Datacurve
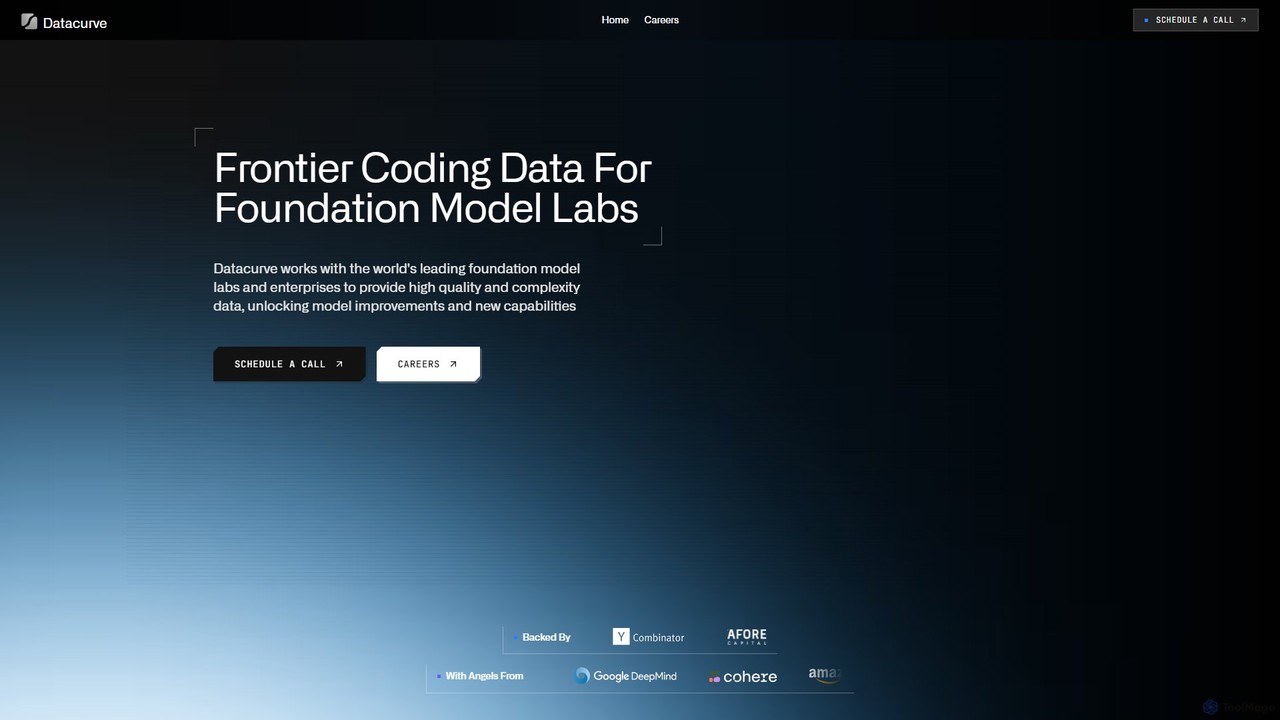
Datacurveは、高度なAI基盤モデルのトレーニングと評価のための、高品質で複雑なコーディングデータを提供します。SFT、RLHF、エージェントワークフローのトレースといった形式に特化し、14,000人以上のエンジニアが参加するゲーミフィケーション化されたプラットフォームを活用して、最先端のデータを生成します。優れたデータ品質、スケール、スピードを通じて、新たなモデルの能力を解放し、性能を向上させたいと考える主要なAIラボや企業向けに設計されています。
Datacurveは、高度なAI基盤モデルのトレーニングと評価のための、高品質で複雑なコーディングデータを提供します。SFT、RLHF、エージェントワークフローのトレースといった形式に特化し、14,000人以上のエンジニアが参加するゲーミフィケーション化されたプラットフォームを活用して、最先端のデータを生成します。優れたデータ品質、スケール、スピードを通じて、新たなモデルの能力を解放し、性能を向上させたいと考える主要なAIラボや企業向けに設計されています。
Forefront
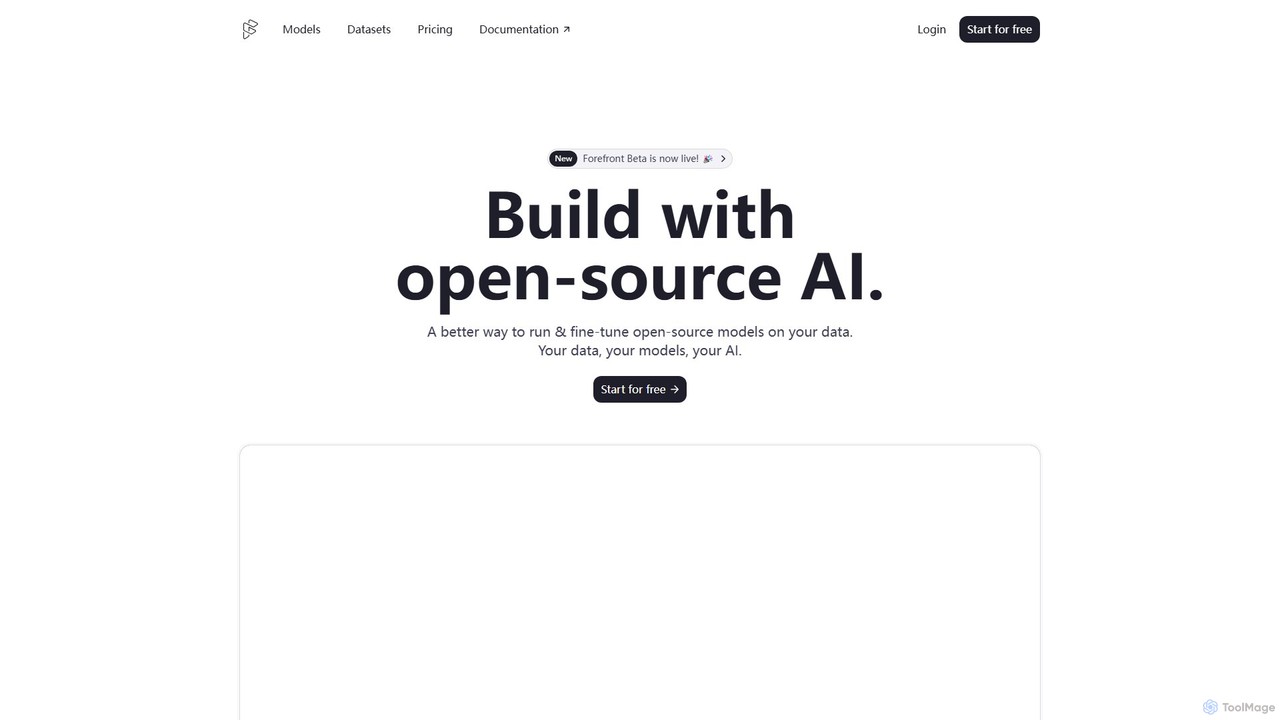
Forefrontは、開発者向けのオープンソースAI構築プラットフォームです。プライベートデータ上で大規模言語モデル(LLM)の実行、ファインチューニング、デプロイを簡素化し、クローズドソースプラットフォームに代わるスケーラブルで安全、かつコスト効率の高い選択肢を提供します。あなたのデータ、モデル、AIを所有しましょう。
Forefrontは、開発者向けのオープンソースAI構築プラットフォームです。プライベートデータ上で大規模言語モデル(LLM)の実行、ファインチューニング、デプロイを簡素化し、クローズドソースプラットフォームに代わるスケーラブルで安全、かつコスト効率の高い選択肢を提供します。あなたのデータ、モデル、AIを所有しましょう。
FinetuneDB
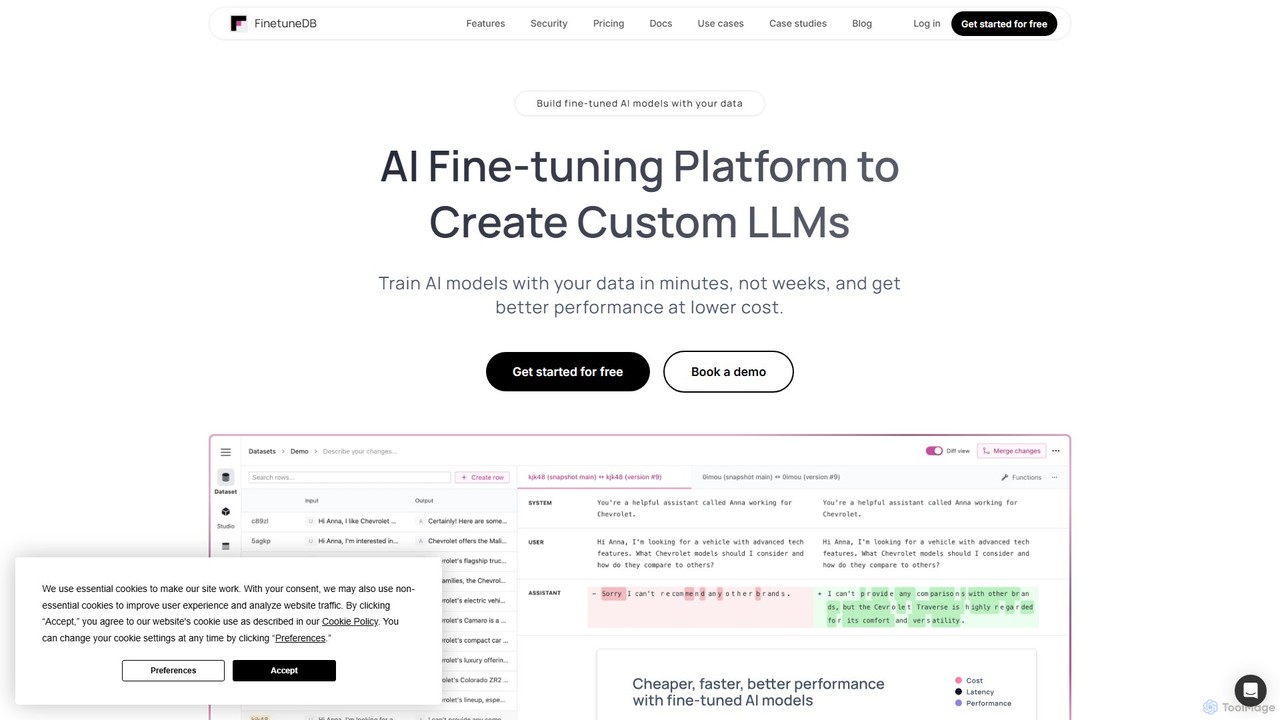
FinetuneDBは、開発者向けのオールインワンAIファインチューニングプラットフォームです。高品質なデータセットの構築、Llama 3やGPT-4o miniなどのモデルのファインチューニングから、単一の安全なプラットフォーム上でのデプロイと継続的な評価まで、カスタム大規模言語モデル(LLM)作成の全ワークフローを簡素化します。
FinetuneDBは、開発者向けのオールインワンAIファインチューニングプラットフォームです。高品質なデータセットの構築、Llama 3やGPT-4o miniなどのモデルのファインチューニングから、単一の安全なプラットフォーム上でのデプロイと継続的な評価まで、カスタム大規模言語モデル(LLM)作成の全ワークフローを簡素化します。
Ocular AI
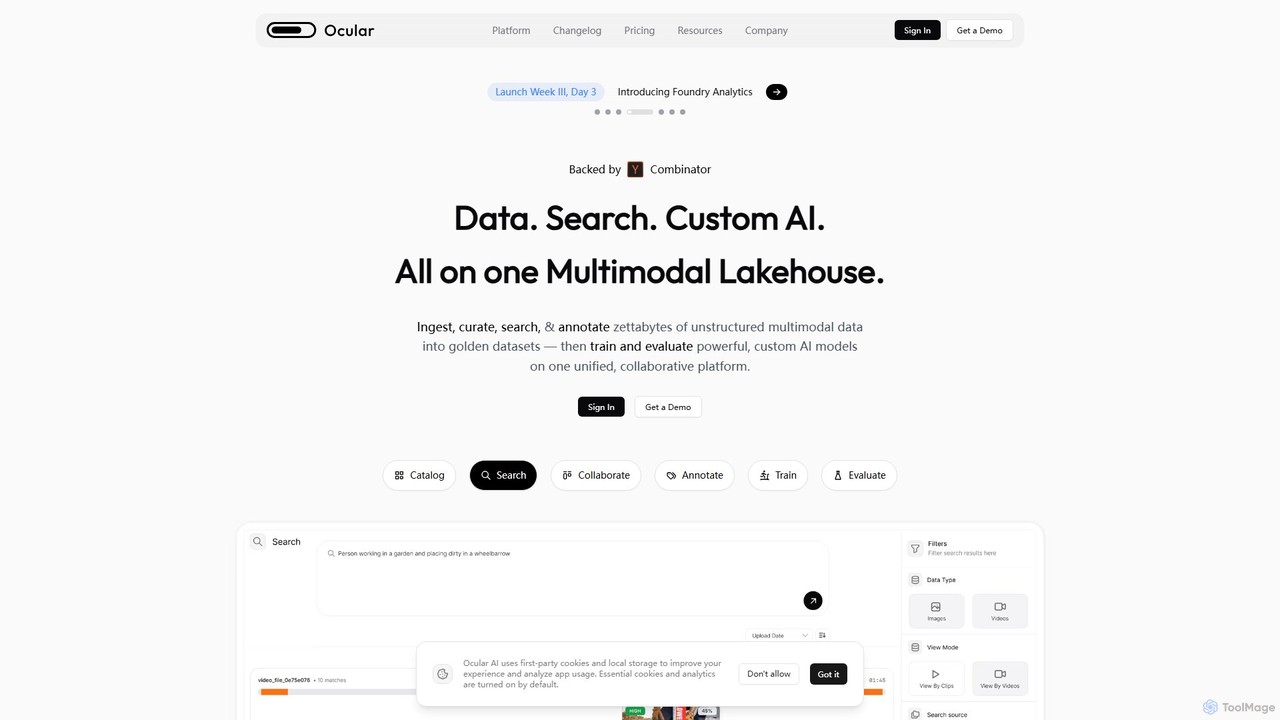
Ocular AIは、マルチモーダルAI時代のエンドツーエンドプラットフォームであり、チームがゼタバイト規模の非構造化データを取り込み、キュレーション、検索、注釈付けできるようにします。統一されたマルチモーダルデータレイクハウス、高度な検索、カスタムAIモデルのトレーニングと評価のためのツールを提供し、AI開発ライフサイクル全体を加速させます。
Ocular AIは、マルチモーダルAI時代のエンドツーエンドプラットフォームであり、チームがゼタバイト規模の非構造化データを取り込み、キュレーション、検索、注釈付けできるようにします。統一されたマルチモーダルデータレイクハウス、高度な検索、カスタムAIモデルのトレーニングと評価のためのツールを提供し、AI開発ライフサイクル全体を加速させます。
Surge AI
Surge AIは、高度なAIおよびAGIの開発を支援するために、エリートレベルのヒューマンインテリジェンスを提供する最高のデータラベリングプラットフォームです。RLHF、モデル評価、カスタムデータセット作成のための高品質データに特化し、OpenAIやAnthropicなどの主要なAIラボと提携して、次世代モデルのトレーニング、アライメント、テストを行っています。真に知的なシステムを構築するために必要なニュアンスと複雑さに焦点を当てています。
Surge AIは、高度なAIおよびAGIの開発を支援するために、エリートレベルのヒューマンインテリジェンスを提供する最高のデータラベリングプラットフォームです。RLHF、モデル評価、カスタムデータセット作成のための高品質データに特化し、OpenAIやAnthropicなどの主要なAIラボと提携して、次世代モデルのトレーニング、アライメント、テストを行っています。真に知的なシステムを構築するために必要なニュアンスと複雑さに焦点を当てています。
MonsterAPI
MonsterAPIは、オープンソースの生成AIモデルのファインチューニングとデプロイを簡素化する開発者中心のプラットフォームです。Llama、SDXL、Whisperなどのモデルをサポートするノーコードのチャットインターフェース「MonsterGPT」を提供します。このプラットフォームは、スケーラブルなAPIエンドポイントとエンタープライズ級のGPUインフラを、従来の数分の一のコストと時間で提供し、高度なAIをすべての開発者が利用できるようにします。
MonsterAPIは、オープンソースの生成AIモデルのファインチューニングとデプロイを簡素化する開発者中心のプラットフォームです。Llama、SDXL、Whisperなどのモデルをサポートするノーコードのチャットインターフェース「MonsterGPT」を提供します。このプラットフォームは、スケーラブルなAPIエンドポイントとエンタープライズ級のGPUインフラを、従来の数分の一のコストと時間で提供し、高度なAIをすべての開発者が利用できるようにします。
prompteasy.ai
prompteasy.aiは、GPTモデルのファインチューニングプロセスを簡素化するノーコードプラットフォームです。ユーザーはAIアシスタントとチャットすることで、コピーライティングや感情分析など、特定のニーズに合わせたカスタムデータセットを技術的なスキルなしで生成できます。これにより、高度なAIカスタマイズが誰にでも利用可能になります。
prompteasy.aiは、GPTモデルのファインチューニングプロセスを簡素化するノーコードプラットフォームです。ユーザーはAIアシスタントとチャットすることで、コピーライティングや感情分析など、特定のニーズに合わせたカスタムデータセットを技術的なスキルなしで生成できます。これにより、高度なAIカスタマイズが誰にでも利用可能になります。
モデル学習について
モデル学習ツールは、機械学習モデルの構築、学習、最適化を行うための専門的な開発者向けプラットフォームです。データセットの管理、実験の実行、パフォーマンス指標の追跡を行う構造化された環境を提供し、モデルの精度を向上させます。これらのツールは、言語モデルのファインチューニングから予測分析システムの開発まで、カスタムAIソリューションを作成するために不可欠です。機械学習開発の反復プロセスを合理化し、データサイエンティストやエンジニアがより堅牢で効果的なモデルを迅速に構築できるようにします。
主な機能
- 実験追跡:複数の学習実行にわたる損失や精度などの指標を記録、比較、視覚化します。
- データとモデルのバージョン管理:データセットと学習済みモデルの異なるバージョンを管理し、再現性を確保します。
- ハイパーパラメータ最適化:最高のパフォーマンスを達成するために、最適なモデル構成の探索を自動化します。
- 分散学習サポート:複数のGPUやクラウドインスタンスに学習をスケールさせ、大規模なデータセットに対応します。
- フレームワーク統合:TensorFlow、PyTorch、JAXなどの主要なMLフレームワークとシームレスに連携します。
利用シーン
これらのツールは、コンピュータビジョン、自然言語処理(NLP)、金融などの分野で、MLエンジニア、データサイエンティスト、研究者によって広く利用されています。カスタム物体検出モデルの作成、特定ドメイン向けの大規模言語モデルのファインチューニング、不正検出システムの構築などのタスクに不可欠です。
選択のポイント
モデル学習ツールを選ぶ際は、好みのMLフレームワークのサポート、大規模学習のスケーラビリティ、チームベースのプロジェクトのためのコラボレーション機能を考慮してください。また、使いやすさ(コード中心かローコードか)、既存のデータインフラとの統合、計算使用量に基づく価格モデルも評価する必要があります。
モデル学習利用シーン
カスタマーサービス向け言語モデルのファインチューニング
SaaS企業のMLチームは、モデル学習プラットフォームを使用して、社内のナレッジベースと過去のサポートチケットで事前学習済み言語モデルをファインチューニングします。このプラットフォームにより、異なる学習率やデータセットでの実験を追跡できます。最終的なモデルはヘルプデスクに統合され、顧客の問い合わせに即座に文脈を理解した回答を提供し、応答時間を70%削減し、人間のエージェントがより複雑な問題に対応できるようにします。
カスタムコンピュータビジョンモデルの学習
ある小売企業は、防犯カメラの映像を使って在庫確認を自動化したいと考えています。データサイエンティストは、モデル学習ツールを使用して商品画像のデータセットを管理し、カスタムの物体検出モデルを学習させます。プラットフォームの実験追跡機能により、異なるモデルアーキテクチャやデータ拡張技術のパフォーマンスを比較できます。完成したモデルは、棚の商品を正確に識別・計数でき、これまで手作業だったプロセスを自動化します。
解約予測のための予測分析モデルの開発
ある金融サービス企業は、顧客の解約を予測することを目指しています。アナリストはモデル学習プラットフォームを使用して、過去の顧客データで勾配ブースティングモデルを学習させます。ツールのバージョン管理機能により、監査目的でデータとモデルの両方が再現可能であることが保証されます。学習済みのモデルは、リスクのある顧客を高い精度で特定し、マーケティングチームがターゲットを絞った維持キャンペーンを開始し、全体の解約率を低下させることを可能にします。
パーソナライズされた推薦エンジンの構築
eコマースプラットフォームの開発者は、パーソナライズされた商品推薦を提供するために協調フィルタリングモデルを学習させます。彼らはモデル学習ツールを使用してユーザーのインタラクションデータを管理し、クラウドGPUクラスターで分散学習ジョブを実行します。このプラットフォームは学習のスケールアッププロセスを簡素化し、毎日新しいデータでモデルを再学習させることで、推薦の関連性を保ち、ユーザーエンゲージメントを高めることができます。
ML研究実験の追跡と比較
大学の研究グループが、医用画像解析のための新しいニューラルネットワークアーキテクチャを研究しています。彼らはモデル学習プラットフォームを中央ハブとして使用し、コードのバージョン、ハイパーパラメータ、出力メトリクスを含むすべての実験を記録します。これにより、研究者は結果を簡単に比較し、共同研究者と知見を共有し、成功した実験を再現することができ、研究のペースを大幅に加速させ、科学的な厳密性を確保します。
最適なパフォーマンスのためのハイパーパラメータチューニングの自動化
MLエンジニアは、不正検出モデルの最適化を任されています。何百ものパラメータの組み合わせを手動でテストする代わりに、モデル学習ツールの自動ハイパーパラメータチューニング機能を使用します。学習率や木の深さなどのパラメータの探索空間を定義すると、プラットフォームが自動的に実験を実行して最適な構成を見つけ出します。これにより、数日間の手作業が節約され、精度が大幅に向上し、誤検知が少ないモデルが得られます。