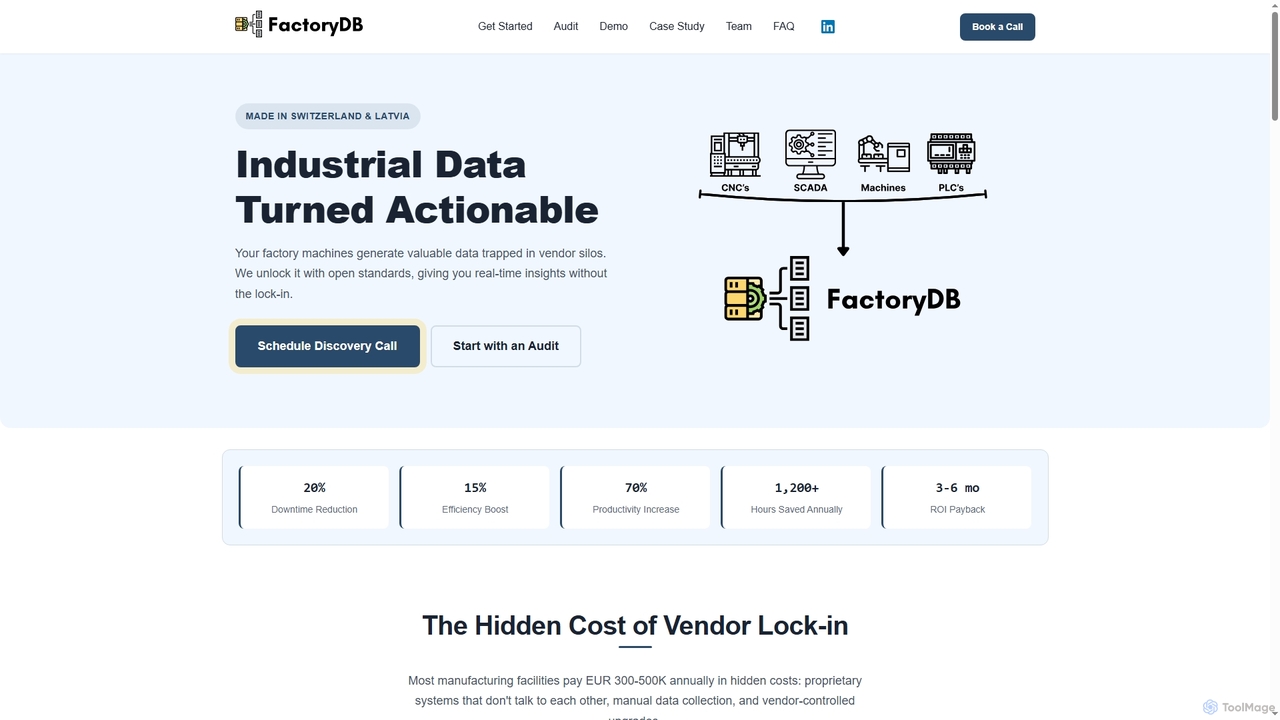
FactoryDB
O FactoryDB é uma plataforma de infraestrutura de dados industriais projetada para eliminar a dependência de fornecedores (vendor …
O FactoryDB é uma plataforma de infraestrutura de dados industriais projetada para eliminar a dependência de fornecedores (vendor lock-in) para fabricantes. Usando padrões abertos como MQTT, ele unifica dados de PLCs, SCADA e sistemas MES em uma única camada de dados neutra. Isso permite análises em tempo real, manutenção preditiva e ganhos significativos de eficiência, especialmente para indústrias regulamentadas como farmacêutica, alimentos e bebidas, e energia.
Sobre Infraestrutura de Dados
As ferramentas de Infraestrutura de Dados são soluções especializadas impulsionadas por IA que fornecem os sistemas fundamentais para coletar, armazenar, processar e gerenciar os vastos conjuntos de dados essenciais para as operações de inteligência artificial e aprendizado de máquina. Essas ferramentas garantem a disponibilidade, integridade e desempenho dos dados, permitindo um treinamento, implantação e escalonamento eficientes de modelos de IA dentro do panorama de TI mais amplo. Elas são críticas para lidar com as demandas únicas das cargas de trabalho de IA, desde a ingestão de dados em tempo real até o processamento analítico complexo.
Recursos Principais
- Armazenamento de Dados Escalável: Oferece soluções de armazenamento distribuído de alto desempenho otimizadas para grandes conjuntos de dados de IA, suportando vários tipos de dados e padrões de acesso.
- Pipelines de Dados Automatizados: Facilita a criação e o gerenciamento de pipelines automatizados de ingestão, transformação e carregamento (ETL) de dados para preparar os dados para o treinamento de modelos de IA.
- Processamento de Dados em Tempo Real: Permite o processamento e a análise de baixa latência de dados de streaming, cruciais para aplicações de IA em tempo real, como detecção de fraudes ou sistemas de recomendação.
- Governança e Segurança de Dados: Implementa medidas de segurança robustas, controles de acesso e estruturas de conformidade para proteger dados sensíveis de treinamento de IA e saídas de modelos.
- Orquestração de Recursos: Gerencia e otimiza recursos computacionais (GPUs, CPUs) e armazenamento em ambientes distribuídos para uma execução eficiente de cargas de trabalho de IA.
Cenários de Aplicação
A Infraestrutura de Dados é indispensável para organizações que constroem e implantam IA. Por exemplo, uma grande empresa de tecnologia que desenvolve um novo modelo de linguagem requer uma infraestrutura robusta para armazenar petabytes de dados de texto e gerenciar trabalhos de treinamento distribuídos em milhares de GPUs. Da mesma forma, as instituições financeiras a utilizam para o processamento em tempo real de dados de transações para alimentar sistemas de detecção de fraudes impulsionados por IA, garantindo análise e resposta imediatas. As plataformas de comércio eletrônico a aproveitam para coletar e processar dados de interação do cliente, alimentando motores de recomendação que personalizam as experiências do usuário.
Como Escolher
A seleção das ferramentas de Infraestrutura de Dados certas envolve a avaliação de vários fatores-chave. Considere a escalabilidade necessária para lidar com o crescimento futuro dos dados e a crescente complexidade dos modelos de IA. Avalie as necessidades de desempenho, incluindo taxas de ingestão de dados, velocidade de processamento e latência de consulta, especialmente para aplicações em tempo real. Avalie as capacidades de integração com plataformas AI/ML existentes, fontes de dados e ambientes de nuvem. Finalmente, examine os recursos de segurança, as certificações de conformidade e o custo total de propriedade, incluindo despesas operacionais e manutenção.
Infraestrutura de DadosCenários de aplicação
Construção de Pipelines Escaláveis para Treinamento de Modelos de IA
Engenheiros de aprendizado de máquina e cientistas de dados utilizam uma infraestrutura de dados robusta para construir pipelines eficientes e escaláveis para o treinamento de modelos de IA. Isso envolve a automação da ingestão de vastos conjuntos de dados de várias fontes, a realização da limpeza e transformação de dados necessárias e a entrega de dados preparados para plataformas de ML. Uma infraestrutura bem projetada garante qualidade e disponibilidade de dados consistentes, reduzindo significativamente o tempo e o esforço necessários para o desenvolvimento e implantação iterativos de modelos, levando a uma inovação mais rápida e melhor desempenho do modelo.
Construção de Pipelines de Treinamento de IA/ML Escaláveis
Cientistas de dados e engenheiros de aprendizado de máquina aproveitam a infraestrutura de dados para estabelecer pipelines robustos e escaláveis para o treinamento de modelos de IA. Isso envolve a ingestão eficiente de vastos conjuntos de dados de várias fontes, a realização de transformações complexas de dados (ETL) e o armazenamento dos dados preparados em data lakes ou data warehouses otimizados. A infraestrutura garante a qualidade, linhagem e acessibilidade dos dados, permitindo uma iteração rápida do treinamento de modelos, controle de versão e integração perfeita com plataformas de IA, acelerando, em última análise, o desenvolvimento e a implantação de soluções de IA de alto desempenho.
Construção de Pipelines de Dados Escaláveis para Treinamento de IA
Cientistas de dados e engenheiros de ML utilizam ferramentas de infraestrutura de dados para construir pipelines automatizados que ingerem dados brutos de várias fontes, limpam, transformam e armazenam em formatos otimizados. Isso garante um fornecimento contínuo de dados de alta qualidade e pré-processados, essenciais para treinar e ajustar modelos complexos de IA, reduzindo significativamente o tempo de preparação manual de dados e melhorando a precisão do modelo.
Construir Pipelines de Dados Escaláveis para Treinamento de IA
Cientistas de dados e engenheiros de ML exigem pipelines de dados robustos para alimentar dados limpos e pré-processados em modelos de IA. As ferramentas de infraestrutura de dados permitem a ingestão, transformação e carregamento (ETL) automatizados de conjuntos de dados massivos de várias fontes em data lakes ou data warehouses. Isso garante um fornecimento contínuo de dados de alta qualidade, reduzindo significativamente o tempo de preparação manual de dados e acelerando o processo iterativo de treinamento e refinamento de modelos, levando a sistemas de IA mais precisos e eficientes.
Construção de Data Lakes Escaláveis para Treinamento de IA
Cientistas de dados e engenheiros de aprendizado de máquina exigem um data lake robusto para armazenar conjuntos de dados diversos e brutos (imagens, texto, áudio, dados de sensores) em escala para treinar modelos de IA complexos. As ferramentas de infraestrutura de dados facilitam a criação de tais lagos, fornecendo armazenamento flexível, gerenciamento de metadados e mecanismos eficientes de recuperação de dados. Isso permite o desenvolvimento e a experimentação iterativos de modelos sem gargalos de dados, garantindo entrada de alta qualidade para algoritmos de aprendizado profundo e reduzindo os tempos de treinamento.
Análise em Tempo Real para Business Intelligence
Analistas de negócios e engenheiros de dados aproveitam a infraestrutura de dados em tempo real para obter insights imediatos sobre o desempenho operacional e o comportamento do cliente. Ao processar dados de streaming de aplicativos, dispositivos IoT ou sistemas transacionais, as organizações podem monitorar métricas chave à medida que elas acontecem. Essa capacidade permite a tomada de decisões proativas, como identificar tendências de mercado emergentes, detectar anomalias em transações financeiras ou personalizar experiências do cliente instantaneamente, proporcionando uma vantagem competitiva através de inteligência oportuna.
Alimentando Painéis de Business Intelligence em Tempo Real
Analistas de negócios e gerentes de operações dependem da infraestrutura de dados para alimentar painéis de business intelligence (BI) em tempo real. A infraestrutura processa dados de streaming de vendas, interações com clientes e sistemas operacionais com baixa latência, garantindo que as ferramentas de BI exibam as métricas mais atuais. Isso permite insights imediatos sobre os principais indicadores de desempenho (KPIs), permitindo que os tomadores de decisão reajam rapidamente às mudanças do mercado, identifiquem tendências emergentes e otimizem as estratégias operacionais sem demora, aumentando significativamente a agilidade e a capacidade de resposta dos negócios.
Habilitando Análises em Tempo Real para Operações de Negócios
Analistas de negócios e gerentes de operações aproveitam soluções de streaming e armazenamento de dados dentro da infraestrutura de dados para processar e analisar fluxos de dados de entrada instantaneamente. Isso permite o monitoramento em tempo real de indicadores-chave de desempenho, detecção imediata de fraudes e gerenciamento dinâmico de estoque, fornecendo insights críticos para a tomada de decisões ágeis e resposta rápida às mudanças do mercado.
Análise em Tempo Real e Inteligência de Negócios
Analistas de negócios e tomadores de decisão precisam de insights imediatos de dados operacionais para responder rapidamente às mudanças do mercado. A infraestrutura de dados fornece a espinha dorsal para o streaming e processamento de dados em tempo real, permitindo a agregação e análise instantâneas de dados de entrada de vendas, interações com clientes ou sensores IoT. Essa capacidade suporta painéis dinâmicos, detecção de fraudes e experiências personalizadas do cliente, permitindo estratégias de negócios proativas e vantagens competitivas.
Ingestão de Dados em Tempo Real para Análises Impulsionadas por IA
Para aplicações como detecção de fraudes, recomendações personalizadas ou monitoramento de IoT, os modelos de IA precisam de acesso a fluxos de dados frescos e em tempo real. As ferramentas de infraestrutura de dados fornecem pipelines de ingestão de alto rendimento que capturam, processam e entregam dados de streaming com latência mínima. Isso permite que os sistemas de IA tomem decisões imediatas baseadas em dados, respondendo a eventos à medida que acontecem e aprimorando significativamente a capacidade de resposta e a precisão das aplicações de IA em tempo real.
Garantir a Governança e Conformidade de Dados
Oficiais de conformidade e administradores de dados dependem da infraestrutura de dados para estabelecer e aplicar políticas abrangentes de governança de dados, atendendo a requisitos regulatórios como GDPR ou HIPAA. Essas ferramentas fornecem mecanismos para rastreamento de linhagem de dados, controle de acesso, mascaramento de dados e auditoria, garantindo a integridade e segurança dos dados. Ao centralizar os esforços de governança, as organizações podem minimizar os riscos de conformidade, manter a qualidade dos dados e construir confiança com clientes e partes interessadas, evitando multas caras e danos à reputação.
Alcançando uma Visão 360 do Cliente para Personalização
Equipes de marketing e atendimento ao cliente utilizam a infraestrutura de dados para consolidar dados de clientes díspares de plataformas de CRM, vendas, mídias sociais e análise da web em um perfil de cliente unificado. Essa visão abrangente de 360 graus permite que as empresas entendam o comportamento, as preferências e a jornada do cliente em todos os pontos de contato. Ao aproveitar esses dados integrados, as empresas podem oferecer campanhas de marketing altamente personalizadas, recomendações de produtos sob medida e suporte proativo ao cliente, melhorando significativamente a satisfação do cliente e impulsionando maiores taxas de conversão e lealdade.
Garantindo a Governança e Conformidade de Dados
Oficiais de conformidade e administradores de dados implementam componentes de infraestrutura de dados como catálogos de dados, gerenciamento de metadados e controles de acesso para impor políticas de governança de dados. Isso garante a qualidade dos dados, o rastreamento de linhagem e a adesão a regulamentações como GDPR ou HIPAA, mitigando riscos associados a violações de dados e não conformidade, enquanto mantém a integridade dos dados em toda a empresa.
Armazenamento e Governança Seguros de Dados para Conformidade
Organizações que lidam com dados sensíveis de clientes ou proprietários, particularmente em setores regulamentados como finanças ou saúde, devem garantir segurança e conformidade de dados rigorosas. As soluções de infraestrutura de dados oferecem armazenamento criptografado, controles de acesso granulares, mascaramento de dados e trilhas de auditoria para atender a regulamentações como GDPR ou HIPAA. Isso protege contra violações de dados, mantém a confiança do cliente e evita multas pesadas, garantindo práticas de manuseio de dados legais e éticas.
Orquestração de Cargas de Trabalho de Treinamento de Modelos de IA Distribuídos
O treinamento de modelos de IA em larga escala, especialmente redes neurais profundas, geralmente requer recursos computacionais significativos distribuídos em várias GPUs ou clusters. As soluções de infraestrutura de dados incluem capacidades de orquestração que gerenciam essas cargas de trabalho distribuídas, alocando recursos de forma eficiente, monitorando o progresso do trabalho e lidando com falhas. Isso garante que as execuções de treinamento complexas sejam concluídas de forma confiável e otimizada, maximizando a utilização de recursos e acelerando o ciclo de desenvolvimento para IA avançada.
Consolidação de Dados de Fontes Dispares
Arquitetos de dados e gerentes de TI usam a infraestrutura de dados para integrar e consolidar informações de vários sistemas isolados, como CRM, ERP e plataformas de marketing, em um repositório de dados unificado. Este processo envolve o design de fluxos de trabalho ETL/ELT eficientes para extrair, transformar e carregar dados, criando uma única fonte de verdade. Uma visão consolidada dos dados facilita relatórios abrangentes, análises multifuncionais e apoia o desenvolvimento de aplicações de IA holísticas que aproveitam todos os dados organizacionais disponíveis.
Garantindo Conformidade Regulatória e Auditoria de Dados
Oficiais de conformidade e equipes jurídicas em setores regulamentados, como finanças e saúde, dependem de uma infraestrutura de dados robusta para atender a requisitos regulatórios rigorosos como GDPR, HIPAA ou CCPA. A infraestrutura fornece armazenamento seguro de dados com criptografia, rastreamento detalhado de linhagem de dados e recursos abrangentes de auditoria. Isso garante que todas as operações de dados sejam transparentes, rastreáveis e em conformidade, minimizando riscos legais e permitindo respostas rápidas a solicitações de auditoria, demonstrando manuseio adequado de dados, controles de acesso e políticas de retenção.
Consolidando Fontes de Dados Dispares em um Lago Unificado
Arquitetos corporativos e engenheiros de dados usam soluções de data lake para centralizar grandes quantidades de dados estruturados e não estruturados de vários sistemas departamentais, dispositivos IoT e feeds externos. Este repositório unificado facilita a exploração abrangente de dados e análises avançadas, quebrando silos de dados e fornecendo uma visão holística para planejamento estratégico e inovação.
Migrar Dados Legados para Plataformas Nativas da Nuvem
Administradores de TI e arquitetos de nuvem frequentemente enfrentam o desafio de mover grandes quantidades de dados históricos de sistemas locais para ambientes de nuvem modernos. As ferramentas de infraestrutura de dados facilitam essa migração complexa, fornecendo conectores robustos, mecanismos de validação de dados e capacidades de transferência escaláveis. Essa transição permite que as organizações aproveitem a elasticidade da nuvem, reduzam os custos operacionais e desbloqueiem novas possibilidades analíticas com serviços de IA baseados em nuvem, modernizando seu panorama de dados.
Garantindo a Governança e Segurança de Dados para Conjuntos de Dados de IA
Os modelos de IA são tão bons quanto os dados com os quais são treinados, e esses dados frequentemente contêm informações sensíveis. As ferramentas de infraestrutura de dados fornecem recursos críticos para a governança de dados, incluindo controle de acesso, criptografia, mascaramento de dados e trilhas de auditoria. Isso ajuda as organizações a cumprir regulamentações como GDPR ou HIPAA, proteger dados proprietários e manter a integridade e a privacidade dos conjuntos de dados usados para o desenvolvimento de IA, construindo confiança e mitigando riscos.
Otimização do Armazenamento de Dados para Custo e Desempenho
Arquitetos de nuvem e equipes de operações de dados empregam soluções de infraestrutura de dados para otimizar estratégias de armazenamento, equilibrando a eficiência de custos com os requisitos de desempenho. Isso inclui a implementação de armazenamento em camadas, compressão de dados e políticas inteligentes de gerenciamento do ciclo de vida dos dados para mover dados menos acessados para camadas de armazenamento mais baratas, mantendo dados críticos prontamente disponíveis. A otimização eficaz do armazenamento reduz os gastos com a nuvem, melhora as velocidades de recuperação de dados e garante que os recursos sejam alocados eficientemente com base no valor dos dados e nos padrões de acesso.
Gerenciamento de Dados IoT de Alto Volume para Manutenção Preditiva
Engenheiros industriais e gerentes de operações na fabricação ou logística aproveitam a infraestrutura de dados para ingerir e processar volumes massivos de dados gerados por sensores IoT em máquinas, veículos ou infraestrutura. Esse fluxo de dados em tempo real, incluindo temperatura, vibração e métricas de desempenho, é analisado para identificar anomalias e prever possíveis falhas de equipamento. Ao implementar estratégias de manutenção preditiva com base nesses insights, as empresas podem minimizar o tempo de inatividade, reduzir os custos de reparo e estender a vida útil de ativos críticos, otimizando a eficiência operacional e prevenindo interrupções caras.
Otimizando o Armazenamento de Dados para Custo e Desempenho
Administradores de TI e arquitetos de nuvem implantam soluções de armazenamento em camadas e arquivamento de dados dentro da infraestrutura de dados para gerenciar o ciclo de vida dos dados de forma eficiente. Ao categorizar os dados com base na frequência de acesso e políticas de retenção, eles podem mover dados menos acessados para camadas de armazenamento mais econômicas, equilibrando os requisitos de desempenho com as restrições orçamentárias e garantindo a disponibilidade de dados a longo prazo.
Suportar a Implantação de Modelos de Aprendizado de Máquina em Larga Escala
Após o treinamento, a implantação de modelos de aprendizado de máquina em produção requer uma camada de serviço de dados estável e de alto desempenho. A infraestrutura de dados garante que os modelos possam acessar os recursos necessários e os dados de inferência com baixa latência e alto throughput. Isso envolve armazenamentos de dados otimizados, mecanismos de cache e integração com plataformas de serviço de modelos. Uma infraestrutura bem projetada garante que os aplicativos de IA implantados forneçam previsões e recomendações consistentes e em tempo real aos usuários finais.
Automatizando Pipelines ETL para Engenharia de Recursos de Aprendizado de Máquina
Antes que os dados possam ser usados para aprendizado de máquina, eles frequentemente precisam de limpeza, transformação e engenharia de recursos extensivas. As ferramentas de infraestrutura de dados automatizam esses processos de Extração, Transformação e Carregamento (ETL), permitindo que engenheiros de dados construam pipelines repetíveis que preparam os dados para o consumo do modelo. Isso reduz o esforço manual, garante a consistência dos dados e acelera o tempo de obtenção de insights para projetos de aprendizado de máquina, fornecendo recursos bem estruturados para um desempenho ideal do modelo.
Apoio a Projetos de Migração de Dados em Grande Escala
Gerentes de projetos de TI e especialistas em migração utilizam uma infraestrutura de dados robusta para planejar e executar projetos de migração de dados em grande escala, como mover dados de sistemas on-premise para a nuvem ou consolidar múltiplos bancos de dados legados. Essas ferramentas fornecem capacidades para perfilagem de dados, limpeza, mapeamento e transferência segura, minimizando o tempo de inatividade e garantindo a integridade dos dados durante todo o processo de migração. Uma infraestrutura de migração de dados bem gerenciada mitiga riscos, acelera a conclusão do projeto e garante uma transição suave para novos ambientes de dados.
Estabelecendo um Data Lake Escalável para Análise de Big Data
Arquitetos corporativos e engenheiros de dados projetam e implementam infraestrutura de dados para criar data lakes escaláveis capazes de armazenar diversos tipos de dados, incluindo dados brutos, semiestruturados e não estruturados, em escalas massivas. Isso serve como um repositório central para análise de big data, permitindo que cientistas de dados realizem análises exploratórias, construam novos modelos de dados e preparem conjuntos de dados para futuros projetos de IA sem as restrições dos data warehouses tradicionais. A infraestrutura do data lake suporta abordagens flexíveis de esquema na leitura, permitindo agilidade na exploração de dados e promovendo a inovação em toda a organização.
Suportando Ambientes de Dados Híbridos e Multi-Cloud
Arquitetos de nuvem e equipes de DevOps utilizam ferramentas de infraestrutura de dados que oferecem integração e gerenciamento contínuos entre plataformas locais e múltiplas plataformas de nuvem. Isso permite que as organizações aproveitem os melhores recursos de diferentes ambientes, garantam a portabilidade dos dados e mantenham a continuidade dos negócios, proporcionando flexibilidade e resiliência para estratégias de dados em evolução sem bloqueio de fornecedor.
Gerenciamento de Data Lakes para Dados Não Estruturados
Engenheiros e pesquisadores de dados frequentemente trabalham com diversos tipos de dados não estruturados, como imagens, vídeos, áudio e texto, que são críticos para aplicações avançadas de IA como visão computacional e processamento de linguagem natural. A infraestrutura de dados fornece soluções de data lake que podem armazenar dados brutos, com esquema na leitura, em escala. Isso permite uma exploração e experimentação flexíveis com vários formatos de dados, permitindo o desenvolvimento de modelos de IA inovadores que podem derivar insights de informações anteriormente inacessíveis.
Monitoramento e Gerenciamento do Desempenho de Aplicações de IA
Uma vez que os modelos de IA são implantados, seu desempenho e a infraestrutura de dados subjacente precisam de monitoramento contínuo. As ferramentas desta categoria oferecem recursos abrangentes de monitoramento, registro e alerta para pipelines de dados, sistemas de armazenamento e recursos computacionais. Isso permite que as equipes de operações identifiquem e resolvam rapidamente gargalos, garantam a saúde do fluxo de dados e mantenham a confiabilidade e a eficiência das aplicações impulsionadas por IA em ambientes de produção, prevenindo interrupções de serviço.