Yamify
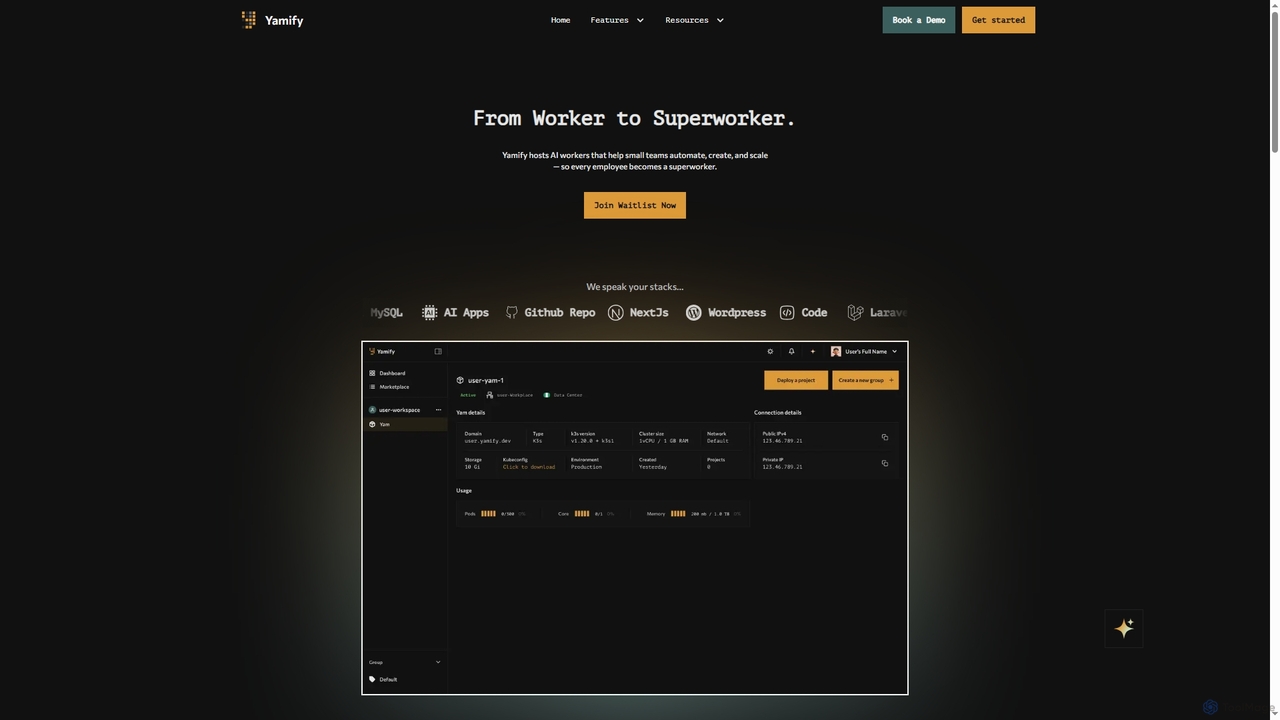
Yamify est une plateforme cloud qui héberge des travailleurs IA pour aider les petites équipes à automatiser, créer …
Yamify est une plateforme cloud qui héberge des travailleurs IA pour aider les petites équipes à automatiser, créer et faire évoluer des applications. Elle simplifie le déploiement et la gestion de Kubernetes, permettant aux utilisateurs de lancer et de gérer des applications dans un environnement cloud privé sans écrire de YAML.
Ploomber
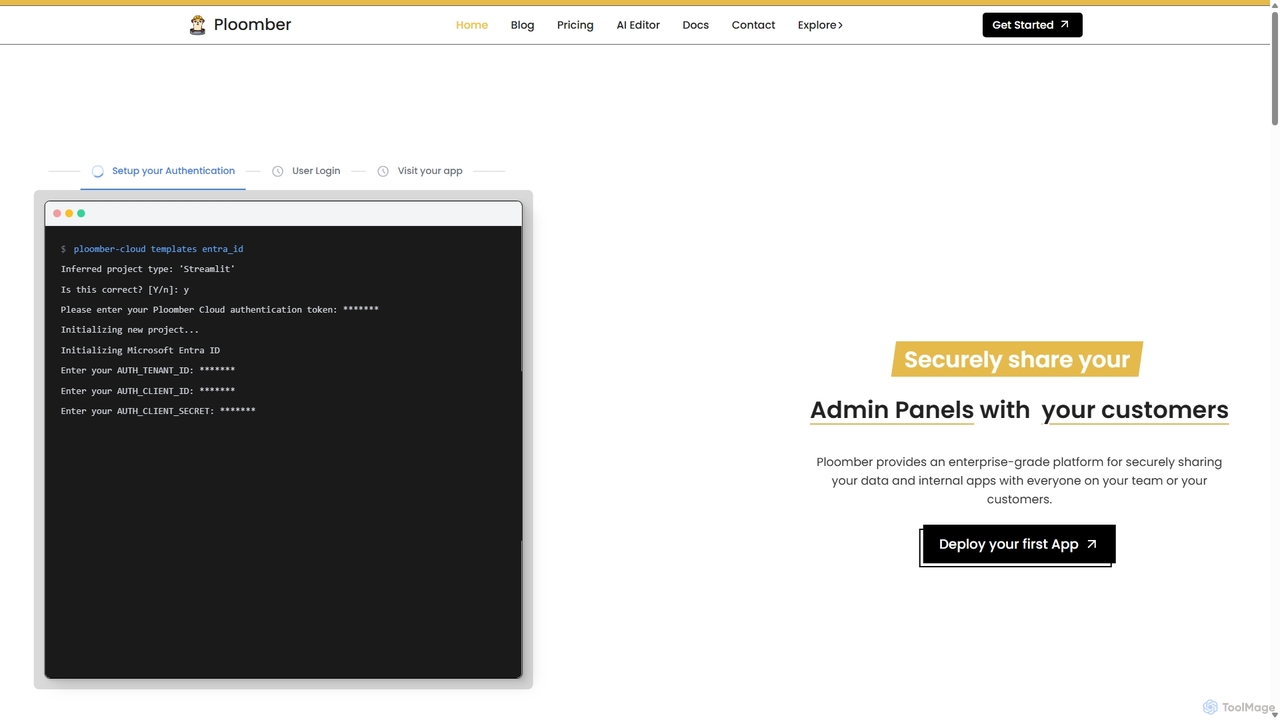
Ploomber est une plateforme de niveau entreprise pour le déploiement, la gestion et la mise à l'échelle d'applications …
Ploomber est une plateforme de niveau entreprise pour le déploiement, la gestion et la mise à l'échelle d'applications de données. Elle simplifie le déploiement de frameworks comme Streamlit, Dash et FastAPI, offrant des fonctionnalités robustes telles que le DevOps automatisé, une sécurité avancée, l'auto-scaling et des options de déploiement flexibles du cloud au sur site, conçues pour les équipes de science des données et d'IA.
Prodvana
Prodvana est une plateforme de déploiement intelligente basée sur l'intention, conçue pour la livraison de logiciels moderne. Elle …
Prodvana est une plateforme de déploiement intelligente basée sur l'intention, conçue pour la livraison de logiciels moderne. Elle aide les équipes d'ingénierie à accélérer la fréquence des déploiements, à améliorer la fiabilité et à réduire les frais généraux opérationnels en automatisant les chemins de publication, en fournissant des informations pré-déploiement et en s'intégrant de manière transparente avec l'infrastructure existante comme Kubernetes, Terraform et les fournisseurs sans serveur.
Shuttle
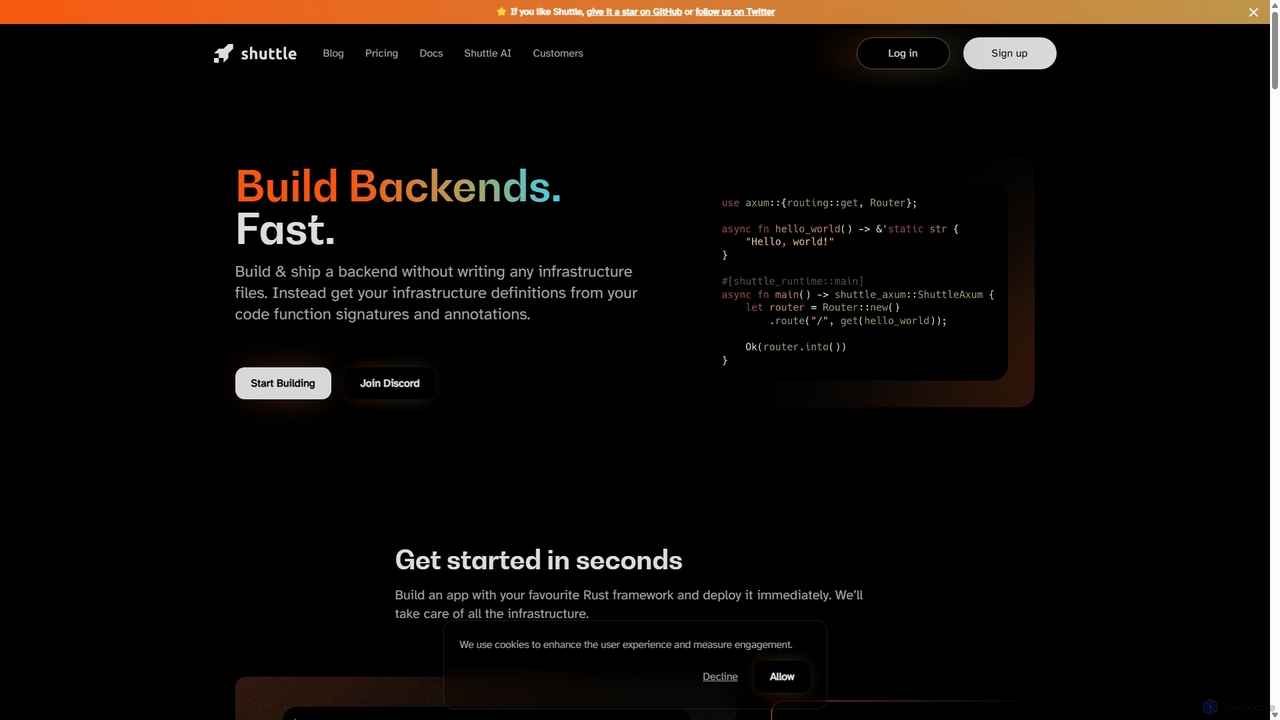
Shuttle est une plateforme cloud open-source conçue pour accélérer le développement backend en Rust. Elle élimine la gestion …
Shuttle est une plateforme cloud open-source conçue pour accélérer le développement backend en Rust. Elle élimine la gestion de l'infrastructure en permettant aux développeurs de provisionner des ressources comme des bases de données et des secrets directement dans leur code à l'aide de simples annotations. Concentrez-vous sur la création de votre application et laissez Shuttle s'occuper du déploiement et de la mise à l'échelle.
Convox
Convox est une Plateforme en tant que Service (PaaS) qui automatise la gestion de l'infrastructure cloud. Elle simplifie …
Convox est une Plateforme en tant que Service (PaaS) qui automatise la gestion de l'infrastructure cloud. Elle simplifie le déploiement d'applications, la mise à l'échelle, la surveillance et le CI/CD sur les principaux fournisseurs de cloud comme AWS et GCP, permettant aux équipes de développement de se concentrer sur l'écriture de code plutôt que sur la gestion d'opérations complexes.
Movestax
Movestax est une plateforme cloud serverless-first, alimentée par l'IA et conçue pour les développeurs modernes. Elle simplifie la …
Movestax est une plateforme cloud serverless-first, alimentée par l'IA et conçue pour les développeurs modernes. Elle simplifie la gestion de l'infrastructure en unifiant le déploiement d'applications, les bases de données serverless et les flux de travail automatisés. Avec son assistant IA intégré, CodeStax, vous pouvez générer et déployer des applications full-stack à partir de prompts en langage naturel, accélérant considérablement le cycle de vie du développement, de l'idée à la production.
Zeabur
Zeabur est une plateforme de déploiement (PaaS) alimentée par l'IA, conçue pour les développeurs. Elle permet le déploiement …
Zeabur est une plateforme de déploiement (PaaS) alimentée par l'IA, conçue pour les développeurs. Elle permet le déploiement en un clic de n'importe quel projet, y compris le front-end, le back-end, les bases de données et les agents IA, directement depuis le code ou via une IA conversationnelle. Dotée d'un modèle de paiement à l'utilisation, d'une configuration automatique et d'une mise à l'échelle automatique, Zeabur simplifie l'infrastructure cloud, permettant aux développeurs de se concentrer uniquement sur le codage.
Zeet
Zeet est une plateforme complète de DevOps et d'opérations cloud conçue pour simplifier le déploiement et la gestion …
Zeet est une plateforme complète de DevOps et d'opérations cloud conçue pour simplifier le déploiement et la gestion des services et de l'infrastructure cloud. Elle donne aux développeurs, SRE et équipes DevOps les moyens d'automatiser le CI/CD, la gestion de Kubernetes et les opérations multi-cloud, leur permettant de se concentrer sur la création d'applications plutôt que sur la gestion d'infrastructures complexes.
Spaceship
Spaceship est une plateforme alimentée par l'IA pour les développeurs afin de construire, déployer et mettre à l'échelle …
Spaceship est une plateforme alimentée par l'IA pour les développeurs afin de construire, déployer et mettre à l'échelle des applications web. Elle automatise les flux de travail, optimise le code et fournit des informations intelligentes pour accélérer le cycle de vie du développement, du code au déploiement mondial.

Wasmer
Wasmer est un runtime universel WebAssembly qui vous permet d'exécuter n'importe quel code, n'importe où. Il fonctionne comme …
Wasmer est un runtime universel WebAssembly qui vous permet d'exécuter n'importe quel code, n'importe où. Il fonctionne comme une technologie de conteneur de nouvelle génération, offrant un déploiement ultra-rapide, sécurisé et évolutif pour les applications, des sites web et agents IA aux fonctions serverless, sans la surcharge des conteneurs traditionnels.
À propos de Déploiement
Les outils de Déploiement IA sont des plateformes spécialisées conçues pour rendre opérationnels les modèles d'apprentissage automatique entraînés dans des environnements de production. En tant que composant essentiel des Outils pour Développeurs, ils comblent le fossé entre le développement de modèles et l'application réelle en gérant les complexités du service, de la mise à l'échelle et de la gestion des modèles. Ces outils empaquettent généralement les modèles dans des formats conteneurisés et optimisés et les exposent via des points de terminaison API sécurisés. Cela garantit une haute disponibilité, une faible latence et des performances fiables, permettant aux développeurs d'intégrer de manière transparente les capacités de l'IA dans leurs applications.
Fonctionnalités Clés
- Infrastructure de Service de Modèles : Fournit des environnements optimisés, y compris le support GPU et CPU, pour exécuter efficacement l'inférence des modèles.
- Mise à l'Échelle Automatique et Équilibrage de Charge : Ajuste automatiquement les ressources de calcul en fonction du trafic en temps réel pour gérer les pics de demande et contrôler les coûts.
- Génération de Points de Terminaison API : Simplifie la création d'API REST sécurisées, évolutives et documentées pour tout modèle entraîné.
- Conteneurisation et Gestion des Dépendances : Utilise des technologies comme Docker pour empaqueter les modèles et leurs dépendances, assurant une exécution cohérente dans différents environnements.
- Surveillance des Performances et Journalisation : Offre des tableaux de bord et des alertes pour suivre les métriques clés telles que la latence, le débit, les taux d'erreur et l'utilisation des ressources.
Cas d'Utilisation
Ces outils sont essentiels pour les ingénieurs MLOps, les scientifiques des données et les développeurs chargés de mettre l'IA en production. Ils sont largement utilisés dans des secteurs comme la technologie, le commerce électronique, la finance et la santé pour déployer des applications telles que des moteurs de recommandation en temps réel, des systèmes de détection de fraude et des outils d'analyse d'imagerie diagnostique.
Comment Choisir
Lors de la sélection d'un outil de Déploiement IA, tenez compte de sa prise en charge de vos frameworks de ML spécifiques (par ex., TensorFlow, PyTorch), de vos exigences en matière d'évolutivité et de vos besoins en latence. Évaluez l'équilibre entre la facilité d'utilisation (plateformes gérées) et le contrôle (infrastructure configurable). Évaluez également le modèle de tarification (paiement à l'usage ou fixe) et ses capacités d'intégration avec vos pipelines CI/CD et MLOps existants.
DéploiementCas d'utilisation
Déploiement d'un moteur de recommandation en temps réel
Un ingénieur ML d'une plateforme de commerce électronique doit lancer un nouveau modèle de recommandation de produits. Le modèle doit répondre aux requêtes des utilisateurs en quelques millisecondes pour améliorer l'expérience d'achat. À l'aide d'un outil de Déploiement IA, l'ingénieur empaquette le modèle, définit le matériel requis (comme un GPU) et l'expose en tant qu'API REST. La fonction de mise à l'échelle automatique de la plateforme provisionne automatiquement plus de ressources pendant les saisons de pointe comme le Black Friday et les réduit pendant les périodes creuses, garantissant une expérience utilisateur réactive tout en optimisant les coûts d'infrastructure.
Service d'un modèle de vision par ordinateur pour le contrôle qualité
Une entreprise manufacturière souhaite automatiser la détection des défauts sur sa chaîne de production. Un ingénieur DevOps utilise une plateforme de déploiement pour conteneuriser un modèle de vision par ordinateur et le déployer sur des appareils en périphérie (edge devices) situés à côté des tapis roulants. L'outil gère le cycle de vie du déploiement, permettant des mises à jour à distance et la surveillance des modèles sur des centaines d'appareils à partir d'un tableau de bord central. Cela garantit des performances constantes et permet un déploiement rapide des versions améliorées du modèle sans interrompre la production.
Lancement d'un SaaS avec une fonctionnalité d'IA générative
Une startup développe une application d'assistant d'écriture alimentée par un grand modèle de langage (LLM). Un développeur full-stack utilise un service de déploiement géré pour héberger le modèle. Le service fournit une passerelle API sécurisée avec une authentification et une limitation de débit intégrées. Cela permet à la startup d'intégrer facilement la fonctionnalité d'IA dans son application web et de créer des plans d'abonnement à plusieurs niveaux basés sur l'utilisation de l'API, sans avoir à construire et à maintenir une infrastructure de service complexe à partir de zéro.
Test A/B de modèles de détection de fraude
L'équipe de science des données d'une entreprise de technologie financière a développé un nouveau modèle de détection de fraude plus précis. Pour valider ses performances en conditions réelles sans risque, ils utilisent un outil de déploiement pour effectuer un test A/B. La plateforme leur permet de déployer le nouveau modèle aux côtés de l'existant et d'y acheminer 10 % des données de transaction en direct. En comparant les métriques de performance comme la latence et la précision des prédictions dans le tableau de bord de l'outil, l'équipe peut prendre une décision basée sur les données pour remplacer complètement l'ancien modèle.
Automatisation du réentraînement et du déploiement des modèles
Une équipe MLOps vise à créer un pipeline entièrement automatisé où leur modèle de prédiction de l'attrition client est réentraîné chaque semaine sur de nouvelles données. Ils intègrent leur outil de déploiement IA à leur système CI/CD (par ex., Jenkins). Une fois qu'un nouveau modèle est entraîné et passe les tests automatisés, le pipeline CI/CD déclenche un appel API vers l'outil de déploiement. L'outil effectue alors un déploiement "bleu-vert", basculant de manière transparente le trafic vers la nouvelle version du modèle sans aucune interruption de service pour les utilisateurs finaux.
Exécution d'inférence par lots pour les rapports financiers
Une équipe d'analyse d'une société financière doit exécuter un modèle de prévision complexe sur des téraoctets de données de marché à la fin de chaque trimestre. Il s'agit d'une tâche de courte durée mais très intensive en calcul. Ils utilisent une plateforme de déploiement pour planifier une tâche d'inférence par lots. La plateforme provisionne automatiquement un grand cluster de machines pour traiter les données en parallèle, termine la tâche en quelques heures au lieu de jours, puis met fin à toutes les ressources. Cette approche fournit une puissance de calcul massive à la demande tout en minimisant les coûts.