Latta
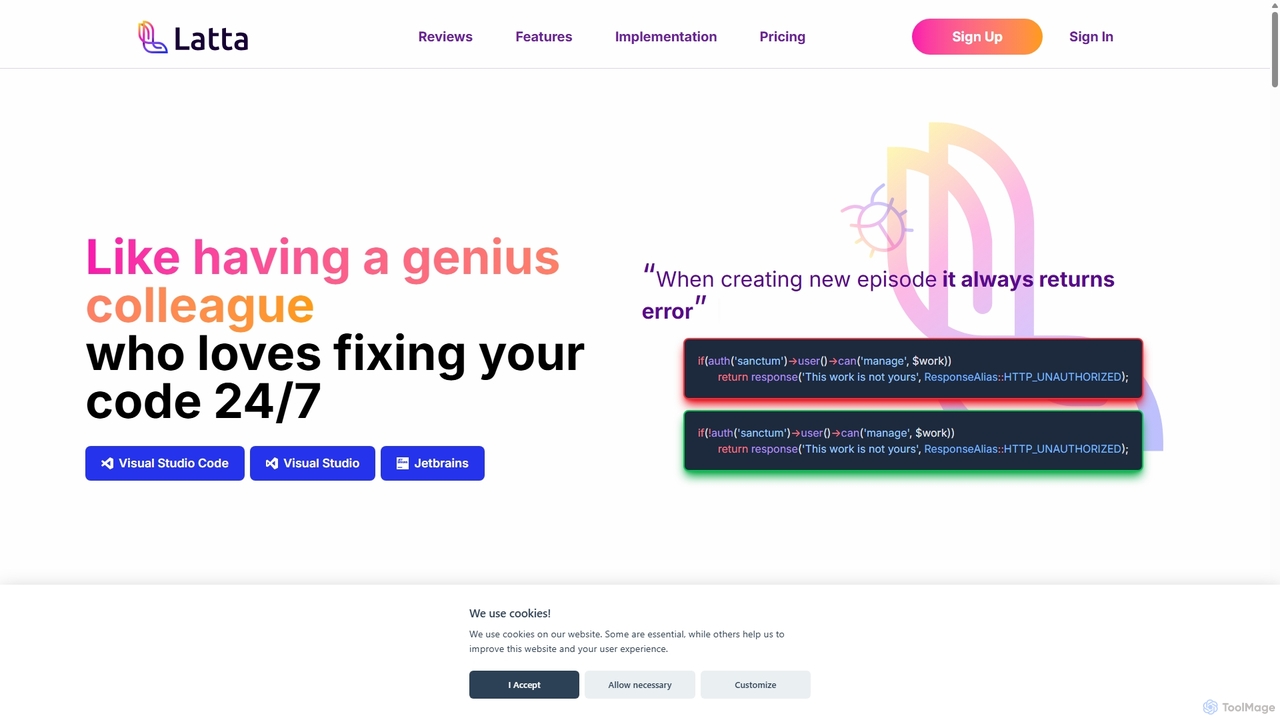
Latta est un assistant de codage alimenté par l'IA, conçu pour être votre collègue de génie pour le …
Latta est un assistant de codage alimenté par l'IA, conçu pour être votre collègue de génie pour le débogage 24/7. Il s'intègre aux IDE populaires comme VS Code et JetBrains pour trouver et corriger les bogues dans des projets complexes. Avec des fonctionnalités telles que la relecture de session utilisateur et l'intégration Git, Latta simplifie le signalement et la résolution des bogues, faisant gagner un temps et des efforts considérables aux développeurs.
À propos de Surveillance des erreurs
Les outils de Surveillance des erreurs constituent une catégorie spécialisée de logiciels pour développeurs conçus pour détecter, diagnostiquer et signaler automatiquement les erreurs d'application en temps réel. Ces plateformes capturent les exceptions non gérées et les plantages, fournissant aux développeurs des traces de pile détaillées et des données contextuelles. En regroupant intelligemment les erreurs similaires et en fournissant des alertes instantanées, elles permettent aux équipes d'identifier, de prioriser et de résoudre les bogues de manière proactive avant qu'ils n'affectent de manière significative les utilisateurs. Cette focalisation sur la stabilité post-déploiement en fait un composant essentiel du développement et des opérations logicielles modernes (DevOps).
Fonctionnalités Clés
- Capture d'erreurs en temps réel : Intercepte et enregistre automatiquement les exceptions, les plantages et autres erreurs au niveau du code dès qu'ils se produisent en production ou en pré-production.
- Traces de pile détaillées : Fournit le fichier exact, le numéro de ligne et la séquence d'appels de fonction menant à une erreur, localisant la cause racine.
- Regroupement et agrégation d'erreurs : Regroupe intelligemment les erreurs identiques ou similaires en un seul problème exploitable pour réduire le bruit et simplifier la priorisation.
- Collecte de données contextuelles : Rassemble des informations de session précieuses comme les actions de l'utilisateur (fil d'Ariane), la version du navigateur, le système d'exploitation et les requêtes réseau pour aider à reproduire les bogues.
- Alertes et intégrations : Envoie des notifications instantanées par e-mail, Slack ou PagerDuty et s'intègre avec des outils de suivi de problèmes comme Jira ou GitHub pour rationaliser les flux de travail.
Cas d'utilisation
Les outils de Surveillance des erreurs sont essentiels pour toute organisation développant des logiciels. Ils sont largement utilisés par les développeurs de logiciels, les ingénieurs DevOps et les ingénieurs en fiabilité de site (SRE) pour maintenir la santé des applications. Les scénarios courants incluent la surveillance des applications web en direct pour les erreurs JavaScript, le suivi des plantages dans les applications mobiles (iOS/Android) et la garantie de la stabilité des microservices et des API backend.
Comment choisir
Lors de la sélection d'un outil de Surveillance des erreurs, tenez compte de sa prise en charge de vos langages de programmation et frameworks spécifiques. Évaluez la profondeur des données contextuelles qu'il fournit, telles que le fil d'Ariane de l'utilisateur et les métriques de performance. Évaluez ses capacités d'intégration avec votre chaîne d'outils existante (par exemple, Jira, Slack, GitHub). Enfin, examinez le modèle de tarification — qu'il soit basé sur le volume d'erreurs, les utilisateurs ou les fonctionnalités — pour vous assurer qu'il correspond à l'échelle et au budget de votre projet.
Surveillance des erreursCas d'utilisation
Correction proactive des bogues dans une application SaaS en direct
Un ingénieur DevOps dans une entreprise SaaS est responsable du maintien de la stabilité de leur application web en production. Ils intègrent un outil de Surveillance des erreurs à leur frontend JavaScript et à leur backend Python. Lorsqu'un utilisateur rencontre un bogue inédit lors du paiement, l'outil capture instantanément l'exception, ainsi que les détails du navigateur de l'utilisateur et la séquence d'actions (fil d'Ariane) menant à l'erreur. L'ingénieur reçoit une alerte Slack avec un lien vers le rapport d'erreur complet, y compris la trace de la pile. Cela leur permet de diagnostiquer et de déployer un correctif en quelques minutes, évitant ainsi de nouvelles pertes de revenus et améliorant la confiance des utilisateurs sans attendre les rapports de bogues manuels.
Diagnostic des plantages d'applications mobiles
Un développeur de jeux mobiles lance une nouvelle mise à jour pour son application iOS et Android. Peu de temps après, il remarque une augmentation des plantages signalés par un outil de Surveillance des erreurs. L'outil regroupe automatiquement les plantages par cause racine, révélant qu'une animation spécifique provoque une fuite de mémoire sur les anciens appareils Android. Le rapport inclut le modèle de l'appareil, la version du système d'exploitation et l'utilisation de la mémoire au moment du plantage. Armée de ces données précises, l'équipe de développement peut reproduire le problème, corriger la fuite de mémoire et publier une mise à jour corrective sur les magasins d'applications, réduisant ainsi considérablement les avis négatifs et le départ des utilisateurs.
Amélioration de la qualité du code dans les environnements de pré-production
Une équipe d'assurance qualité (QA) utilise un outil de Surveillance des erreurs dans son environnement de pré-production pour attraper les bogues avant qu'ils n'atteignent la production. Pendant les cycles de tests automatisés et manuels, toute erreur JavaScript ou exception backend est immédiatement enregistrée et assignée au développeur responsable via une intégration Jira. Ce processus crée une boucle de rétroaction serrée, permettant aux développeurs de corriger les problèmes pendant que le contexte du code est encore frais dans leur esprit. En conséquence, le nombre de bogues critiques déployés en production diminue de plus de 60 %, ce qui se traduit par des lancements plus fluides et moins d'interventions d'urgence pour l'équipe des opérations.
Surveillance de la santé des API backend et des microservices
Un ingénieur en fiabilité de site (SRE) est chargé d'assurer la disponibilité et la fiabilité d'une architecture de microservices complexe. Il configure un outil de Surveillance des erreurs pour surveiller des dizaines de services écrits en Go et Java. Lorsqu'un service en aval échoue, provoquant une cascade d'erreurs 5xx dans une passerelle API en amont, l'outil regroupe toutes les erreurs associées en un seul incident. Le SRE est immédiatement alerté et peut voir le service exact qui a échoué en premier, ainsi que la charge utile de la requête qui a déclenché le problème. Cette visibilité permet une réponse rapide aux incidents, empêchant une défaillance mineure de service de dégénérer en une panne complète du site.
Suivi des problèmes de performance JavaScript côté client
Un développeur frontend d'un site de commerce électronique remarque que certains utilisateurs signalent des chargements de page lents, mais les analyses traditionnelles n'en montrent pas la cause. En utilisant un outil de Surveillance des erreurs qui suit également les performances, il découvre qu'un script marketing tiers lève occasionnellement des exceptions silencieuses et bloque le thread principal. L'outil corrèle ces erreurs avec des métriques élevées de 'Largest Contentful Paint' (LCP) pour les utilisateurs concernés. Le développeur peut alors utiliser cette preuve pour travailler avec l'équipe marketing afin de différer le chargement du script ou de le remplacer, améliorant ainsi directement l'expérience utilisateur et augmentant potentiellement les taux de conversion.
Validation de l'impact d'une nouvelle version de fonctionnalité
Une équipe produit lance une nouvelle fonctionnalité majeure et souhaite surveiller sa stabilité de près. Elle utilise un outil de Surveillance des erreurs pour créer un tableau de bord et une alerte spécifiques pour les erreurs étiquetées avec le numéro de version de la nouvelle fonctionnalité. Cela leur permet d'isoler les problèmes liés au nouveau code du reste du bruit de l'application. Dans la première heure suivant la sortie, ils constatent un petit nombre d'erreurs non critiques liées à un cas limite qu'ils n'avaient pas anticipé. Parce que les erreurs sont détectées et analysées immédiatement, l'équipe peut rapidement déployer un correctif, garantissant le succès du lancement de la fonctionnalité et renforçant la confiance dans le processus de publication.