier les corrélations et prédire les mouvements du marché, fournissant des informations qui ne sont pas disponibles via les flux de données financières traditionnels.
Agrégation de Données pour la Recherche Académique
Un chercheur universitaire mène une méta-analyse qui nécessite des données provenant de centaines d'études scientifiques publiées. Trouver et extraire manuellement les points de données du résumé ou des tableaux de chaque article serait extrêmement chronophage. Le chercheur utilise un outil de web scraping pour parcourir automatiquement les bases de données académiques (comme PubMed ou Google Scholar), identifier les articles pertinents en fonction de mots-clés et extraire des informations spécifiques telles que la taille des échantillons, les méthodologies et les principales conclusions. Cela automatise la création d'un ensemble de données complet, permettant une analyse à grande échelle qui serait autrement irréalisable.