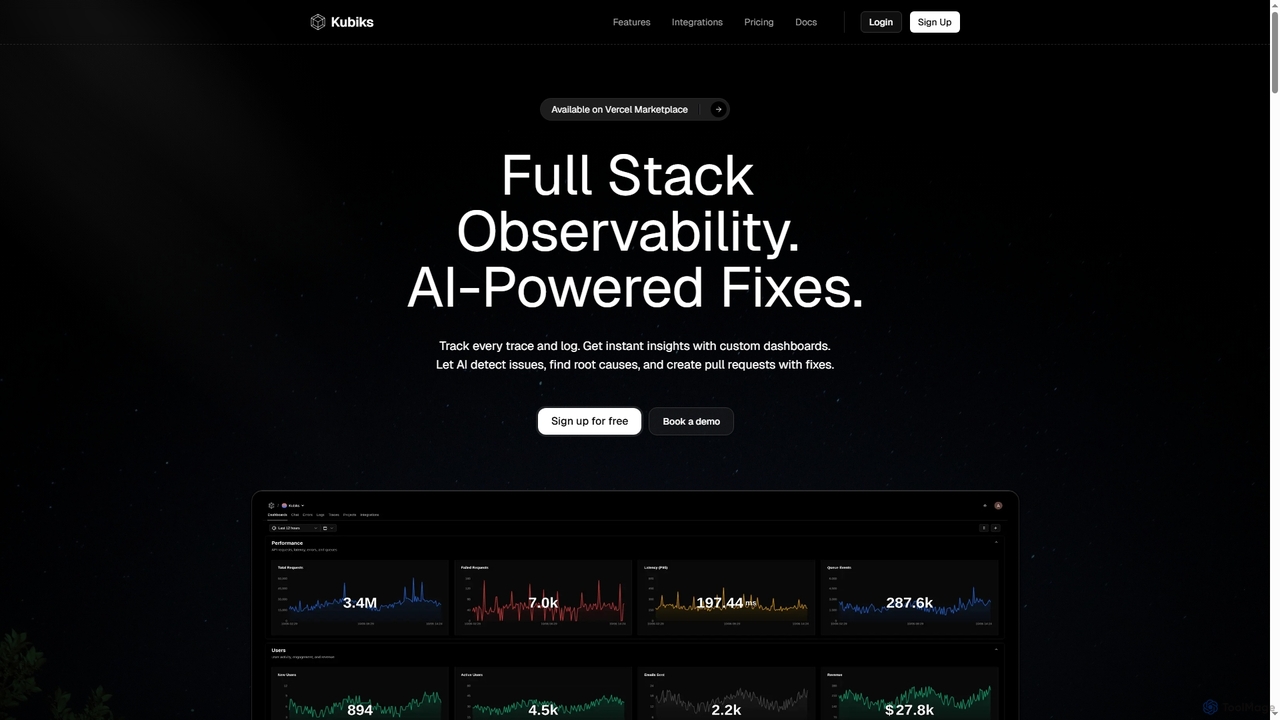
Kubiks
Kubiks é uma plataforma de observabilidade full-stack alimentada por IA que oferece rastreamento distribuído, registro e painéis personalizados. …
Kubiks é uma plataforma de observabilidade full-stack alimentada por IA que oferece rastreamento distribuído, registro e painéis personalizados. Ela detecta automaticamente problemas, identifica causas-raiz e gera pull requests com correções, ajudando equipes de engenharia a depurar mais rápido e resolver problemas proativamente.
Sobre Observabilidade
Observabilidade é um conjunto de práticas e ferramentas impulsionadas por IA e baseadas em dados que permitem às equipes compreender o estado interno de um sistema complexo examinando suas saídas externas: logs, métricas e rastreamentos. Essas ferramentas são cruciais para obter insights profundos sobre o comportamento, desempenho e saúde do software, especialmente dentro das arquiteturas distribuídas modernas comuns no desenvolvimento de software. Ao fornecer visibilidade abrangente, as soluções de observabilidade capacitam desenvolvedores e equipes de operações a identificar proativamente problemas, diagnosticar rapidamente as causas raiz e otimizar o desempenho do sistema, garantindo aplicações robustas e confiáveis.
Recursos Principais
- Rastreamento Distribuído: Rastreia solicitações em vários serviços para visualizar fluxos de transações de ponta a ponta e identificar problemas de latência.
- Agregação e Análise de Logs: Coleta, centraliza e analisa vastos volumes de dados de log para detecção de erros, auditoria de segurança e insights comportamentais.
- Monitoramento de Métricas em Tempo Real: Coleta e visualiza indicadores de desempenho (CPU, memória, rede, dados específicos da aplicação) para rastrear a saúde e as tendências do sistema.
- Detecção de Anomalias: Usa IA para identificar automaticamente padrões incomuns nos dados, alertando as equipes sobre problemas potenciais antes que afetem os usuários.
- Alertas e Gerenciamento de Incidentes: Alertas configuráveis com base em limites ou anomalias, integrados com fluxos de trabalho de resposta a incidentes.
Casos de Uso
As ferramentas de observabilidade são indispensáveis para equipes de desenvolvimento de software e operações que gerenciam aplicações complexas. Elas são usadas por SREs para manter o tempo de atividade do sistema, por desenvolvedores para depurar microsserviços e por gerentes de produto para entender os impactos na experiência do usuário. Essas ferramentas fornecem os dados necessários para tomar decisões informadas sobre a arquitetura do sistema, alocação de recursos e priorização de recursos.
Como Escolher
Ao selecionar uma ferramenta de observabilidade, considere suas capacidades de coleta de dados (logs, métricas, rastreamentos), integração com sua pilha de tecnologia existente (provedores de nuvem, linguagens de programação, bancos de dados), escalabilidade para lidar com volumes crescentes de dados e a qualidade de seus recursos de visualização e alerta. Avalie o modelo de custos, a facilidade de uso e o suporte da comunidade, garantindo que ele se alinhe com a experiência técnica e o orçamento de sua equipe.
ObservabilidadeCenários de aplicação
Diagnóstico de Gargalos de Desempenho em Microsserviços
Para engenheiros de software e SREs, as ferramentas de observabilidade são vitais para identificar problemas de desempenho em arquiteturas de microsserviços complexas. Ao usar o rastreamento distribuído, as equipes podem visualizar todo o fluxo de solicitações entre os serviços, identificar qual serviço específico ou chamada de banco de dados está causando atrasos e aprofundar rapidamente em logs e métricas relevantes para entender a causa raiz. Isso reduz drasticamente o tempo médio de resolução (MTTR) para incidentes críticos de desempenho.
Detecção Proativa de Erros e Alertas
As equipes de DevOps e operações utilizam plataformas de observabilidade para passar de uma gestão de incidentes reativa para proativa. A detecção de anomalias impulsionada por IA monitora continuamente as métricas e logs do sistema em busca de padrões incomuns, como picos repentinos nas taxas de erro ou consumo inesperado de recursos. Alertas automatizados são acionados quando anomalias são detectadas, permitindo que as equipes resolvam problemas potenciais antes que eles se transformem em interrupções ou impactem significativamente os usuários finais.
Compreender a Jornada e Experiência do Usuário
Gerentes de produto e designers de UX podem utilizar dados de observabilidade para obter insights sobre como os usuários interagem com suas aplicações. Ao correlacionar rastreamentos distribuídos com métricas de desempenho de front-end e logs específicos do usuário, eles podem reconstruir jornadas do usuário, identificar pontos de atrito e entender o impacto do desempenho de back-end na experiência do usuário. Esses dados informam melhorias de produto e priorização de recursos, levando a uma experiência do usuário mais satisfatória.
Planejamento de Capacidade e Otimização de Recursos
Arquitetos de infraestrutura e nuvem dependem de ferramentas de observabilidade para um planejamento de capacidade e otimização de recursos eficazes. Ao analisar tendências históricas no uso da CPU, consumo de memória, tráfego de rede e métricas específicas da aplicação, as equipes podem prever com precisão as necessidades futuras de recursos. Isso evita o superprovisionamento (economizando custos) ou o subprovisionamento (evitando a degradação do desempenho), garantindo uma gestão de infraestrutura eficiente e escalável.
Investigação e Forense de Incidentes de Segurança
As equipes de operações de segurança (SecOps) usam plataformas de observabilidade para investigação aprofundada de incidentes de segurança. As capacidades centralizadas de agregação e análise de logs permitem que os analistas de segurança pesquisem rapidamente grandes volumes de logs de sistema e aplicativos em busca de atividades suspeitas, tentativas de acesso não autorizado ou violações de dados. A correlação desses logs com rastreamentos de rede e métricas do sistema fornece uma linha do tempo e contexto abrangentes para análise forense, auxiliando na contenção e remediação rápidas.
Otimização do Desempenho do Pipeline CI/CD
As equipes de engenharia de desenvolvimento e lançamento aplicam os princípios de observabilidade aos seus pipelines de CI/CD. Ao coletar métricas e logs de servidores de build, ambientes de teste e processos de implantação, elas podem identificar gargalos, testes lentos ou implantações com falha. Essa visibilidade ajuda a otimizar as etapas do pipeline, reduzir os tempos de build e garantir uma entrega de software mais rápida e confiável, contribuindo diretamente para a produtividade do desenvolvedor e um tempo de lançamento no mercado mais rápido.