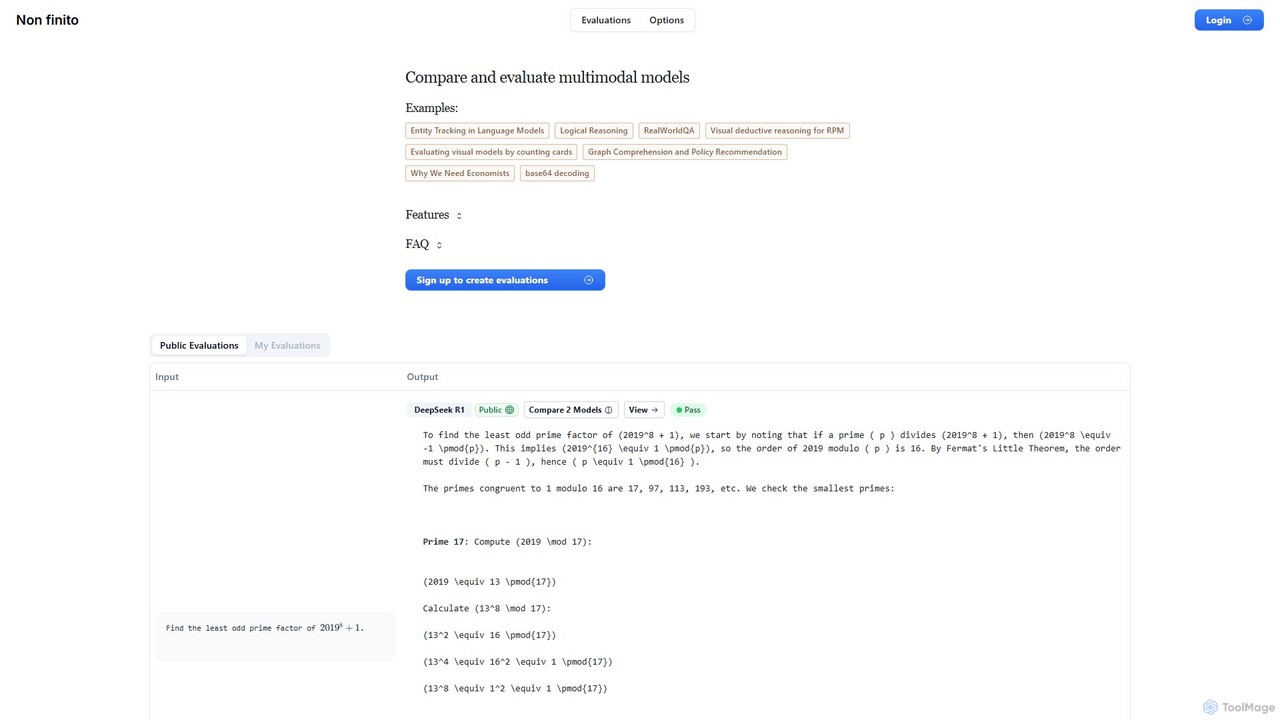
nonfinito
nonfinito é uma plataforma abrangente para avaliar e comparar modelos de IA multimodais. Permite que desenvolvedores, pesquisadores e …
nonfinito é uma plataforma abrangente para avaliar e comparar modelos de IA multimodais. Permite que desenvolvedores, pesquisadores e empresas testem vários LLMs lado a lado em prompts personalizados, avaliem seu desempenho com classificações de aprovação/reprovação e analisem saídas brutas. Crie benchmarks públicos ou privados para encontrar o melhor modelo para qualquer tarefa.
Sobre Benchmarking
As ferramentas de Benchmarking de IA são plataformas especializadas para avaliar e comparar sistematicamente o desempenho de modelos e sistemas de inteligência artificial. Elas operam executando testes padronizados ou prompts personalizados em diferentes modelos para medir métricas-chave como precisão, velocidade, custo e qualidade do resultado. Isso permite que desenvolvedores, pesquisadores e empresas tomem decisões baseadas em dados ao selecionar, ajustar ou implantar soluções de IA. Como parte fundamental do ecossistema de Produtividade, essas ferramentas garantem que os componentes de IA escolhidos sejam os mais eficazes e eficientes para uma determinada tarefa, otimizando diretamente os fluxos de trabalho e os resultados.
Recursos Principais
- Métricas de Desempenho do Modelo: Medem critérios objetivos como precisão, latência, taxa de transferência e outras pontuações relevantes (por exemplo, BLEU, ROUGE).
- Quadros de Líderes Comparativos: Fornecem comparações lado a lado de múltiplos modelos de IA nas mesmas tarefas para uma avaliação clara.
- Conjuntos de Dados Padronizados: Utilizam benchmarks reconhecidos pela indústria (por exemplo, MMLU, HumanEval) para avaliação objetiva e reproduzível.
- Análise de Custo-Desempenho: Calculam e comparam os custos da API com a qualidade dos resultados de diferentes modelos para determinar o ROI.
- Criação de Testes Personalizados: Permitem que os usuários criem e executem seus próprios testes usando seus dados, prompts e critérios de avaliação específicos.
Casos de Uso
Essas ferramentas são amplamente utilizadas por desenvolvedores de IA para seleção de modelos, cientistas de dados para validar modelos ajustados e gerentes de produto para avaliar o ROI de diferentes integrações de IA. Em ambientes corporativos, são cruciais para testes de regressão e para garantir um desempenho consistente da IA ao longo do tempo após atualizações de modelo.
Como Escolher
Ao selecionar uma ferramenta de Benchmarking de IA, considere a gama de modelos suportados (por exemplo, LLMs, modelos de imagem), a disponibilidade de benchmarks relevantes da indústria e a flexibilidade para criar suítes de avaliação personalizadas. Avalie também suas capacidades de integração com seu fluxo de trabalho de desenvolvimento existente e a clareza de seus painéis de relatórios e análises.
BenchmarkingCenários de aplicação
Selecionando o melhor LLM para suporte ao cliente
Uma empresa de tecnologia precisa construir um chatbot de IA para lidar com as consultas dos clientes. Eles usam uma ferramenta de benchmarking para testar três LLMs líderes (por exemplo, GPT-4, Claude 3, Gemini Pro) em um conjunto de dados de 1.000 tickets de suporte reais. A ferramenta mede automaticamente a precisão da resposta, as pontuações de polidez e a latência da API para cada modelo. O quadro de líderes resultante mostra claramente qual modelo oferece o melhor equilíbrio entre qualidade e velocidade para suas necessidades específicas, permitindo uma decisão confiante e baseada em dados para sua equipe de desenvolvimento.
Avaliando melhorias em modelos ajustados
Uma equipe de ciência de dados ajusta um modelo de código aberto para análise de documentos legais. Para provar seu valor, eles usam uma plataforma de benchmarking para comparar a versão ajustada com o modelo original e um proprietário. Ao executar um conjunto de testes personalizado de 200 consultas jurídicas, eles geram um relatório que mostra um aumento de 15% na precisão na identificação de cláusulas contratuais. Este resultado quantitativo justifica o investimento no ajuste e fornece evidências claras de melhoria de desempenho para as partes interessadas.
Otimizando prompts para textos de marketing
Uma equipe de marketing precisa gerar textos publicitários de alta qualidade em escala. Eles usam uma ferramenta de benchmarking para testar A/B 20 variações de prompts diferentes em vários modelos de IA. A ferramenta automatiza o processo e pontua os resultados com base em critérios de qualidade predefinidos, como clareza e força da chamada para ação. Essa abordagem orientada por dados os ajuda a identificar a combinação de prompt e modelo de melhor desempenho, que pode ser integrada ao seu fluxo de trabalho de conteúdo para produzir consistentemente materiais de campanha mais eficazes.
Teste de regressão de sistemas de IA
Uma empresa atualiza o modelo de IA central em seu sistema de gerenciamento de conhecimento interno. Antes de implantar, a equipe de controle de qualidade usa uma ferramenta de benchmarking para executar um conjunto predefinido de 500 testes que cobrem funcionalidades-chave. A ferramenta compara os resultados do novo modelo com a linha de base da versão anterior, sinalizando quaisquer quedas significativas no desempenho. Isso garante que as atualizações não introduzam regressões inadvertidamente, mantendo a confiabilidade do sistema e a confiança do usuário.
Controlando os custos da API de IA
A aplicação de uma startup depende muito de uma API de texto para imagem, e os custos estão aumentando. Eles usam uma ferramenta de benchmarking para avaliar três modelos alternativos mais baratos. Eles testam todos os modelos em 100 prompts representativos, comparando a qualidade da imagem de saída, a aderência ao estilo e o custo por imagem. A análise revela um modelo que é 40% mais barato e atende a 90% de seus requisitos de qualidade. Esses dados permitem que eles façam uma mudança estratégica, reduzindo significativamente os custos operacionais sem um grande comprometimento na qualidade do produto.
Pesquisa acadêmica sobre capacidades de modelos
Pesquisadores universitários estão estudando as capacidades de raciocínio de LLMs emergentes. Eles utilizam uma plataforma de benchmarking para executar sistematicamente o benchmark ARC (AI2 Reasoning Challenge) em cinco modelos de código aberto diferentes. A plataforma automatiza a execução, coleta os resultados e fornece ferramentas de visualização para análise. Isso acelera significativamente o processo de pesquisa, permitindo que eles se concentrem na interpretação dos dados e na publicação de suas descobertas comparativas, em vez da configuração e execução manual de testes.