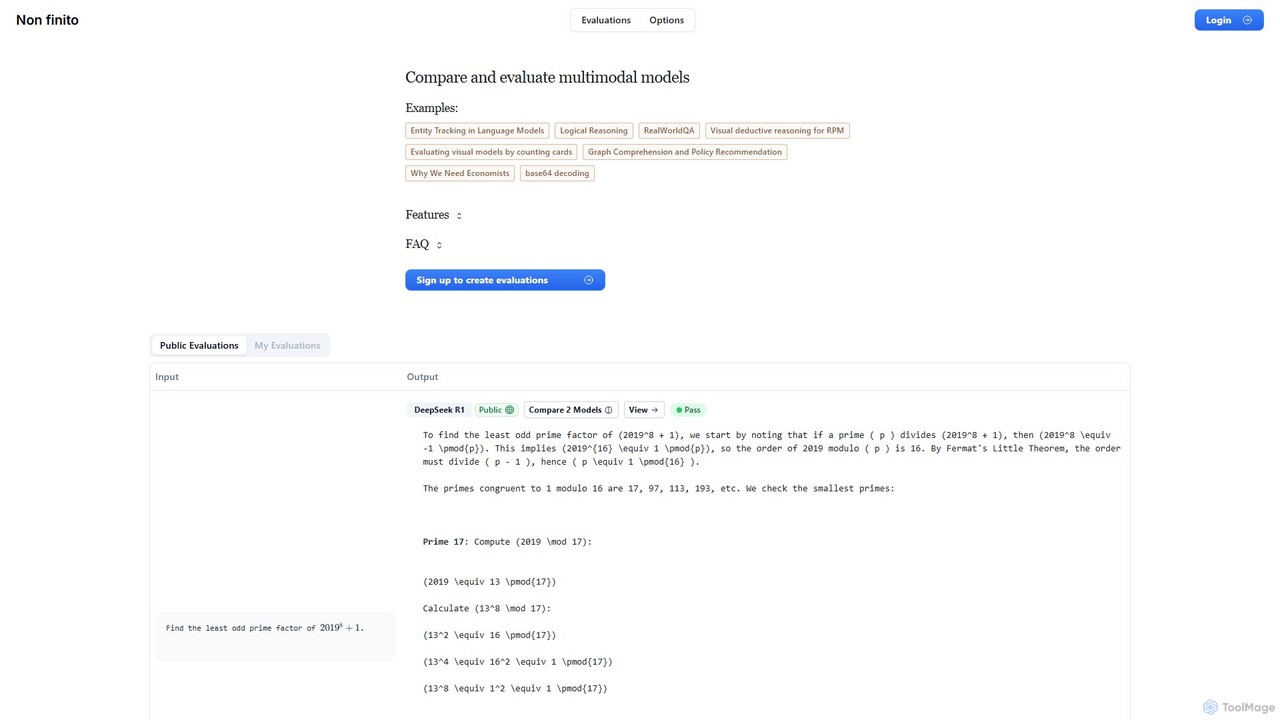
nonfinito
nonfinito est une plateforme complète pour évaluer et comparer les modèles d'IA multimodaux. Elle permet aux développeurs, chercheurs …
nonfinito est une plateforme complète pour évaluer et comparer les modèles d'IA multimodaux. Elle permet aux développeurs, chercheurs et entreprises de tester divers LLM côte à côte sur des prompts personnalisés, d'évaluer leurs performances avec des notations de réussite/échec et d'analyser les sorties brutes. Créez des benchmarks publics ou privés pour trouver le meilleur modèle pour n'importe quelle tâche.
À propos de Benchmarking
Les outils de Benchmarking IA sont des plateformes spécialisées pour évaluer et comparer systématiquement les performances des modèles et systèmes d'intelligence artificielle. Ils fonctionnent en exécutant des tests standardisés ou des invites personnalisées sur différents modèles pour mesurer des métriques clés telles que la précision, la vitesse, le coût et la qualité des résultats. Cela permet aux développeurs, chercheurs et entreprises de prendre des décisions basées sur les données lors de la sélection, de l'ajustement ou du déploiement de solutions d'IA. En tant qu'élément clé de l'écosystème de la Productivité, ces outils garantissent que les composants d'IA choisis sont les plus efficaces et efficients pour une tâche donnée, optimisant directement les flux de travail et les résultats.
Fonctionnalités Clés
- Métriques de Performance des Modèles : Mesurent des critères objectifs tels que la précision, la latence, le débit et d'autres scores pertinents (par ex., BLEU, ROUGE).
- Tableaux de Classement Comparatifs : Fournissent des comparaisons côte à côte de plusieurs modèles d'IA sur les mêmes tâches pour une évaluation claire.
- Ensembles de Données Standardisés : Utilisent des benchmarks reconnus par l'industrie (par ex., MMLU, HumanEval) pour une évaluation objective et reproductible.
- Analyse Coût-Performance : Calculent et comparent les coûts d'API par rapport à la qualité des résultats de différents modèles pour déterminer le ROI.
- Création de Tests Personnalisés : Permettent aux utilisateurs de créer et d'exécuter leurs propres tests en utilisant leurs données, invites et critères d'évaluation spécifiques.
Cas d'Utilisation
Ces outils sont largement utilisés par les développeurs d'IA pour la sélection de modèles, les scientifiques des données pour la validation de modèles affinés et les chefs de produit pour évaluer le ROI de différentes intégrations d'IA. En entreprise, ils sont cruciaux pour les tests de régression et pour garantir des performances d'IA constantes dans le temps après les mises à jour des modèles.
Comment Choisir
Lors de la sélection d'un outil de Benchmarking IA, tenez compte de la gamme de modèles pris en charge (par ex., LLM, modèles d'image), de la disponibilité de benchmarks pertinents de l'industrie et de la flexibilité pour créer des suites d'évaluation personnalisées. Évaluez également ses capacités d'intégration avec votre flux de travail de développement existant et la clarté de ses tableaux de bord de reporting et d'analyse.
BenchmarkingCas d'utilisation
Sélectionner le meilleur LLM pour le support client
Une entreprise technologique doit créer un chatbot IA pour traiter les demandes des clients. Elle utilise un outil de benchmarking pour tester trois LLM de premier plan (par ex., GPT-4, Claude 3, Gemini Pro) sur un ensemble de données de 1 000 tickets de support client réels. L'outil mesure automatiquement la précision des réponses, les scores de politesse et la latence de l'API pour chaque modèle. Le classement qui en résulte montre clairement quel modèle offre le meilleur équilibre entre qualité et vitesse pour leurs besoins spécifiques, permettant une décision confiante et basée sur les données pour leur équipe de développement.
Évaluation des améliorations d'un modèle affiné
Une équipe de science des données affine un modèle open-source pour l'analyse de documents juridiques. Pour prouver sa valeur, elle utilise une plateforme de benchmarking pour comparer la version affinée au modèle original et à un modèle propriétaire. En exécutant une suite de tests personnalisée de 200 requêtes juridiques, elle génère un rapport montrant une augmentation de 15 % de la précision dans l'identification des clauses contractuelles. Ce résultat quantitatif justifie l'investissement dans l'affinage et fournit une preuve claire de l'amélioration des performances aux parties prenantes.
Optimisation des invites pour les textes marketing
Une équipe marketing doit générer des textes publicitaires de haute qualité à grande échelle. Elle utilise un outil de benchmarking pour effectuer des tests A/B sur 20 variations d'invites différentes sur plusieurs modèles d'IA. L'outil automatise le processus et note les résultats en fonction de critères de qualité prédéfinis, tels que la clarté et la force de l'appel à l'action. Cette approche basée sur les données les aide à identifier la combinaison invite-modèle la plus performante, qui peut ensuite être intégrée dans leur flux de travail de contenu pour produire de manière cohérente des supports de campagne plus efficaces.
Tests de régression du système d'IA
Une entreprise met à jour le modèle d'IA principal de son système de gestion des connaissances interne. Avant le déploiement, l'équipe d'assurance qualité utilise un outil de benchmarking pour exécuter un ensemble prédéfini de 500 tests couvrant les fonctionnalités clés. L'outil compare les résultats du nouveau modèle à la base de référence de la version précédente, signalant toute baisse de performance significative. Cela garantit que les mises à jour n'introduisent pas de régressions par inadvertance, maintenant ainsi la fiabilité du système et la confiance des utilisateurs.
Contrôle des coûts de l'API d'IA
L'application d'une startup dépend fortement d'une API de conversion de texte en image, et les coûts augmentent. Ils utilisent un outil de benchmarking pour évaluer trois modèles alternatifs moins chers. Ils testent tous les modèles sur 100 invites représentatives, en comparant la qualité de l'image de sortie, le respect du style et le coût par image. L'analyse révèle un modèle 40 % moins cher tout en répondant à 90 % de leurs exigences de qualité. Ces données leur permettent d'effectuer un changement stratégique, réduisant considérablement les coûts opérationnels sans compromis majeur sur la qualité du produit.
Recherche académique sur les capacités des modèles
Des chercheurs universitaires étudient les capacités de raisonnement des LLM émergents. Ils exploitent une plateforme de benchmarking pour exécuter systématiquement le benchmark ARC (AI2 Reasoning Challenge) sur cinq modèles open-source différents. La plateforme automatise l'exécution, collecte les résultats et fournit des outils de visualisation pour l'analyse. Cela accélère considérablement leur processus de recherche, leur permettant de se concentrer sur l'interprétation des données et la publication de leurs résultats comparatifs plutôt que sur la configuration et l'exécution manuelles des tests.