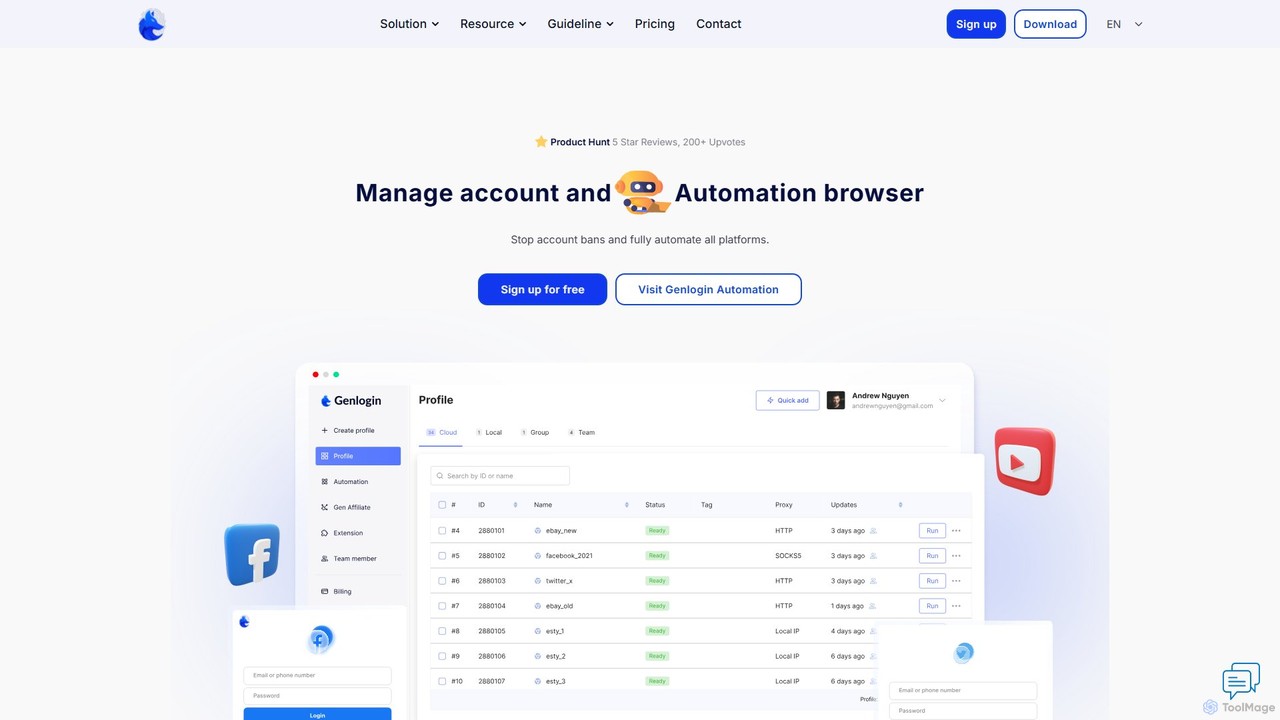
Genlogin
Genlogin est un navigateur anti-détection avancé conçu pour gérer plusieurs comptes en ligne de manière sécurisée et efficace. …
Genlogin est un navigateur anti-détection avancé conçu pour gérer plusieurs comptes en ligne de manière sécurisée et efficace. Il prévient les bannissements de comptes en créant des empreintes de navigateur uniques basées sur des données réelles pour chaque profil. Avec des fonctionnalités telles que l'automatisation sans code, la synchronisation des actions en temps réel et un service proxy intégré, Genlogin est idéal pour le e-commerce, le marketing sur les réseaux sociaux, le web scraping et le marketing d'affiliation, permettant aux utilisateurs de développer leurs opérations en ligne.
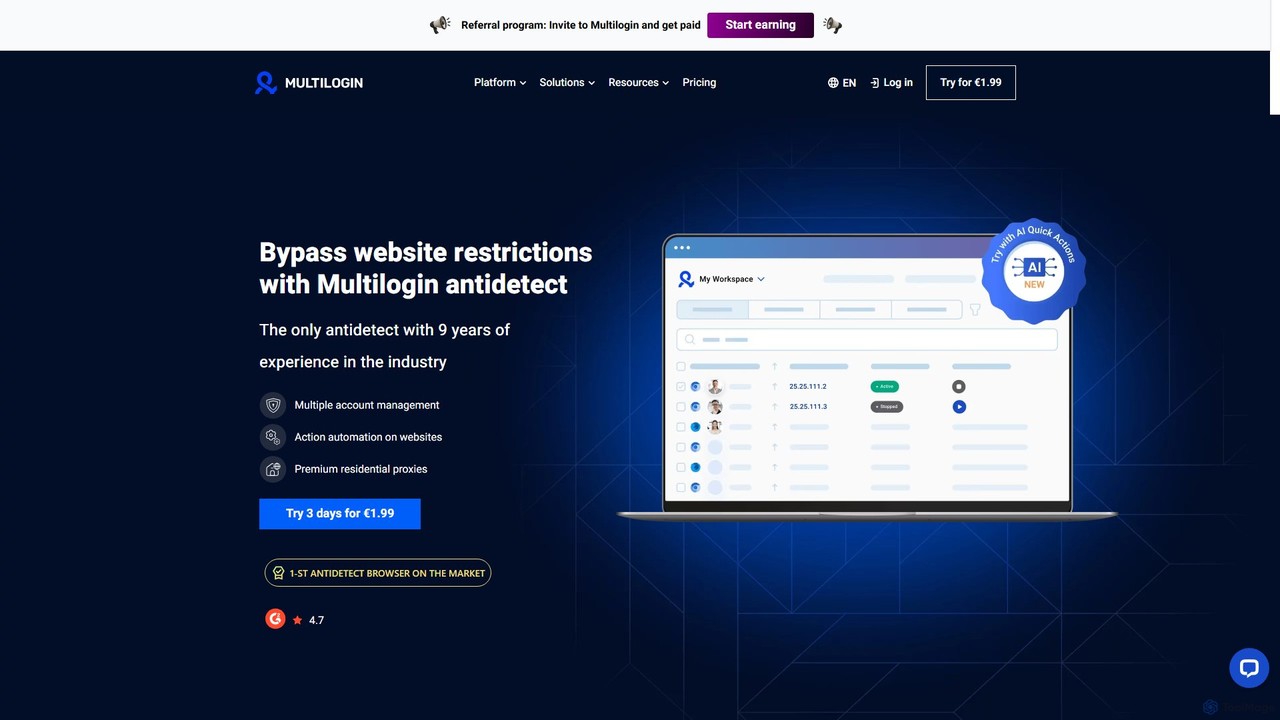
Multilogin
Multilogin est un navigateur anti-détection de premier plan qui permet aux utilisateurs de créer et de gérer plusieurs …
Multilogin est un navigateur anti-détection de premier plan qui permet aux utilisateurs de créer et de gérer plusieurs profils de navigateur uniques. Il est conçu pour contourner les restrictions des sites web et les interdictions de comptes en masquant les empreintes digitales, ce qui le rend idéal pour le marketing sur les réseaux sociaux, le e-commerce, le web scraping et d'autres opérations multi-comptes. Il inclut des fonctionnalités telles que la collaboration en équipe, le support de l'automatisation et des proxys résidentiels intégrés.
Horseman
Horseman est un robot d'exploration web de bureau infiniment configurable pour les développeurs, les référenceurs et les analystes …
Horseman est un robot d'exploration web de bureau infiniment configurable pour les développeurs, les référenceurs et les analystes de performance. Il exploite des extraits de code JavaScript personnalisés et l'intégration de GPT-3.5 pour extraire, analyser et manipuler les données de sites web, offrant des informations approfondies sur des sites entiers sans nécessiter de connaissances avancées en codage.
À propos de Web scraping
Les outils de Web Scraping sont des solutions basées sur l'IA conçues pour extraire automatiquement des données des sites web. Ces outils exploitent des algorithmes avancés, intégrant souvent le traitement du langage naturel et l'apprentissage automatique, pour naviguer sur les pages web, identifier et collecter des informations structurées ou non structurées. Ils sont essentiels pour automatiser la collecte manuelle fastidieuse de données, offrant une acquisition de données évolutive et efficace pour divers besoins analytiques. Cette capacité les rend inestimables pour les entreprises et les chercheurs cherchant à obtenir des informations à partir de la vaste quantité de données web publiques.
Fonctionnalités Clés
- Extraction Automatisée de Données: Collecte systématiquement des points de données spécifiques comme le texte, les images et les liens à partir des pages web.
- Gestion du Contenu Dynamique: Interagit avec le contenu rendu en JavaScript, les formulaires et la pagination pour accéder à toutes les données pertinentes.
- Contournement Anti-Scraping: Emploie des techniques pour contourner les mesures anti-bot courantes telles que les CAPTCHA et le blocage d'IP.
- Structuration et Exportation des Données: Organise les données extraites dans des formats utilisables comme CSV, JSON ou XML pour une analyse et une intégration faciles.
- Planification et Surveillance: Permet aux utilisateurs de planifier des tâches de scraping et de surveiller les sites web pour des informations nouvelles ou mises à jour.
Scénarios d'Application
Les outils de web scraping sont largement utilisés dans la collecte d'intelligence de marché pour les entreprises, leur permettant de surveiller les prix et les informations sur les produits des concurrents en temps réel. Ils sont également cruciaux pour les chercheurs universitaires qui collectent de grands ensembles de données à partir de sources publiques pour l'analyse statistique. Les plateformes de commerce électronique utilisent ces outils pour la surveillance des prix en temps réel et le suivi des stocks chez divers détaillants en ligne.
Comment Choisir
Lors de la sélection d'un outil de web scraping, tenez compte de sa capacité à gérer la complexité des sites web cibles, y compris le contenu dynamique et les mesures anti-scraping. Évaluez son évolutivité et ses capacités de planification en fonction du volume et de la fréquence des données requises. Évaluez la facilité d'utilisation, que ce soit via une interface sans code ou une API robuste pour les développeurs. Enfin, assurez-vous que l'outil prend en charge les pratiques de scraping éthiques et la conformité aux réglementations en matière de confidentialité des données.
Web scrapingCas d'utilisation
Surveillance des Prix Concurrentiels pour l'E-commerce
Les entreprises de commerce électronique utilisent des outils de web scraping pour surveiller en permanence les prix des concurrents sur diverses plateformes en ligne. Cela leur permet de suivre les changements de prix, d'identifier les offres promotionnelles et d'ajuster leurs propres stratégies de prix en temps réel pour rester compétitives. En automatisant ce processus, les entreprises peuvent économiser un effort manuel considérable et s'assurer que leurs offres de produits sont toujours au prix optimal, ce qui entraîne une augmentation des ventes et de la part de marché.
Génération de Leads et Intelligence Commerciale
Les équipes de vente et de marketing exploitent le web scraping pour extraire des informations précieuses sur les leads à partir de répertoires publics, de sites de réseaux professionnels ou de portails spécifiques à l'industrie. Cela inclut les coordonnées, les profils d'entreprise et les titres de poste, qui sont ensuite utilisés pour créer des listes de prospects ciblées. L'automatisation de la génération de leads réduit considérablement le temps passé à la saisie manuelle des données, permettant aux professionnels de la vente de se concentrer sur l'engagement et la conversion, améliorant ainsi l'efficacité du pipeline de ventes.
Étude de Marché et Analyse des Tendances
Les chercheurs et les analystes utilisent le web scraping pour collecter de grandes quantités de données publiques provenant d'articles de presse, de forums, de médias sociaux et de sites d'avis. Ces données sont ensuite traitées pour l'analyse des sentiments, l'identification des tendances et l'intelligence concurrentielle. En automatisant la collecte de données, ils peuvent acquérir rapidement des informations à jour sur les opinions des consommateurs, les tendances émergentes du marché et la perception publique des marques ou des produits, permettant des décisions stratégiques plus éclairées.
Agrégation de Contenu pour les Portails d'Actualités
Les entreprises de médias et les agrégateurs de nouvelles utilisent des outils de web scraping pour collecter automatiquement des articles, des titres, des images et des vidéos provenant de diverses sources d'information et de blogs. Cela leur permet de remplir leurs propres fils d'actualité ou plateformes de contenu avec du contenu frais et diversifié sans curation manuelle. L'automatisation assure un flux constant d'informations, maintenant leur public engagé et informé, tout en réduisant considérablement la charge de travail éditoriale.
Analyse des Annonces Immobilières
Les professionnels de l'immobilier et les investisseurs utilisent le web scraping pour collecter les annonces immobilières de plusieurs plateformes en ligne, y compris les portails immobiliers et les petites annonces. Ces données agrégées permettent une analyse complète du marché, identifiant les tendances des valeurs immobilières, des taux de location et de la disponibilité dans différentes régions. En automatisant cette collecte de données, ils peuvent prendre des décisions plus rapides et plus éclairées sur les acquisitions de propriétés, les ventes et les stratégies d'investissement, obtenant un avantage concurrentiel.
Collecte de Données pour la Recherche Académique
Les universitaires et les chercheurs utilisent fréquemment le web scraping pour construire de grands ensembles de données pour leurs études. Cela implique d'extraire des informations de publications scientifiques, de bases de données gouvernementales, d'archives publiques et de forums spécialisés. La capacité de collecter et de structurer rapidement de grandes quantités de données provenant de diverses sources en ligne est cruciale pour la recherche empirique, l'analyse statistique et la validation d'hypothèses, accélérant considérablement le processus de recherche et permettant des informations plus approfondies.