People For AI
A People For AI fornece serviços de rotulagem de dados orientados por especialistas para projetos de machine learning. …
A People For AI fornece serviços de rotulagem de dados orientados por especialistas para projetos de machine learning. Eles se especializam em anotações seguras e de alta qualidade para conjuntos de dados complexos de imagem e texto. Ao usar rotuladores internos de longo prazo em vez de crowdsourcing, garantem precisão, flexibilidade e segurança de dados superiores. Seus serviços atendem a várias indústrias, incluindo veículos autônomos, microscopia, varejo e infraestrutura, ajudando empresas a acelerar seu desenvolvimento de IA com dados de treinamento confiáveis.
Sobre Dados de Treinamento
As ferramentas de Dados de Treinamento são plataformas projetadas para criar, gerenciar e adquirir conjuntos de dados de alta qualidade para treinar modelos de inteligência artificial. Como um componente fundamental da Infraestrutura de IA, essas ferramentas fornecem as informações estruturadas necessárias para que os algoritmos de aprendizado de máquina aprendam padrões e façam previsões precisas. Elas são essenciais para melhorar o desempenho do modelo, reduzir o viés e acelerar o ciclo de vida do desenvolvimento de aplicações de IA. As funcionalidades principais variam desde a anotação e rotulagem de dados até a geração de dados sintéticos e a garantia de qualidade.
Recursos Principais
- Anotação e Rotulagem de Dados: Fornece interfaces intuitivas para rotular com precisão vários tipos de dados, incluindo imagens, texto, áudio e vídeo, com técnicas como caixas delimitadoras, segmentação semântica e marcação de entidades.
- Geração de Dados Sintéticos: Cria dados artificiais, porém realistas, para aumentar ou substituir conjuntos de dados do mundo real, superando problemas de escassez de dados, privacidade e casos extremos.
- Gerenciamento de Conjuntos de Dados: Oferece uma plataforma centralizada para versionar, pesquisar и rastrear conjuntos de dados, garantindo a rastreabilidade e a colaboração entre as equipes de aprendizado de máquina.
- Fluxos de Trabalho de Garantia de Qualidade: Inclui recursos para revisão, pontuação de consenso e detecção de erros para manter altos padrões de precisão dos rótulos e consistência dos dados.
Cenários de Aplicação
Essas ferramentas são cruciais em setores que dependem de modelos de IA personalizados. Por exemplo, no setor automotivo para treinar carros autônomos com cenas de estrada anotadas, na área da saúde para desenvolver modelos de diagnóstico a partir de imagens médicas rotuladas, e no varejo para construir motores de recomendação de produtos com base em dados de comportamento do usuário.
Critérios de Seleção
Ao escolher uma ferramenta de Dados de Treinamento, considere os tipos de dados específicos com os quais você trabalha (por exemplo, vídeo, nuvens de pontos 3D). Avalie a qualidade e a eficiência das interfaces de anotação, a capacidade da plataforma de escalar com grandes conjuntos de dados e suas capacidades de integração com seu pipeline de MLOps existente. Além disso, avalie os recursos de colaboração e os mecanismos de controle de qualidade.
Dados de TreinamentoCenários de aplicação
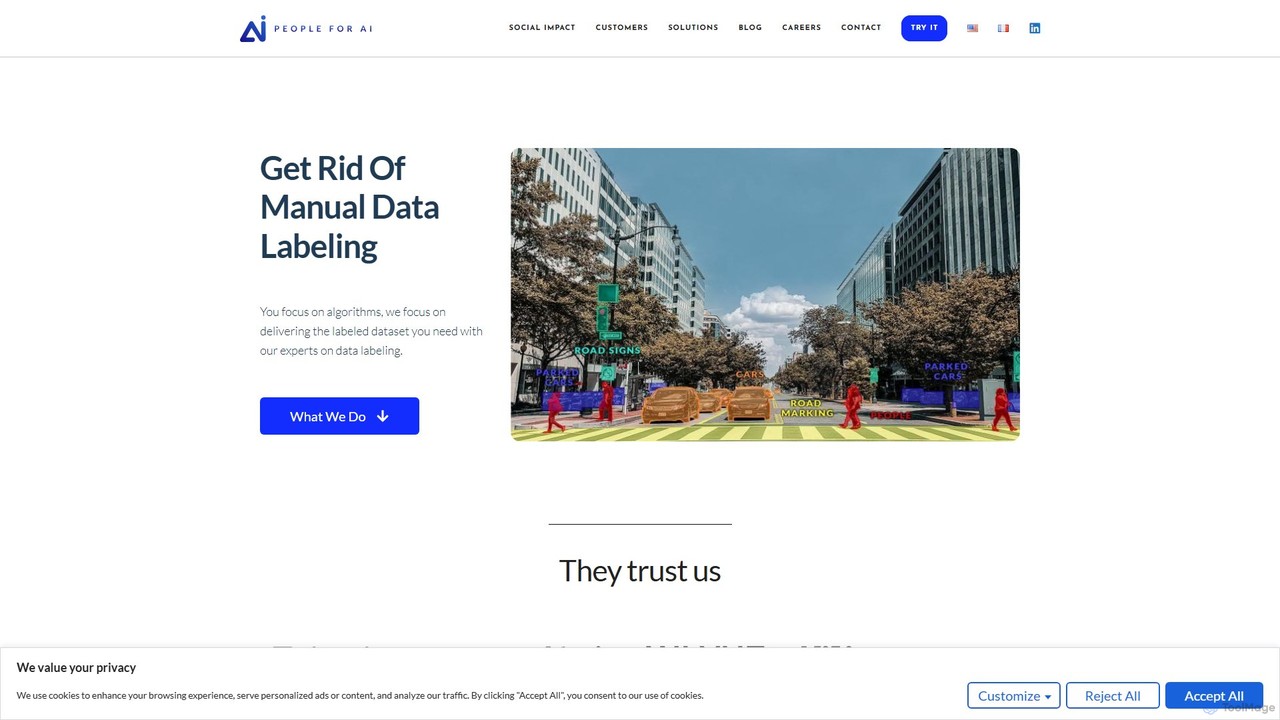
Anotação de Cenas de Estrada para Condução Autônoma
Um engenheiro de ML em uma empresa de tecnologia automotiva tem a tarefa de melhorar o modelo de percepção de um veículo autônomo. Usando uma plataforma de dados de treinamento, sua equipe anota milhares de horas de filmagens de vídeo de veículos de teste. Eles usam ferramentas de segmentação semântica para rotular cada pixel da estrada, faixas e calçadas, e caixas delimitadoras para detecção de objetos para identificar pedestres, veículos e sinais de trânsito. Este conjunto de dados meticulosamente rotulado é então usado para treinar e validar a IA, aprimorando significativamente sua capacidade de navegar com segurança em ambientes urbanos complexos.
Rotulagem de Imagens Médicas para Detecção de Doenças
Uma equipe de pesquisa médica está desenvolvendo um modelo de IA para detectar sinais precoces de câncer a partir de tomografias computadorizadas. Devido à natureza crítica da tarefa, a precisão dos dados é primordial. Eles usam uma plataforma de dados de treinamento especializada que suporta formatos de imagem DICOM e fornece ferramentas de anotação de alta precisão. Radiologistas colaboram na plataforma para contornar tumores potenciais e rotular anomalias. Os recursos de garantia de qualidade da plataforma, como revisão por pares e pontuação de consenso, garantem que o conjunto de dados final seja altamente confiável, levando a uma IA de diagnóstico mais precisa e confiável.
Geração de Dados Sintéticos para Detecção de Fraude Financeira
Uma empresa de fintech deseja construir um modelo de detecção de fraude mais robusto, mas é limitada por regulamentações de privacidade (como o GDPR) que restringem o uso de dados de transações de clientes reais. Para superar isso, sua equipe de ciência de dados usa uma ferramenta de geração de dados sintéticos. A ferramenta analisa as propriedades estatísticas de seus dados reais anonimizados e gera um novo conjunto de dados muito maior de transações artificiais que imita os padrões do mundo real sem conter nenhuma informação de identificação pessoal. Isso permite que eles treinem seu modelo em cenários de fraude diversos e complexos, melhorando as taxas de detecção enquanto permanecem totalmente em conformidade com as leis de privacidade.
Curadoria de Conjuntos de Dados para Processamento de Linguagem Natural (PLN)
Uma startup de IA conversacional está construindo um chatbot de última geração. Para treinar o modelo a entender a intenção do usuário com precisão, eles precisam de um conjunto de dados de texto anotado grande e diversificado. Usando uma plataforma de dados, eles coletam e carregam milhares de consultas de usuários. Uma equipe de anotadores usa as ferramentas de anotação de texto da plataforma para rotular cada consulta com intenções específicas (por exemplo, 'verificar_saldo', 'fazer_pagamento') e para identificar e marcar entidades (por exemplo, datas, valores, nomes). O controle de versão da plataforma permite que eles rastreiem alterações e gerenciem várias versões do conjunto de dados à medida que o modelo evolui, garantindo uma abordagem sistemática para a melhoria do modelo.
Melhorando a Pesquisa de E-commerce com a Marcação de Produtos
Um gigante do varejo online visa aprimorar seu mecanismo de busca e recomendação de produtos. Sua equipe de dados usa um serviço de dados de treinamento para rotular milhões de imagens de produtos com atributos detalhados. Os anotadores marcam os itens com categorias (por exemplo, 'vestuário feminino'), subcategorias ('vestidos'), estilos ('boêmio') e características específicas ('estampa floral', 'decote em V'). Esses dados estruturados e de alta qualidade são usados para treinar um modelo de visão computacional que pode categorizar automaticamente novos produtos e alimentar um recurso de 'busca visual' mais intuitivo, levando a uma melhor descoberta de produtos e aumento nas vendas.
Treinando um Assistente de Voz com Transcrição de Áudio
Uma empresa de tecnologia está desenvolvendo um novo assistente de voz para casa inteligente. Para garantir que ele entenda vários sotaques e comandos, eles coletam milhares de clipes de áudio de pessoas falando. Usando uma plataforma de anotação de dados, uma equipe distribuída de linguistas transcreve a fala para texto и rotula ruídos de fundo como 'campainha' ou 'latido_de_cachorro'. Eles também marcam a emoção ou a intenção do falante. Este rico conjunto de dados de áudio permite que os engenheiros treinem um modelo de reconhecimento de fala robusto que funciona bem em ambientes domésticos ruidosos do mundo real, proporcionando uma experiência de usuário superior.