
Kite
O Kite é um poderoso gravador de tela para Mac que ajuda você a criar vídeos de demonstração …
O Kite é um poderoso gravador de tela para Mac que ajuda você a criar vídeos de demonstração de produtos impressionantes e de nível profissional em minutos. Ele combina gravação de tela com recursos alimentados por IA, como zoom automático, animações 3D, narrações por IA e uma biblioteca de músicas para deixar seus vídeos tão polidos quanto um comercial da Apple.
avoalarm
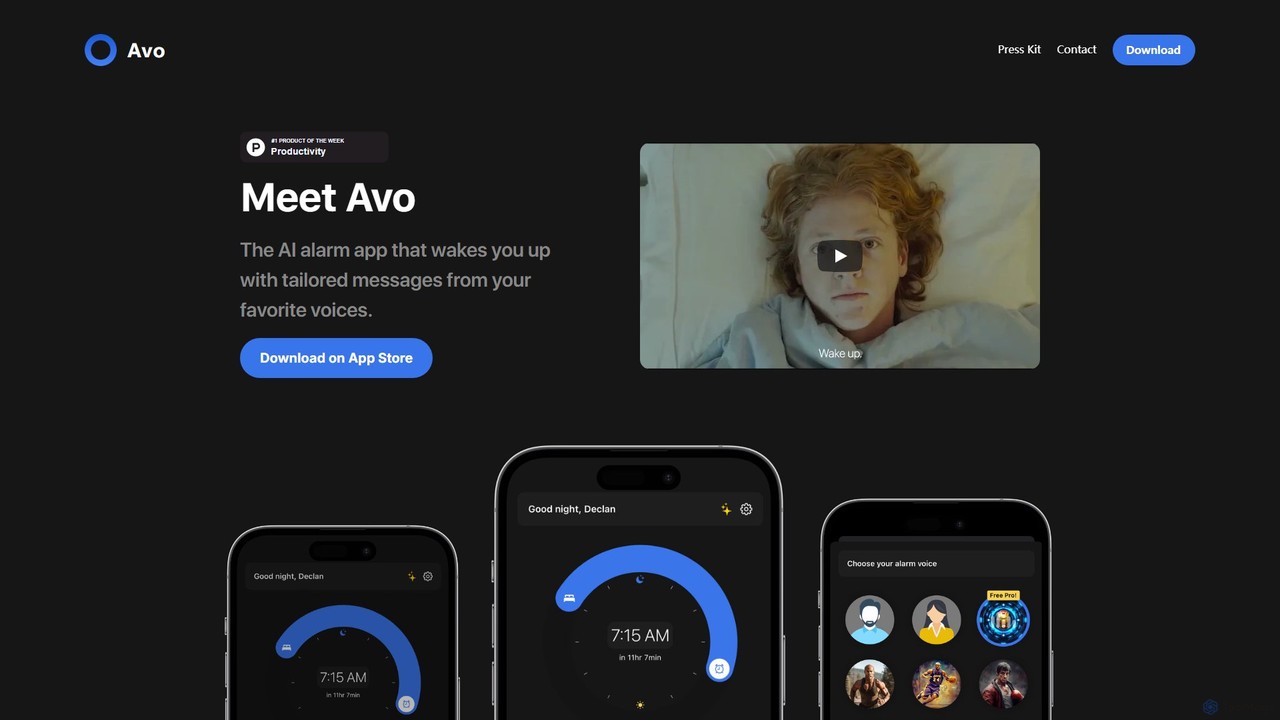
Avoalarm é um aplicativo de despertador com IA revolucionário que acorda você com mensagens de voz personalizadas de …
Avoalarm é um aplicativo de despertador com IA revolucionário que acorda você com mensagens de voz personalizadas de suas celebridades e personagens favoritos. Ele se integra com seu calendário, clima e notícias para oferecer um início de dia único, informativo e motivador.
Dreamtonics
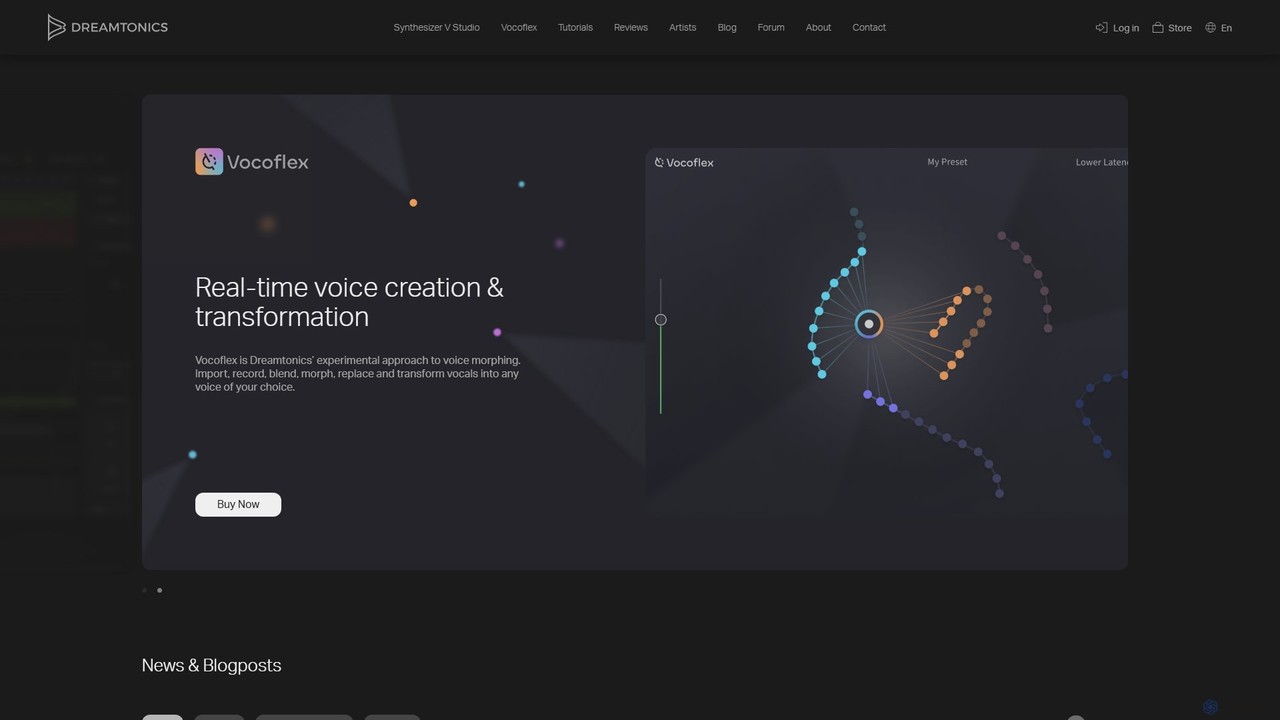
A Dreamtonics oferece ferramentas avançadas de produção vocal com IA, incluindo o Synthesizer V Studio para criar vocais …
A Dreamtonics oferece ferramentas avançadas de produção vocal com IA, incluindo o Synthesizer V Studio para criar vocais de canto hiper-realistas a partir de texto e melodias, e o Vocoflex para transformação de voz em tempo real. Estas ferramentas são projetadas para produtores musicais, compositores e artistas, proporcionando controle e realismo inigualáveis na criação de vocais sintéticos.
Sobre Síntese de Voz
As ferramentas de Síntese de Voz são uma classe de software alimentado por IA que converte texto escrito em fala audível e semelhante à humana. Essas ferramentas utilizam modelos avançados de aprendizado profundo, conhecidos como motores de Texto para Fala (TTS), para analisar texto e gerar áudio realista com entonação, ritmo e emoção naturais. Seu principal valor está na criação eficiente de narrações e conteúdo de áudio de alta qualidade, sem a necessidade de microfones, dubladores ou estúdios. Essa tecnologia permite a produção de áudio escalável para tudo, desde narração de vídeos até recursos de acessibilidade.
Recursos Principais
- Conversão de Texto para Fala (TTS): A capacidade fundamental de transformar texto em arquivos de áudio falado, geralmente em formatos como MP3 ou WAV.
- Clonagem de Voz: Permite aos usuários criar uma réplica digital de uma voz específica a partir de uma pequena amostra de áudio, possibilitando uma narração consistente e personalizada.
- Suporte a Múltiplos Idiomas e Sotaques: Oferece uma vasta biblioteca de vozes pré-construídas em inúmeros idiomas e sotaques regionais para a criação de conteúdo global.
- Controle de Prosódia e Emoção: Fornece controle refinado sobre características da fala, como tom, velocidade, volume e tom emocional (por exemplo, feliz, triste, animado).
- Suporte a SSML: Utiliza a Linguagem de Marcação de Síntese de Fala (SSML) para personalização avançada, permitindo que os desenvolvedores controlem com precisão a pronúncia, as pausas e a ênfase.
Casos de Uso
As ferramentas de Síntese de Voz são amplamente adotadas por criadores de conteúdo para produzir narrações para vídeos do YouTube, podcasts e audiolivros. Nos negócios, são usadas para criar narrações profissionais para módulos de e-learning, vídeos de treinamento corporativo e materiais de marketing. Os desenvolvedores também integram essas ferramentas via APIs para alimentar sistemas de resposta de voz interativa (IVR), assistentes em aplicativos e funções de acessibilidade, como leitores de tela para usuários com deficiência visual.
Como Escolher
Ao selecionar uma ferramenta de Síntese de Voz, primeiro avalie a qualidade e o realismo da voz — ouça amostras para garantir que atendam aos seus padrões. Considere a gama de opções de personalização, incluindo a capacidade de controlar emoções e clonar vozes. Avalie a biblioteca de idiomas e sotaques disponíveis para garantir que ela cubra seu público-alvo. Por fim, examine as capacidades de integração (acesso à API) e o modelo de preços (por exemplo, por caractere, assinatura) para encontrar uma solução que se ajuste às suas necessidades técnicas e orçamento.
Síntese de VozCenários de aplicação
Criação de narrações para conteúdo de vídeo
Criadores de conteúdo, como YouTubers e equipes de marketing, usam frequentemente a síntese de voz para produzir narrações claras e consistentes para seus vídeos. Em vez de gastar tempo e dinheiro com equipamentos de gravação e dubladores, eles podem simplesmente digitar ou colar um roteiro na ferramenta. Em seguida, podem selecionar uma voz adequada, ajustar o ritmo e o tom para combinar com o clima do vídeo e gerar um arquivo de áudio de alta qualidade em minutos. Esse processo acelera significativamente os fluxos de trabalho de produção e permite edições fáceis; se o roteiro mudar, eles podem regenerar o áudio instantaneamente sem a necessidade de uma nova sessão de gravação.
Desenvolvimento de sistemas de Resposta de Voz Interativa (URA)
Empresas e desenvolvedores usam APIs de síntese de voz para construir sistemas de URA (Unidade de Resposta Audível) mais naturais e envolventes para o suporte ao cliente. Em vez de usar prompts robóticos e pré-gravados, eles podem gerar respostas dinâmicas e semelhantes às humanas em tempo real. Por exemplo, o sistema pode chamar um cliente pelo nome ou ler informações específicas da conta com uma voz agradável e clara. Isso melhora a experiência do cliente, tornando as interações mais pessoais e menos frustrantes. Também permite atualizações fáceis nos fluxos de chamadas e scripts sem a necessidade de regravar cada prompt de áudio manualmente.
Produção de audiolivros e conteúdo de e-learning
Designers instrucionais e autores independentes aproveitam a síntese de voz para converter materiais escritos em formatos de áudio envolventes. Um autor pode transformar seu e-book em um audiolivro sem o alto custo de contratar um narrador profissional. Da mesma forma, um instrutor corporativo pode criar módulos de e-learning narrados para funcionários. Usando recursos de clonagem de voz, eles podem até usar uma versão digital de sua própria voz para um toque pessoal. Isso torna o conteúdo mais acessível e permite que as pessoas aprendam em trânsito, ouvindo durante o trajeto ou exercícios.
Criação de recursos de acessibilidade
Desenvolvedores da web e engenheiros de software usam a síntese de voz para tornar os produtos digitais mais acessíveis a usuários com deficiência visual ou dificuldades de leitura. Ao integrar um motor TTS, um site ou aplicativo pode oferecer um recurso de 'leitura em voz alta' que converte o texto na tela em fala. Isso permite que os usuários consumam artigos, notificações e instruções de interface de forma audível. Vozes sintéticas de alta qualidade são cruciais aqui, pois uma voz com som natural reduz a fadiga auditiva e torna a experiência mais agradável e eficaz para o usuário.
Prototipagem de Interfaces de Usuário de Voz (VUIs)
Designers e desenvolvedores que criam aplicativos ativados por voz, como assistentes inteligentes ou sistemas automotivos, usam a síntese de voz para prototipagem rápida. Em vez de gravar áudio provisório para cada interação possível, eles podem usar uma ferramenta de TTS para gerar respostas dinamicamente. Isso permite que eles testem rapidamente fluxos de conversação, comandos do usuário e feedback do sistema. Eles podem experimentar diferentes vozes, tons e palavras para encontrar a experiência do usuário mais eficaz antes de se comprometerem com a produção de áudio final, economizando tempo e recursos significativos na fase de design.
Geração de diálogos dinâmicos de personagens em jogos
Os desenvolvedores de jogos estão usando cada vez mais a síntese de voz para criar diálogos para personagens não-jogadores (NPCs). Isso é especialmente útil para jogos com grandes quantidades de texto, como os jogos de RPG, onde gravar cada linha com dubladores seria proibitivamente caro. Com o TTS, os desenvolvedores podem dar voz a cada NPC, fazendo com que o mundo do jogo pareça mais vivo e imersivo. Ferramentas avançadas podem até gerar diálogos com tons emocionais específicos com base em eventos do jogo, criando uma experiência mais dinâmica e responsiva para o jogador.