Wirestock
Wirestock é um mercado que conecta freelancers criativos a empresas de IA, permitindo que criadores ganhem dinheiro contribuindo …
Wirestock é um mercado que conecta freelancers criativos a empresas de IA, permitindo que criadores ganhem dinheiro contribuindo com imagens, vídeos e ilustrações de alta qualidade para conjuntos de dados de treinamento de IA.
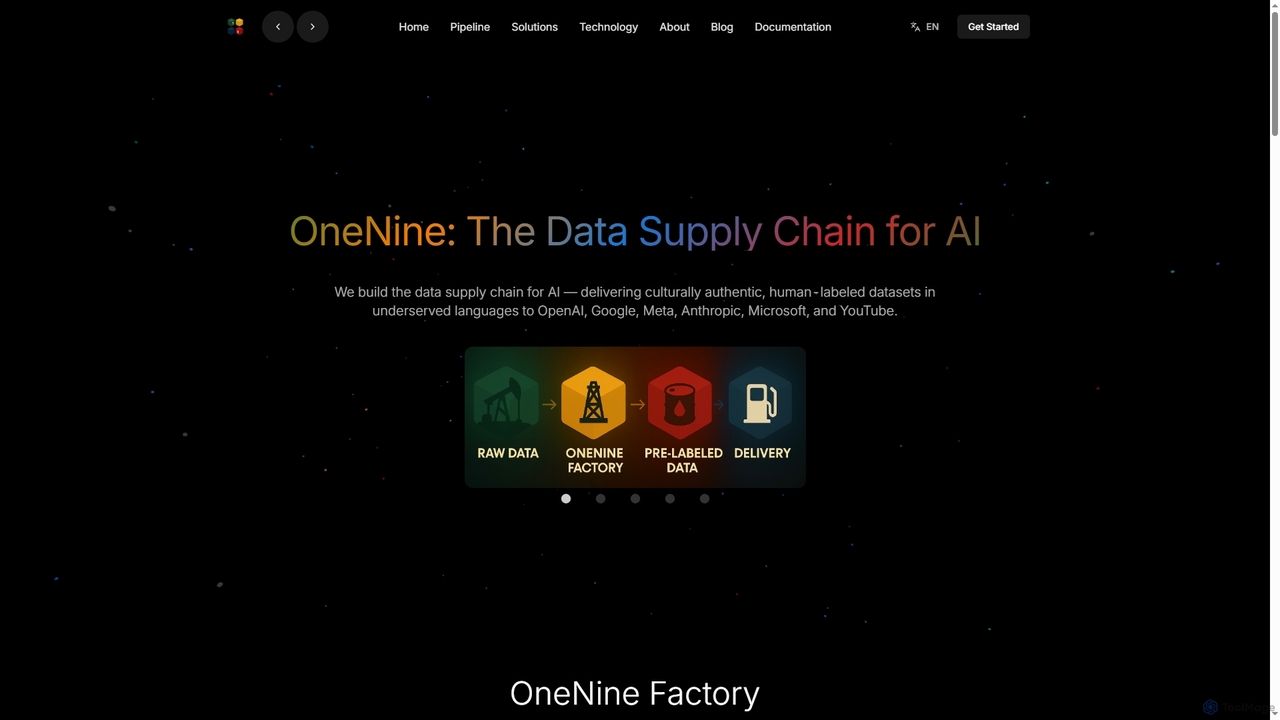
OneNine
OneNine é a cadeia de suprimentos de dados para IA, especializada em fornecer conjuntos de dados rotulados por …
OneNine é a cadeia de suprimentos de dados para IA, especializada em fornecer conjuntos de dados rotulados por humanos, culturalmente autênticos e de alta qualidade em idiomas sub-representados para empresas líderes de IA. Ele preenche a lacuna linguística, permitindo modelos de IA mais inclusivos e precisos globalmente.

Sapien
A Sapien é uma fundição de dados descentralizada que fornece dados de treinamento de IA de nível empresarial. …
A Sapien é uma fundição de dados descentralizada que fornece dados de treinamento de IA de nível empresarial. Ela utiliza uma rede global de contribuidores humanos para entregar dados especializados e de alta qualidade para sistemas de IA complexos, incluindo anotação 3D/4D, raciocínio de especialistas e coleta de dados em larga escala.
Sobre Dados de Treinamento
As ferramentas de Dados de Treinamento são plataformas e serviços projetados para criar, gerenciar e fornecer conjuntos de dados de alta qualidade para modelos de aprendizado de máquina. Essas ferramentas otimizam o processo crítico de preparação de dados, oferecendo funcionalidades para anotação de dados, geração de dados sintéticos e garantia de qualidade. Seu valor principal reside em acelerar o desenvolvimento de sistemas de IA precisos e robustos, já que o desempenho de qualquer modelo depende fundamentalmente da qualidade de seus dados de treinamento. Como um componente chave do ciclo de vida de Desenvolvimento de IA, elas formam a base sobre a qual modelos eficazes são construídos.
Recursos Principais
- Anotação e Rotulagem de Dados: Fornece interfaces e ferramentas automatizadas para marcar com precisão vários tipos de dados, como imagens, texto e áudio, para criar a verdade fundamental para os modelos.
- Geração de Dados Sintéticos: Cria dados artificiais, porém realistas, para aumentar conjuntos de dados limitados, cobrir casos extremos ou proteger informações sensíveis.
- Gerenciamento e Versionamento de Dados: Oferece uma plataforma centralizada para armazenar, rastrear e gerenciar diferentes versões de conjuntos de dados, garantindo a reprodutibilidade dos experimentos.
- Fluxos de Trabalho de Garantia de Qualidade: Inclui recursos para revisão, consenso e detecção de erros para manter altos padrões de precisão e consistência dos dados.
- Fornecimento de Conjuntos de Dados: Fornece acesso a conjuntos de dados pré-rotulados e prontos para uso ou serviços para coletar e preparar dados personalizados.
Casos de Uso
Essas ferramentas são essenciais em indústrias com uso intensivo de dados, como veículos autônomos para detecção de objetos, saúde para análise de imagens médicas e varejo para categorização de produtos. Engenheiros de aprendizado de máquina, cientistas de dados e pesquisadores de IA as utilizam diariamente para construir e refinar conjuntos de dados para tarefas que vão desde o processamento de linguagem natural até a visão computacional.
Como Escolher
Ao selecionar uma ferramenta de Dados de Treinamento, considere o suporte para seus tipos de dados específicos (por exemplo, vídeo, nuvens de pontos 3D). Avalie os mecanismos de controle de qualidade, como funções de revisor e pontuação de consenso. Analise sua escalabilidade para projetos de grande porte e sua capacidade de integração com seu pipeline de MLOps e armazenamento em nuvem existentes. Por fim, verifique seus protocolos de segurança e conformidade com regulamentações de privacidade de dados como GDPR ou HIPAA.
Dados de TreinamentoCenários de aplicação
Treinamento de Modelos de Percepção para Veículos Autônomos
Uma empresa de tecnologia automotiva que desenvolve carros autônomos precisa treinar seus modelos de visão computacional para identificar com precisão pedestres, veículos, sinais de trânsito e marcações de faixa. Usando uma plataforma de anotação de dados, uma equipe de rotuladores realiza segmentação semântica e anotação de caixas delimitadoras em milhões de imagens e quadros de vídeo capturados em testes de estrada. Os recursos de controle de qualidade da plataforma, como pontuação de consenso e fluxos de trabalho de revisão, garantem alta precisão. Este conjunto de dados meticulosamente rotulado é crucial para treinar modelos de percepção que possam navegar com segurança em ambientes urbanos complexos.
Desenvolvimento de uma IA para Diagnóstico por Imagem Médica
Um instituto de pesquisa em saúde pretende construir um modelo de IA para detectar tumores em estágio inicial em exames de ressonância magnética. Devido à escassez de radiologistas especializados e ao alto custo da anotação manual, eles usam uma ferramenta especializada de anotação de imagens médicas. Esta ferramenta oferece recursos como suporte a DICOM e segmentação semiautomatizada, o que acelera o processo. Para proteger a privacidade do paciente, todos os dados são anonimizados na plataforma. O conjunto de dados rotulado de alta qualidade resultante permite que a equipe de ciência de dados treine um modelo que pode auxiliar os radiologistas, destacando áreas de potencial preocupação, levando a diagnósticos mais precoces e precisos.
Geração de Dados Sintéticos para Detecção de Fraude
Uma empresa de serviços financeiros deseja aprimorar seu modelo de detecção de fraudes, mas é limitada pelo pequeno número de exemplos reais de fraude e por regulamentações rígidas de privacidade de dados. Eles usam uma ferramenta de geração de dados sintéticos para criar um conjunto de dados grande e balanceado de transações financeiras. A ferramenta modela as propriedades estatísticas de seus dados reais para gerar registros de transações realistas, mas totalmente artificiais, incluindo cenários complexos de fraude que são raros no mundo real. Isso permite que eles treinem um modelo mais robusto sem usar dados sensíveis de clientes, melhorando as taxas de detecção e mantendo a conformidade total.
Melhorando a Categorização de Produtos de E-commerce
Um gigante do varejo online gerencia milhões de produtos, e categorizar manualmente novos itens é lento e propenso a erros. Eles empregam um serviço de rotulagem de dados para classificar um grande conjunto de dados de imagens e descrições de produtos. O serviço usa uma combinação de anotadores humanos e pré-rotulagem com tecnologia de IA para categorizar eficientemente os produtos em uma taxonomia detalhada. Esses dados rotulados são então usados para treinar um modelo de aprendizado de máquina que atribui automaticamente categorias a novos produtos carregados no site, reduzindo significativamente o esforço manual, melhorando a relevância da busca e aprimorando a experiência de compra do cliente.
Gerenciamento de Conjuntos de Dados para Reprodutibilidade de Modelos de PNL
Um laboratório de pesquisa em IA está desenvolvendo um novo modelo de linguagem e precisa realizar centenas de experimentos com diferentes versões de seu corpus de texto. Para garantir que seus resultados sejam reprodutíveis, eles usam uma plataforma de gerenciamento e versionamento de dados. Esta ferramenta permite que eles rastreiem cada alteração no conjunto de dados, vinculem versões específicas do conjunto de dados a execuções de treinamento de modelos e revertam facilmente para estados anteriores. Funciona como um 'Git para dados', fornecendo uma trilha de auditoria clara e evitando confusão. Essa abordagem sistemática é vital para a pesquisa colaborativa e para a publicação de descobertas científicas verificáveis.
Auditoria de Viés em Conjuntos de Dados para Algoritmos de Contratação
Uma empresa de tecnologia de recursos humanos está construindo uma ferramenta de IA para ajudar a triar currículos. Para evitar a perpetuação de vieses históricos, eles usam uma ferramenta de garantia de qualidade de dados para auditar seu conjunto de dados de treinamento. A ferramenta analisa a distribuição de dados demográficos (por exemplo, gênero, etnia) e identifica desequilíbrios ou correlações potenciais que poderiam levar a resultados injustos. Ela fornece visualizações e relatórios estatísticos que ajudam a equipe de ciência de dados a identificar e mitigar o viés antes do treinamento do modelo. Este passo proativo é essencial para o desenvolvimento de sistemas de IA responsáveis e éticos que promovam práticas de contratação justas.