Edgee
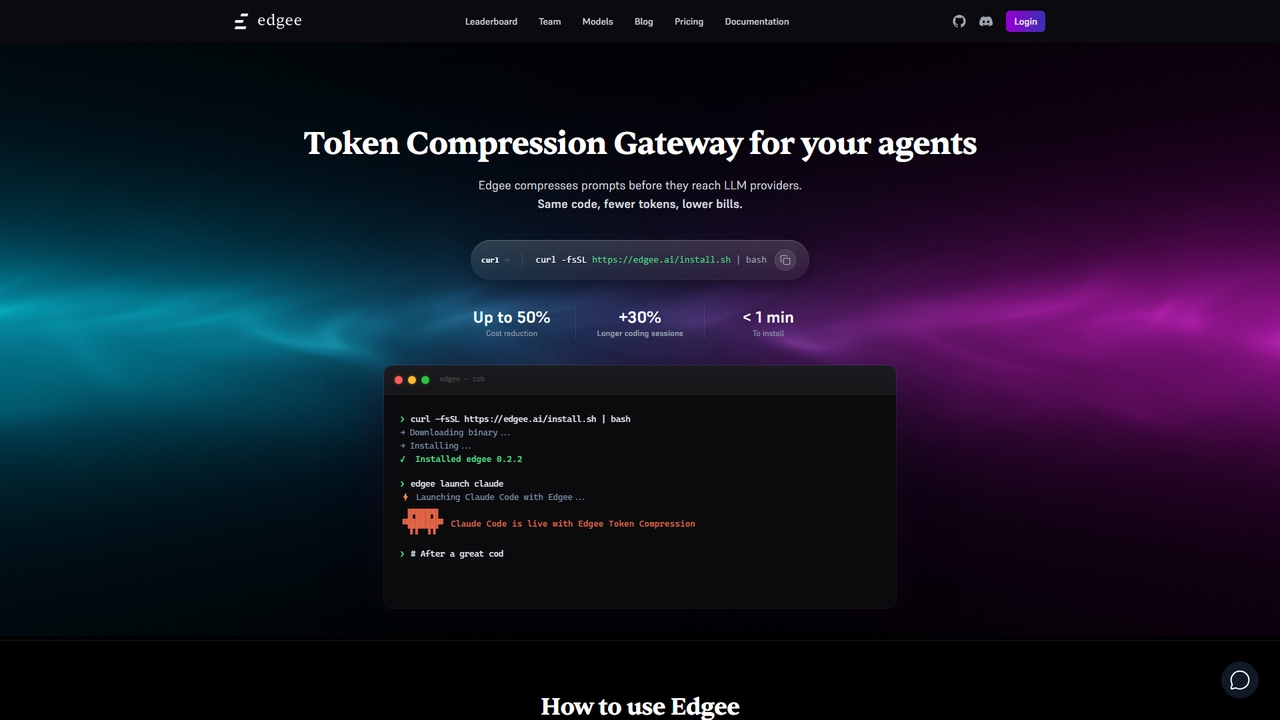
Edgee é um gateway de compressão de tokens que reduz os custos de prompts LLM em até 50%. …
Edgee é um gateway de compressão de tokens que reduz os custos de prompts LLM em até 50%. Funciona de forma transparente com agentes de codificação como Claude, Codex e Cursor.
APIPark
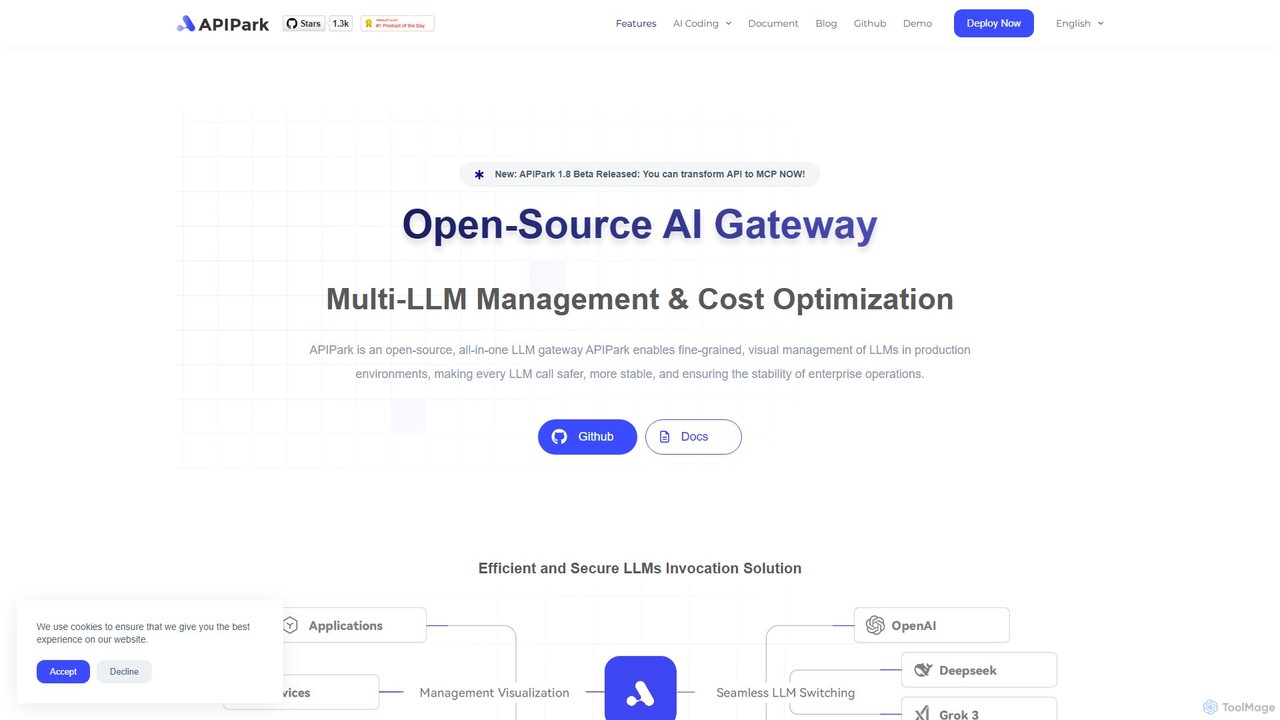
O APIPark é um gateway de IA de código aberto e portal de desenvolvedores projetado para ajudar empresas …
O APIPark é um gateway de IA de código aberto e portal de desenvolvedores projetado para ajudar empresas a gerenciar, integrar e implantar serviços de IA de forma eficiente. Ele centraliza chamadas de LLM, reduz custos e fornece ferramentas para compartilhamento, monitoramento e segurança de APIs.
Sobre Gateway LLM
Gateways LLM são ferramentas de middleware especializadas que gerenciam e otimizam o acesso a múltiplos Modelos de Linguagem Grandes (LLMs). Eles funcionam como uma camada de API unificada, posicionada entre as aplicações e vários provedores de LLM como OpenAI, Anthropic ou Google. Esse controle centralizado permite que os desenvolvedores encaminhem solicitações, gerenciem chaves de API e monitorem o uso sem ficarem presos a um único ecossistema de modelo. Como parte fundamental da Infraestrutura de IA, os Gateways LLM são essenciais para construir aplicações alimentadas por IA que sejam escaláveis, econômicas e resilientes.
Recursos Principais
- Ponto de Acesso de API Unificado: Acesse diversos LLMs de múltiplos provedores através de uma interface única e consistente.
- Roteamento Inteligente e Failover: Direcione automaticamente as solicitações para o modelo ideal com base no custo, latência ou disponibilidade, com failover transparente.
- Gerenciamento e Controle de Custos: Acompanhe o uso de tokens em tempo real, defina orçamentos e aplique limites de taxa para evitar despesas inesperadas.
- Cache de Desempenho: Armazene e reutilize respostas para consultas frequentes para reduzir a latência e minimizar chamadas de API redundantes.
- Observabilidade Centralizada: Consolide logs, métricas e rastreamentos de todas as interações com LLMs para simplificar o monitoramento e a depuração.
Casos de Uso
Os Gateways LLM são amplamente utilizados por empresas de tecnologia que constroem produtos nativos de IA, corporações que integram IA generativa em fluxos de trabalho existentes e equipes de desenvolvimento que exigem flexibilidade de modelo. Eles são particularmente valiosos em ambientes de produção para gerenciar estratégias multi-nuvem ou multi-modelo, otimizar custos operacionais e garantir a confiabilidade da aplicação.
Como Escolher
Ao selecionar um Gateway LLM, considere a gama de provedores de LLM suportados, as opções de implantação (nuvem vs. auto-hospedado), a sofisticação das regras de roteamento e cache, e suas capacidades de integração com sua pilha de observabilidade existente (por exemplo, ferramentas de log e monitoramento). Além disso, avalie os recursos de segurança e a sobrecarga de latência que o gateway introduz.
Gateway LLMCenários de aplicação
Integração de IA Multi-Modelo Empresarial
Uma equipe de desenvolvimento empresarial precisa integrar recursos de IA generativa em múltiplas aplicações internas, como um CRM e uma base de conhecimento. Em vez de construir integrações separadas para cada provedor de LLM, eles implantam um Gateway LLM. Isso fornece um ponto de acesso único e seguro para todas as aplicações. O gateway é configurado para encaminhar consultas de dados sensíveis para um modelo privado e auto-hospedado, enquanto tarefas gerais de criação de conteúdo são enviadas para o modelo comercial mais econômico. Essa abordagem simplifica a manutenção, impõe políticas de segurança centralmente e evita a dependência de um único fornecedor.
Controle de Custos para uma Aplicação SaaS
Uma empresa de SaaS oferece um recurso de resumo de conteúdo alimentado por IA para seus clientes em diferentes níveis de preço. Para gerenciar os custos operacionais, eles usam um Gateway LLM. O gateway impõe limites mensais estritos de tokens para cada cliente com base em seu plano de assinatura. Ele também fornece análises detalhadas sobre os padrões de uso, ajudando a equipe de produto a entender os custos por recurso e ajustar os preços. Além disso, eles configuram uma regra para encaminhar as solicitações de usuários do plano gratuito para um modelo mais barato e um pouco menos potente, preservando os modelos premium para clientes pagantes.
Garantindo Alta Disponibilidade com Failover de Modelo
Uma plataforma de atendimento ao cliente depende de um chatbot de IA que deve estar disponível 24/7. Para evitar tempo de inatividade causado por interrupções do provedor de LLM ou degradação de desempenho, a equipe de DevOps implementa um Gateway LLM. Eles configuram um modelo principal para todas as solicitações, mas estabelecem um modelo secundário de um provedor diferente como backup. O gateway monitora continuamente a saúde e a latência do modelo principal. Se detectar um problema, ele redireciona automática e transparentemente todo o tráfego para o modelo de backup até que o serviço principal seja restaurado, garantindo um serviço ininterrupto para os usuários finais.
Teste A/B de LLMs para Desempenho Ideal
Uma equipe de produto quer determinar se um novo modelo de código aberto, ajustado, oferece melhores resultados para seu caso de uso específico do que o LLM comercial atual. Usando um Gateway LLM, eles configuram um teste A/B. O gateway é configurado para encaminhar 10% do tráfego de usuários para o novo modelo, enquanto os outros 90% continuam a usar o existente. Através do registro centralizado do gateway, a equipe pode comparar facilmente métricas-chave como a qualidade da resposta (através do feedback do usuário), latência e custo por consulta para ambos os modelos. Essa abordagem baseada em dados permite que eles tomem uma decisão informada sem interromper a experiência do usuário.
Gerenciamento e Versionamento Centralizado de Prompts
Uma grande equipe de desenvolvedores e engenheiros de prompt trabalha em uma aplicação com dezenas de recursos orientados por IA. Gerenciar e atualizar prompts diretamente no código da aplicação é lento e propenso a erros. Eles adotam um Gateway LLM que inclui um sistema de gerenciamento de prompts. Isso permite que eles armazenem, versionem e implantem modelos de prompt a partir de um painel central. Quando um prompt precisa ser melhorado, um engenheiro de prompt pode atualizá-lo na interface do usuário do gateway, e a alteração é refletida instantaneamente na aplicação sem a necessidade de uma nova implantação de código. Isso desacopla a engenharia de prompt do ciclo de vida de desenvolvimento de software.
Implementando Cache Semântico para Desempenho
Uma plataforma de análise de notícias financeiras faz chamadas de API frequentes e semelhantes a um LLM para resumir artigos de notícias de última hora. Para reduzir a latência e cortar custos, eles usam um Gateway LLM com capacidades de cache semântico. Quando uma solicitação para resumir um novo artigo chega, o gateway primeiro verifica seu cache em busca de solicitações semanticamente semelhantes. Se um resumo suficientemente semelhante já existir, ele retorna a resposta em cache instantaneamente, evitando uma chamada cara ao LLM. Isso melhora significativamente os tempos de resposta para os usuários que visualizam notícias populares e reduz o gasto geral com API em mais de 40%.