Narrow AI
O Narrow AI é uma plataforma de otimização de LLM para desenvolvedores que automatiza a engenharia de prompts …
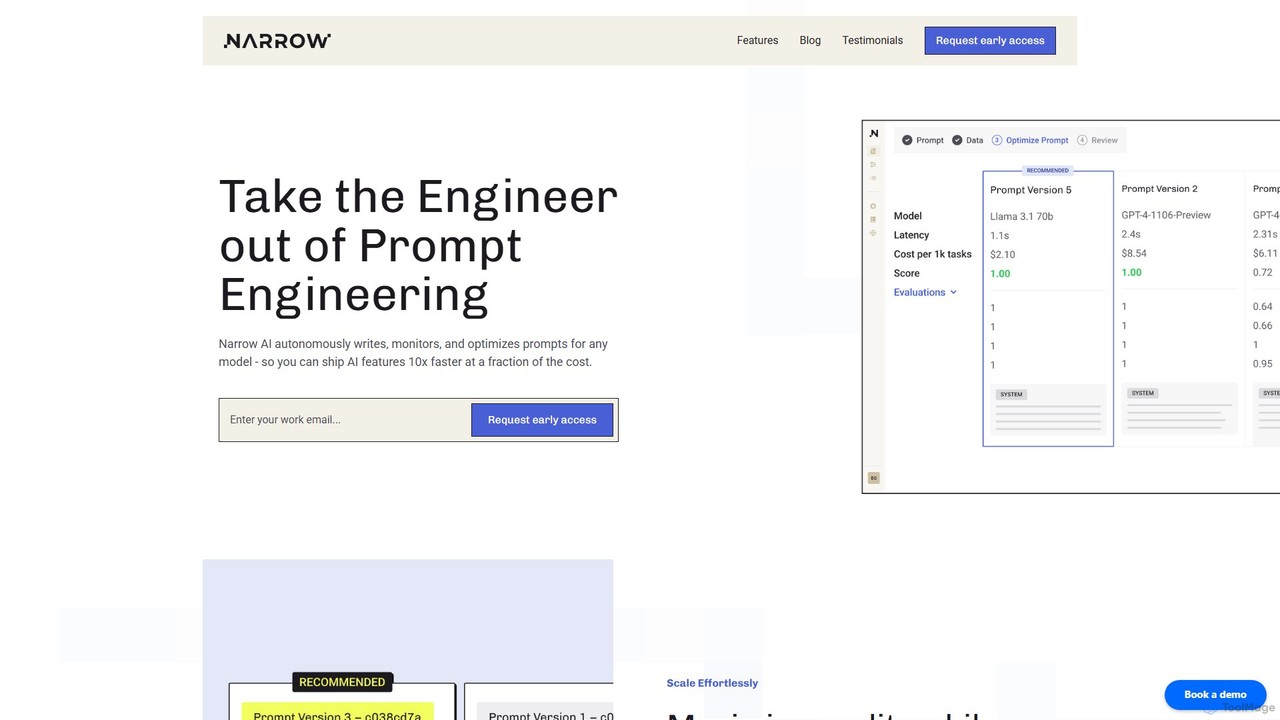
O Narrow AI é uma plataforma de otimização de LLM para desenvolvedores que automatiza a engenharia de prompts e a seleção de modelos para reduzir drasticamente os custos operacionais de IA em até 95%. Ele simplifica os fluxos de trabalho, melhora a precisão e acelera a implantação de recursos de IA de alta qualidade e baixa latência.
Sobre Otimização de Modelo
As ferramentas de Otimização de Modelo são uma categoria especializada de software de infraestrutura de IA projetada para tornar os modelos de aprendizado de máquina treinados menores, mais rápidos e mais eficientes em termos de energia. Essas ferramentas aplicam técnicas como quantização, poda (pruning) e destilação de conhecimento para reduzir a pegada computacional e de memória de um modelo sem uma perda significativa de precisão. Este processo é crítico para implantar IA complexa em hardware com recursos restritos, como telefones celulares ou dispositivos IoT, e para reduzir os custos operacionais de serviços de IA em larga escala na nuvem. Elas preenchem a lacuna entre um modelo treinado e sua aplicação prática no mundo real.
Recursos Principais
- Quantização: Reduz a precisão dos pesos do modelo (por exemplo, de float de 32 bits para inteiro de 8 bits) para diminuir o tamanho e acelerar a computação.
- Poda (Pruning): Remove sistematicamente pesos ou conexões menos importantes da rede neural para criar um modelo menor e mais esparso.
- Destilação de Conhecimento: Treina um modelo "aluno" menor e compacto para imitar o comportamento de um modelo "professor" maior e mais complexo.
- Compilação de Modelo: Converte um modelo em um formato executável específico para o hardware e altamente otimizado para dispositivos-alvo como GPUs, TPUs ou CPUs.
- Análise de Desempenho: Analisa a execução de um modelo para identificar e resolver gargalos de desempenho relacionados à velocidade, memória ou consumo de energia.
Casos de Uso
A Otimização de Modelo é essencial para engenheiros de MLOps, desenvolvedores de IA e engenheiros de sistemas embarcados. É amplamente utilizada em indústrias como eletrônicos de consumo para IA no dispositivo, automotiva para sistemas de percepção em tempo real e computação em nuvem para gerenciar os custos de inferência de grandes modelos de linguagem (LLMs) e motores de recomendação. Qualquer aplicação que exija inferência de IA eficiente se beneficia dessas ferramentas.
Como Escolher
Ao selecionar uma ferramenta de Otimização de Modelo, considere sua compatibilidade com seus frameworks de IA (por exemplo, TensorFlow, PyTorch, ONNX). Avalie seu suporte para o hardware de destino, desde GPUs de servidor até NPUs móveis. Analise a gama de técnicas de otimização que oferece e o grau de automação versus controle manual fornecido. Por fim, analise sua capacidade de gerenciar o equilíbrio entre os ganhos de desempenho e a potencial degradação da precisão.
Otimização de ModeloCenários de aplicação
Implantando Modelos de IA em Dispositivos de Borda (Edge)
Um desenvolvedor de aplicativos móveis precisa integrar um recurso de detecção de objetos em tempo real em seu aplicativo. O modelo original é muito grande e lento para rodar suavemente em um smartphone, causando consumo excessivo de bateria e uma má experiência do usuário. Usando uma ferramenta de otimização de modelo, o desenvolvedor aplica quantização de 8 bits e poda ao modelo. Isso reduz seu tamanho em 75% e triplica a velocidade de inferência, permitindo que o recurso seja executado eficientemente no dispositivo com impacto mínimo na vida útil da bateria, possibilitando uma experiência de usuário responsiva e poderosa.
Reduzindo Custos de Inferência na Nuvem para LLMs
Uma startup de tecnologia opera um serviço popular de chatbot alimentado por um grande modelo de linguagem (LLM). O alto custo dos servidores GPU para inferência está impactando sua lucratividade. A equipe de MLOps usa um conjunto de otimização de modelo para aplicar destilação de conhecimento e poda estruturada. Eles criam um modelo menor e especializado que retém 98% do desempenho do original em suas tarefas específicas. Este modelo otimizado pode lidar com 2,5 vezes mais usuários simultâneos no mesmo hardware, reduzindo diretamente sua conta de infraestrutura em nuvem em mais de 50% e melhorando a escalabilidade do serviço.
Habilitando IA em Tempo Real em Sistemas Automotivos
Um engenheiro automotivo está desenvolvendo um Sistema Avançado de Assistência ao Motorista (ADAS) que usa uma rede neural para detecção de pedestres. O sistema tem requisitos de latência rigorosos — uma decisão deve ser tomada em milissegundos. O engenheiro usa uma ferramenta de compilação de modelo para converter seu modelo PyTorch em um motor altamente otimizado para a GPU embarcada específica do carro. O processo de compilação funde camadas e otimiza o acesso à memória, reduzindo a latência de inferência em 60% e garantindo que o sistema atenda às suas metas críticas de desempenho em tempo real para segurança.
Adaptando Modelos para Microcontroladores de Baixa Potência
Um engenheiro de sistemas embarcados está projetando um dispositivo doméstico inteligente com um recurso de detecção de palavras-chave. O hardware de destino é um microcontrolador minúsculo com apenas 256KB de RAM. O modelo inicial do TensorFlow Lite é grande demais para caber. Usando um kit de ferramentas de otimização avançada, o engenheiro aplica poda de peso agressiva e quantização de inteiros de 8 bits. Isso reduz o tamanho do modelo de 1MB para apenas 180KB, permitindo que seja implantado com sucesso no microcontrolador, mantendo mais de 95% de precisão para as palavras-chave alvo, tornando o recurso inteligente viável.
Acelerando Motores de Recomendação de E-commerce
Uma equipe de MLOps em uma grande empresa de e-commerce gerencia um modelo de recomendação de aprendizado profundo. Para fornecer sugestões em tempo real, a latência de inferência deve ser extremamente baixa. Eles usam uma ferramenta de análise de desempenho para identificar que camadas específicas em seu modelo são gargalos computacionais em suas GPUs de servidor. A ferramenta de otimização sugere otimizações direcionadas, incluindo a compilação dessas camadas específicas com uma precisão diferente (precisão mista). Após aplicar essas mudanças, a latência de ponta a ponta do serviço de recomendação cai 40%, levando a carregamentos de página mais rápidos e um aumento mensurável no engajamento do usuário e nas vendas.
Otimizando Modelos de NLP para Respostas de API Mais Rápidas
Uma empresa de SaaS oferece uma API de resumo de texto. Os clientes reclamam dos tempos de resposta lentos para documentos grandes. A equipe de backend identifica o modelo de PNL como o gargalo. Em vez de treinar um novo modelo do zero, eles usam a destilação de conhecimento. Eles treinam um modelo Transformer menor e mais rápido (o 'aluno') para replicar a saída de seu modelo grande e preciso (o 'professor'). O novo modelo aluno é 4x mais rápido e é implantado em produção, reduzindo o tempo médio de resposta da API de 3 segundos para menos de 700 milissegundos, melhorando significativamente a satisfação do cliente.