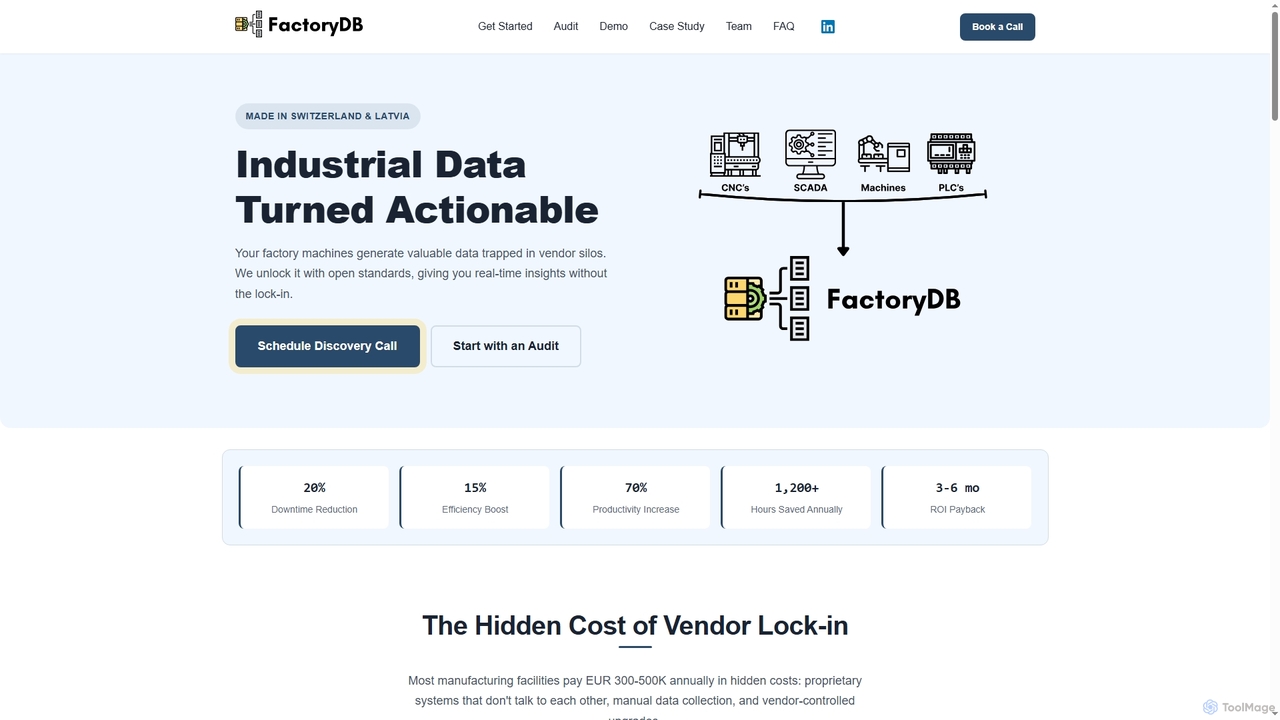
FactoryDB
FactoryDB est une plateforme d'infrastructure de données industrielles conçue pour éliminer la dépendance vis-à-vis des fournisseurs (vendor lock-in) …
FactoryDB est une plateforme d'infrastructure de données industrielles conçue pour éliminer la dépendance vis-à-vis des fournisseurs (vendor lock-in) pour les fabricants. En utilisant des standards ouverts comme MQTT, elle unifie les données des systèmes PLC, SCADA et MES en une seule couche de données neutre. Cela permet des analyses en temps réel, une maintenance prédictive et des gains d'efficacité significatifs, en particulier pour les industries réglementées telles que la pharmacie, l'agroalimentaire et l'énergie.
À propos de Infrastructure de données
Les outils d'Infrastructure de Données sont des solutions spécialisées basées sur l'IA qui fournissent les systèmes fondamentaux pour la collecte, le stockage, le traitement et la gestion des vastes ensembles de données essentiels aux opérations d'intelligence artificielle et d'apprentissage automatique. Ces outils garantissent la disponibilité, l'intégrité et la performance des données, permettant une formation, un déploiement et une mise à l'échelle efficaces des modèles d'IA au sein du paysage informatique plus large. Ils sont essentiels pour gérer les exigences uniques des charges de travail d'IA, de l'ingestion de données en temps réel au traitement analytique complexe.
Fonctionnalités Clés
- Stockage de Données Évolutif : Fournit des solutions de stockage distribué haute performance optimisées pour les ensembles de données d'IA à grande échelle, prenant en charge divers types de données et modèles d'accès.
- Pipelines de Données Automatisés : Facilite la création et la gestion de pipelines automatisés d'ingestion, de transformation et de chargement (ETL) de données pour préparer les données à l'entraînement des modèles d'IA.
- Traitement de Données en Temps Réel : Permet le traitement et l'analyse à faible latence des données en streaming, cruciaux pour les applications d'IA en temps réel comme la détection de fraude ou les systèmes de recommandation.
- Gouvernance et Sécurité des Données : Met en œuvre des mesures de sécurité robustes, des contrôles d'accès et des cadres de conformité pour protéger les données sensibles d'entraînement d'IA et les sorties des modèles.
- Orchestration des Ressources : Gère et optimise les ressources de calcul (GPU, CPU) et le stockage dans des environnements distribués pour une exécution efficace des charges de travail d'IA.
Scénarios d'Application
L'Infrastructure de Données est indispensable pour les organisations qui construisent et déploient l'IA. Par exemple, une grande entreprise technologique développant un nouveau modèle linguistique nécessite une infrastructure robuste pour stocker des pétaoctets de données textuelles et gérer des tâches d'entraînement distribuées sur des milliers de GPU. De même, les institutions financières l'utilisent pour le traitement en temps réel des données de transaction afin d'alimenter les systèmes de détection de fraude basés sur l'IA, garantissant une analyse et une réponse immédiates. Les plateformes de commerce électronique l'exploitent pour collecter et traiter les données d'interaction client, alimentant les moteurs de recommandation qui personnalisent les expériences utilisateur.
Comment Choisir
La sélection des bons outils d'Infrastructure de Données implique l'évaluation de plusieurs facteurs clés. Considérez l'évolutivité requise pour gérer la croissance future des données et la complexité croissante des modèles d'IA. Évaluez les besoins de performance, y compris les taux d'ingestion de données, la vitesse de traitement et la latence des requêtes, en particulier pour les applications en temps réel. Évaluez les capacités d'intégration avec les plateformes AI/ML existantes, les sources de données et les environnements cloud. Enfin, examinez attentivement les fonctionnalités de sécurité, les certifications de conformité et le coût total de possession, y compris les frais d'exploitation et la maintenance.
Infrastructure de donnéesCas d'utilisation
Construction de Pipelines Scalables pour l'Entraînement de Modèles d'IA
Les ingénieurs en apprentissage automatique et les scientifiques des données utilisent une infrastructure de données robuste pour construire des pipelines efficaces et évolutifs pour l'entraînement de modèles d'IA. Cela implique l'automatisation de l'ingestion de vastes ensembles de données provenant de diverses sources, la réalisation du nettoyage et de la transformation des données nécessaires, et la livraison des données préparées aux plateformes ML. Une infrastructure bien conçue garantit une qualité et une disponibilité des données constantes, réduisant considérablement le temps et les efforts requis pour le développement et le déploiement itératifs de modèles, conduisant à une innovation plus rapide et à une amélioration des performances des modèles.
Construction de Pipelines d'Entraînement AI/ML Évolutifs
Les scientifiques des données et les ingénieurs en apprentissage automatique exploitent l'infrastructure de données pour établir des pipelines robustes et évolutifs pour l'entraînement des modèles d'IA. Cela implique l'ingestion efficace de vastes ensembles de données provenant de diverses sources, la réalisation de transformations de données complexes (ETL) et le stockage des données préparées dans des lacs ou entrepôts de données optimisés. L'infrastructure garantit la qualité, le lignage et l'accessibilité des données, permettant une itération rapide de l'entraînement des modèles, le contrôle de version et une intégration transparente avec les plateformes d'IA, accélérant finalement le développement et le déploiement de solutions d'IA performantes.
Construction de Pipelines de Données Évolutifs pour l'Entraînement d'IA
Les scientifiques des données et les ingénieurs ML utilisent des outils d'infrastructure de données pour construire des pipelines automatisés qui ingèrent des données brutes de diverses sources, les nettoient, les transforment et les stockent dans des formats optimisés. Cela garantit un approvisionnement continu en données de haute qualité et prétraitées, essentielles pour l'entraînement et le réglage fin de modèles d'IA complexes, réduisant considérablement le temps de préparation manuelle des données et améliorant la précision du modèle.
Construire des Pipelines de Données Évolutifs pour l'Entraînement d'IA
Les scientifiques de données et les ingénieurs ML ont besoin de pipelines de données robustes pour alimenter les modèles d'IA avec des données propres et prétraitées. Les outils d'infrastructure de données permettent l'ingestion, la transformation et le chargement (ETL) automatisés de vastes ensembles de données provenant de diverses sources dans des lacs de données ou des entrepôts de données. Cela garantit un approvisionnement continu en données de haute qualité, réduisant considérablement le temps de préparation manuelle des données et accélérant le processus itératif d'entraînement et de raffinement des modèles, conduisant à des systèmes d'IA plus précis et efficaces.
Construction de Lacs de Données Évolutifs pour l'Entraînement d'IA
Les scientifiques des données et les ingénieurs en apprentissage automatique ont besoin d'un lac de données robuste pour stocker des ensembles de données brutes et diverses (images, texte, audio, données de capteurs) à grande échelle pour l'entraînement de modèles d'IA complexes. Les outils d'infrastructure de données facilitent la création de tels lacs, offrant un stockage flexible, une gestion des métadonnées et des mécanismes de récupération de données efficaces. Cela permet un développement et une expérimentation itératifs des modèles sans goulots d'étranglement de données, garantissant une entrée de haute qualité pour les algorithmes d'apprentissage profond et réduisant les temps d'entraînement.
Analyse en Temps Réel pour la Business Intelligence
Les analystes commerciaux et les ingénieurs de données exploitent l'infrastructure de données en temps réel pour obtenir des informations immédiates sur les performances opérationnelles et le comportement des clients. En traitant les données en streaming provenant d'applications, d'appareils IoT ou de systèmes transactionnels, les organisations peuvent surveiller les métriques clés au fur et à mesure qu'elles se produisent. Cette capacité permet une prise de décision proactive, telle que l'identification des tendances émergentes du marché, la détection d'anomalies dans les transactions financières ou la personnalisation instantanée des expériences client, offrant un avantage concurrentiel grâce à une intelligence opportune.
Alimentation des Tableaux de Bord de Business Intelligence en Temps Réel
Les analystes commerciaux et les responsables des opérations s'appuient sur l'infrastructure de données pour alimenter les tableaux de bord de business intelligence (BI) en temps réel. L'infrastructure traite les données en streaming provenant des ventes, des interactions client et des systèmes opérationnels avec une faible latence, garantissant que les outils de BI affichent les métriques les plus récentes. Cela permet des informations immédiates sur les indicateurs clés de performance (KPI), permettant aux décideurs de réagir rapidement aux changements du marché, d'identifier les tendances émergentes et d'optimiser les stratégies opérationnelles sans délai, améliorant considérablement l'agilité et la réactivité de l'entreprise.
Activation de l'Analyse en Temps Réel pour les Opérations Commerciales
Les analystes commerciaux et les gestionnaires d'opérations exploitent les solutions de streaming et d'entreposage de données au sein de l'infrastructure de données pour traiter et analyser instantanément les flux de données entrants. Cela permet une surveillance en temps réel des indicateurs clés de performance, une détection immédiate des fraudes et une gestion dynamique des stocks, fournissant des informations critiques pour une prise de décision agile et une réponse rapide aux changements du marché.
Analyse en Temps Réel et Intelligence Économique
Les analystes commerciaux et les décideurs ont besoin d'informations immédiates à partir des données opérationnelles pour réagir rapidement aux changements du marché. L'infrastructure de données fournit la dorsale pour le streaming et le traitement des données en temps réel, permettant l'agrégation et l'analyse instantanées des données entrantes provenant des ventes, des interactions client ou des capteurs IoT. Cette capacité prend en charge les tableaux de bord dynamiques, la détection de fraude et les expériences client personnalisées, permettant des stratégies commerciales proactives et des avantages concurrentiels.
Ingestion de Données en Temps Réel pour l'Analyse Basée sur l'IA
Pour des applications telles que la détection de fraude, les recommandations personnalisées ou la surveillance IoT, les modèles d'IA ont besoin d'accéder à des flux de données frais et en temps réel. Les outils d'infrastructure de données fournissent des pipelines d'ingestion à haut débit qui capturent, traitent et livrent des données en streaming avec une latence minimale. Cela permet aux systèmes d'IA de prendre des décisions immédiates basées sur les données, en répondant aux événements au fur et à mesure qu'ils se produisent et en améliorant considérablement la réactivité et la précision des applications d'IA en temps réel.
Assurer la Gouvernance et la Conformité des Données
Les responsables de la conformité et les intendants des données s'appuient sur l'infrastructure de données pour établir et faire respecter des politiques complètes de gouvernance des données, répondant aux exigences réglementaires telles que le RGPD ou la HIPAA. Ces outils fournissent des mécanismes de suivi du lignage des données, de contrôle d'accès, de masquage des données et d'audit, garantissant l'intégrité et la sécurité des données. En centralisant les efforts de gouvernance, les organisations peuvent minimiser les risques de conformité, maintenir la qualité des données et établir la confiance avec les clients et les parties prenantes, évitant ainsi des pénalités coûteuses et des atteintes à la réputation.
Obtenir une Vue Client à 360 Degrés pour la Personnalisation
Les équipes marketing et de service client utilisent l'infrastructure de données pour consolider les données clients disparates provenant des plateformes CRM, de vente, de médias sociaux et d'analyse web en un profil client unifié. Cette vue complète à 360 degrés permet aux entreprises de comprendre le comportement, les préférences et le parcours client sur tous les points de contact. En tirant parti de ces données intégrées, les entreprises peuvent proposer des campagnes marketing hautement personnalisées, des recommandations de produits sur mesure et un support client proactif, améliorant considérablement la satisfaction client et générant des taux de conversion et une fidélité plus élevés.
Assurer la Gouvernance et la Conformité des Données
Les responsables de la conformité et les gestionnaires de données mettent en œuvre des composants d'infrastructure de données tels que les catalogues de données, la gestion des métadonnées et les contrôles d'accès pour appliquer les politiques de gouvernance des données. Cela garantit la qualité des données, le suivi de la lignée et le respect des réglementations telles que le RGPD ou la HIPAA, atténuant les risques associés aux violations de données et à la non-conformité tout en maintenant l'intégrité des données à l'échelle de l'entreprise.
Stockage et Gouvernance Sécurisés des Données pour la Conformité
Les organisations qui traitent des données clients ou propriétaires sensibles, en particulier dans des secteurs réglementés comme la finance ou la santé, doivent garantir une sécurité et une conformité strictes des données. Les solutions d'infrastructure de données offrent un stockage chiffré, des contrôles d'accès granulaires, le masquage des données et des pistes d'audit pour se conformer aux réglementations telles que le RGPD ou la HIPAA. Cela protège contre les violations de données, maintient la confiance des clients et évite les amendes importantes, garantissant des pratiques de traitement des données légales et éthiques.
Orchestration des Charges de Travail d'Entraînement de Modèles d'IA Distribués
L'entraînement de modèles d'IA à grande échelle, en particulier les réseaux neuronaux profonds, nécessite souvent des ressources de calcul importantes distribuées sur plusieurs GPU ou clusters. Les solutions d'infrastructure de données incluent des capacités d'orchestration qui gèrent ces charges de travail distribuées, allouant les ressources efficacement, surveillant la progression des tâches et gérant les échecs. Cela garantit que les exécutions d'entraînement complexes sont terminées de manière fiable et optimale, maximisant l'utilisation des ressources et accélérant le cycle de développement pour l'IA avancée.
Consolidation des Données Provenant de Sources Disparates
Les architectes de données et les gestionnaires informatiques utilisent l'infrastructure de données pour intégrer et consolider les informations provenant de divers systèmes cloisonnés, tels que les plateformes CRM, ERP et marketing, dans un référentiel de données unifié. Ce processus implique la conception de workflows ETL/ELT efficaces pour extraire, transformer et charger les données, créant ainsi une source unique de vérité. Une vue consolidée des données facilite les rapports complets, l'analyse interfonctionnelle et soutient le développement d'applications d'IA holistiques qui exploitent toutes les données organisationnelles disponibles.
Assurer la Conformité Réglementaire et l'Audit des Données
Les responsables de la conformité et les équipes juridiques des secteurs réglementés, tels que la finance et la santé, s'appuient sur une infrastructure de données robuste pour répondre aux exigences réglementaires strictes comme le RGPD, HIPAA ou CCPA. L'infrastructure fournit un stockage de données sécurisé avec chiffrement, un suivi détaillé du lignage des données et des capacités d'audit complètes. Cela garantit que toutes les opérations de données sont transparentes, traçables et conformes, minimisant les risques juridiques et permettant des réponses rapides aux demandes d'audit en démontrant des politiques de traitement des données, de contrôle d'accès et de rétention appropriées.
Consolidation de Sources de Données Disparates dans un Lac Unifié
Les architectes d'entreprise et les ingénieurs de données utilisent des solutions de lac de données pour centraliser de vastes quantités de données structurées et non structurées provenant de divers systèmes départementaux, d'appareils IoT et de flux externes. Ce référentiel unifié facilite l'exploration complète des données et l'analyse avancée, brisant les silos de données et offrant une vue holistique pour la planification stratégique et l'innovation.
Migrer les Données Héritées vers des Plateformes Cloud-Natives
Les administrateurs informatiques et les architectes cloud sont souvent confrontés au défi de déplacer de grandes quantités de données historiques des systèmes sur site vers des environnements cloud modernes. Les outils d'infrastructure de données facilitent cette migration complexe en fournissant des connecteurs robustes, des mécanismes de validation des données et des capacités de transfert évolutives. Cette transition permet aux organisations de tirer parti de l'élasticité du cloud, de réduire les coûts opérationnels et de débloquer de nouvelles possibilités analytiques avec les services d'IA basés sur le cloud, modernisant ainsi leur paysage de données.
Assurer la Gouvernance et la Sécurité des Données pour les Ensembles de Données d'IA
Les modèles d'IA ne sont aussi bons que les données sur lesquelles ils sont entraînés, et ces données contiennent souvent des informations sensibles. Les outils d'infrastructure de données fournissent des fonctionnalités critiques pour la gouvernance des données, y compris le contrôle d'accès, le chiffrement, le masquage des données et les pistes d'audit. Cela aide les organisations à se conformer aux réglementations comme le RGPD ou la HIPAA, à protéger les données propriétaires et à maintenir l'intégrité et la confidentialité des ensembles de données utilisés pour le développement de l'IA, renforçant la confiance et atténuant les risques.
Optimisation du Stockage de Données pour le Coût et la Performance
Les architectes cloud et les équipes d'opérations de données utilisent des solutions d'infrastructure de données pour optimiser les stratégies de stockage, équilibrant l'efficacité des coûts avec les exigences de performance. Cela inclut la mise en œuvre de stockage hiérarchisé, de compression de données et de politiques intelligentes de gestion du cycle de vie des données pour déplacer les données moins fréquemment consultées vers des niveaux de stockage moins chers tout en maintenant les données critiques facilement disponibles. Une optimisation efficace du stockage réduit les dépenses cloud, améliore les vitesses de récupération des données et garantit que les ressources sont allouées efficacement en fonction de la valeur des données et des modèles d'accès.
Gestion des Données IoT à Grand Volume pour la Maintenance Prédictive
Les ingénieurs industriels et les responsables des opérations dans la fabrication ou la logistique exploitent l'infrastructure de données pour ingérer et traiter des volumes massifs de données générées par les capteurs IoT sur les machines, les véhicules ou les infrastructures. Ce flux de données en temps réel, incluant la température, les vibrations et les métriques de performance, est analysé pour identifier les anomalies et prédire les pannes potentielles d'équipement. En mettant en œuvre des stratégies de maintenance prédictive basées sur ces informations, les entreprises peuvent minimiser les temps d'arrêt, réduire les coûts de réparation et prolonger la durée de vie des actifs critiques, optimisant l'efficacité opérationnelle et prévenant les perturbations coûteuses.
Optimisation du Stockage de Données pour le Coût et la Performance
Les administrateurs informatiques et les architectes cloud déploient des solutions de stockage hiérarchisé et d'archivage de données au sein de l'infrastructure de données pour gérer efficacement le cycle de vie des données. En catégorisant les données en fonction de la fréquence d'accès et des politiques de rétention, ils peuvent déplacer les données moins fréquemment consultées vers des niveaux de stockage plus rentables, équilibrant les exigences de performance avec les contraintes budgétaires et assurant la disponibilité des données à long terme.
Soutenir le Déploiement de Modèles d'Apprentissage Automatique à Grande Échelle
Après l'entraînement, le déploiement de modèles d'apprentissage automatique en production nécessite une couche de service de données stable et performante. L'infrastructure de données garantit que les modèles peuvent accéder aux fonctionnalités nécessaires et aux données d'inférence avec une faible latence et un débit élevé. Cela implique des magasins de données optimisés, des mécanismes de mise en cache et une intégration avec les plateformes de service de modèles. Une infrastructure bien conçue garantit que les applications d'IA déployées fournissent des prédictions et des recommandations cohérentes et en temps réel aux utilisateurs finaux.
Automatisation des Pipelines ETL pour l'Ingénierie des Caractéristiques en Apprentissage Automatique
Avant que les données ne puissent être utilisées pour l'apprentissage automatique, elles nécessitent souvent un nettoyage, une transformation et une ingénierie des caractéristiques approfondis. Les outils d'infrastructure de données automatisent ces processus d'extraction, de transformation et de chargement (ETL), permettant aux ingénieurs de données de construire des pipelines reproductibles qui préparent les données pour la consommation du modèle. Cela réduit l'effort manuel, assure la cohérence des données et accélère le temps d'obtention d'informations pour les projets d'apprentissage automatique, fournissant des caractéristiques bien structurées pour une performance optimale du modèle.
Soutien aux Projets de Migration de Données à Grande Échelle
Les chefs de projet informatique et les spécialistes de la migration utilisent une infrastructure de données robuste pour planifier et exécuter des projets de migration de données à grande échelle, tels que le déplacement de données de systèmes sur site vers le cloud ou la consolidation de plusieurs bases de données héritées. Ces outils offrent des capacités de profilage, de nettoyage, de mappage et de transfert sécurisé des données, minimisant les temps d'arrêt et garantissant l'intégrité des données tout au long du processus de migration. Une infrastructure de migration de données bien gérée atténue les risques, accélère l'achèvement du projet et assure une transition en douceur vers de nouveaux environnements de données.
Établissement d'un Lac de Données Évolutif pour l'Analyse Big Data
Les architectes d'entreprise et les ingénieurs de données conçoivent et mettent en œuvre une infrastructure de données pour créer des lacs de données évolutifs capables de stocker divers types de données, y compris des données brutes, semi-structurées et non structurées, à des échelles massives. Cela sert de référentiel central pour l'analyse de big data, permettant aux scientifiques des données d'effectuer des analyses exploratoires, de construire de nouveaux modèles de données et de préparer des ensembles de données pour de futurs projets d'IA sans les contraintes des entrepôts de données traditionnels. L'infrastructure du lac de données prend en charge des approches flexibles de schéma à la lecture, permettant l'agilité dans l'exploration des données et favorisant l'innovation au sein de l'organisation.
Prise en Charge des Environnements de Données Hybrides et Multi-Cloud
Les architectes cloud et les équipes DevOps utilisent des outils d'infrastructure de données offrant une intégration et une gestion transparentes entre les plateformes sur site et multi-cloud. Cela permet aux organisations de tirer parti des meilleures fonctionnalités des différents environnements, d'assurer la portabilité des données et de maintenir la continuité des activités, offrant flexibilité et résilience pour les stratégies de données évolutives sans dépendance vis-à-vis d'un fournisseur.
Gestion des Lacs de Données pour les Données Non Structurées
Les ingénieurs et chercheurs en données travaillent fréquemment avec divers types de données non structurées tels que des images, des vidéos, de l'audio et du texte, qui sont essentiels pour les applications d'IA avancées comme la vision par ordinateur et le traitement du langage naturel. L'infrastructure de données fournit des solutions de lac de données qui peuvent stocker des données brutes, avec un schéma à la lecture, à grande échelle. Cela permet une exploration et une expérimentation flexibles avec divers formats de données, permettant le développement de modèles d'IA innovants qui peuvent dériver des informations à partir d'informations auparavant inaccessibles.
Surveillance et Gestion des Performances des Applications d'IA
Une fois les modèles d'IA déployés, leurs performances et l'infrastructure de données sous-jacente nécessitent une surveillance continue. Les outils de cette catégorie offrent des capacités complètes de surveillance, de journalisation et d'alerte pour les pipelines de données, les systèmes de stockage et les ressources de calcul. Cela permet aux équipes d'exploitation d'identifier et de résoudre rapidement les goulots d'étranglement, d'assurer la santé du flux de données et de maintenir la fiabilité et l'efficacité des applications basées sur l'IA dans les environnements de production, prévenant ainsi les interruptions de service.