
Strom Synergy
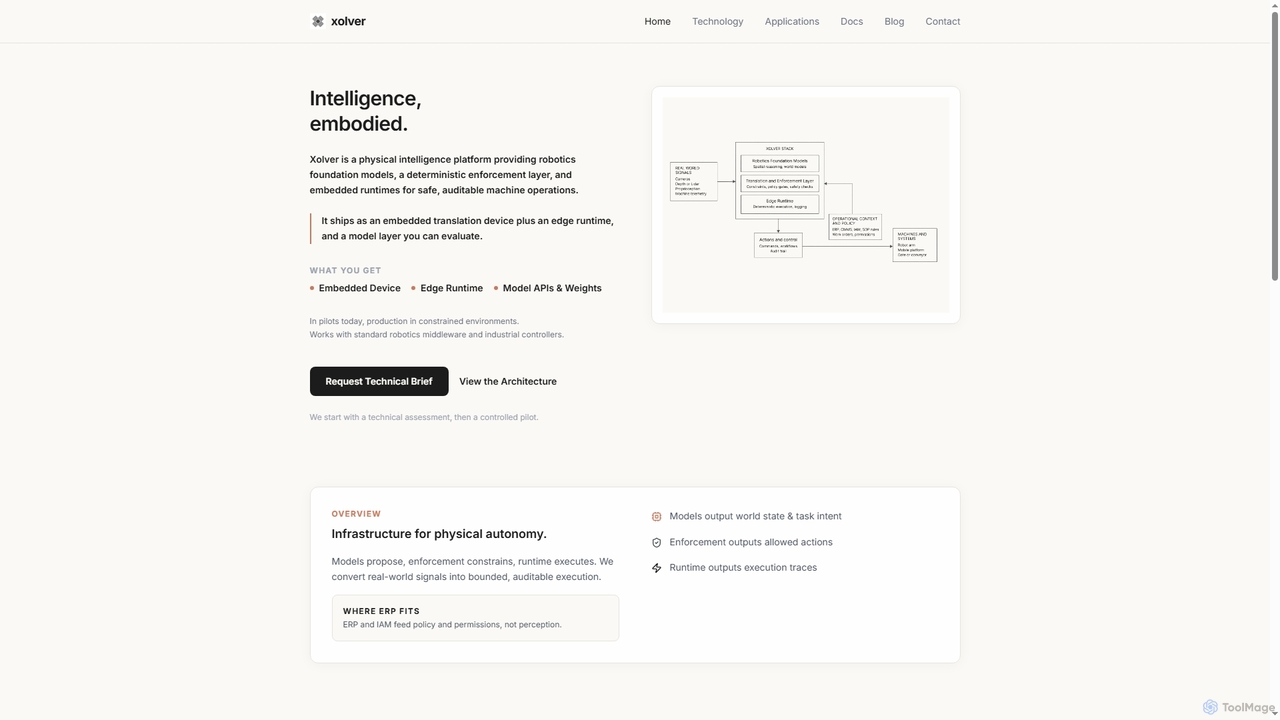
Strom Synergy 是一家總部位於新加坡的防雷系統 (LPS) 專業供應商。他們為住宅、商業和工業地產提供全面的服務,包括審計、維護、設計和安裝,確保安全並符合法規標準。
Strom Synergy 是一家總部位於新加坡的防雷系統 (LPS) 專業供應商。他們為住宅、商業和工業地產提供全面的服務,包括審計、維護、設計和安裝,確保安全並符合法規標準。
thecatseye
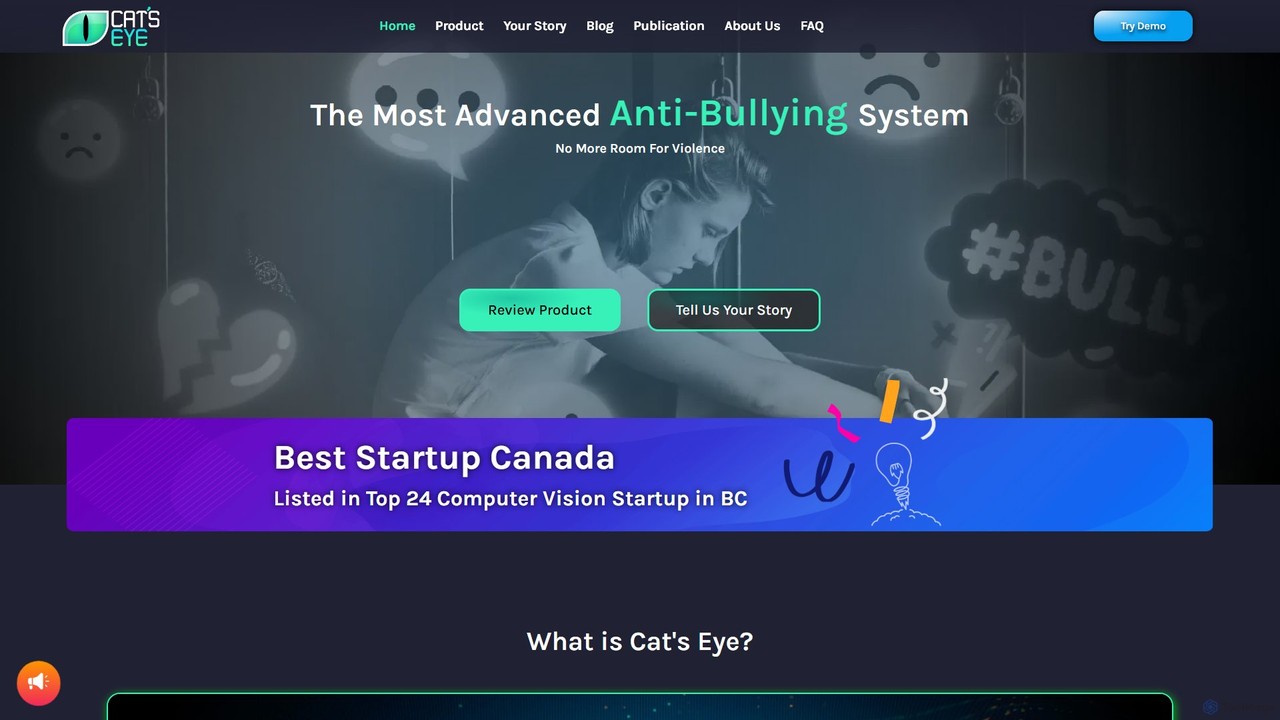
The Cat's Eye 是一款先進的 AI 反霸凌系統,專為學校設計。它利用電腦視覺和音訊分析,從現有的監控系統中即時偵測語言和身體暴力,並向教職員工發送即時警報,以便迅速干預,創造更安全的教育環境。
The Cat's Eye 是一款先進的 AI 反霸凌系統,專為學校設計。它利用電腦視覺和音訊分析,從現有的監控系統中即時偵測語言和身體暴力,並向教職員工發送即時警報,以便迅速干預,創造更安全的教育環境。
Water-Jel Blanket
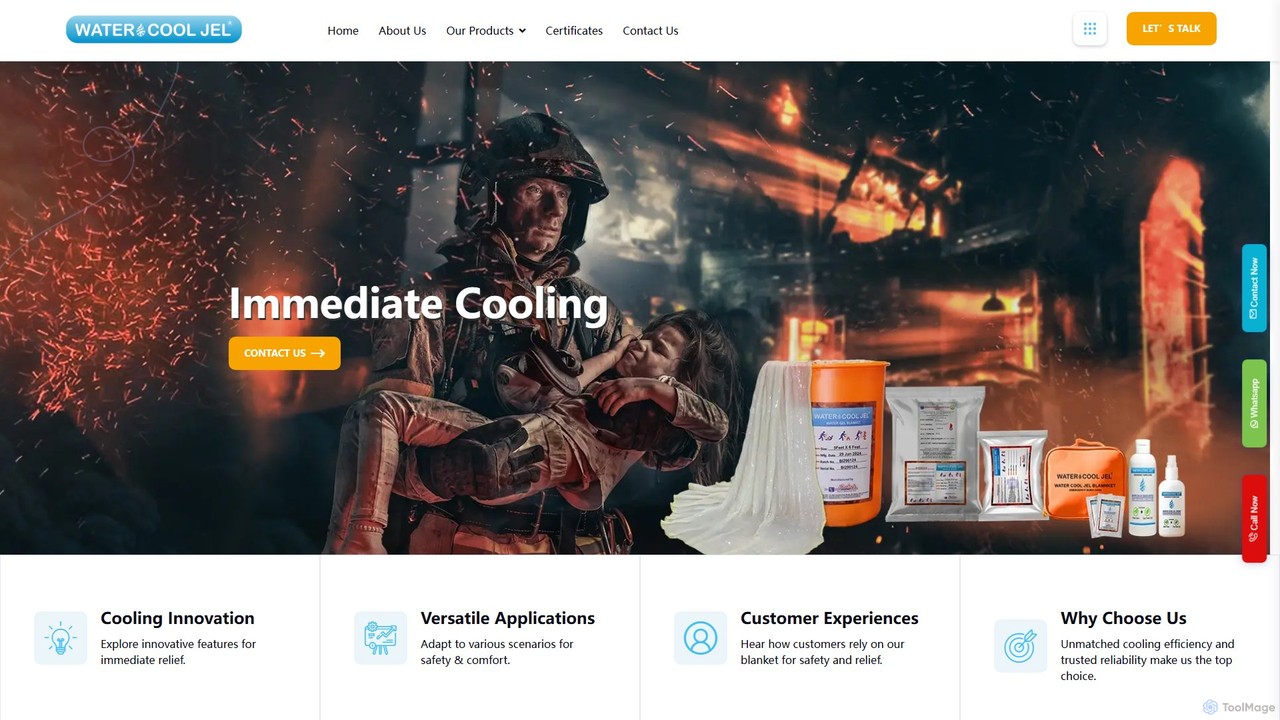
由Balaji Industries生產的Water-Jel Blanket是一款專業級緊急燒燙傷護理產品。這款水基凝膠浸泡的毯子能為熱燒燙傷提供即時冷卻和疼痛緩解。其設計具有不沾黏特性,能中止燒燙傷過程,防止污染,是急救人員、工業安全和家庭急救箱的必備品。提供多種尺寸以適應不同應用場景。
由Balaji Industries生產的Water-Jel Blanket是一款專業級緊急燒燙傷護理產品。這款水基凝膠浸泡的毯子能為熱燒燙傷提供即時冷卻和疼痛緩解。其設計具有不沾黏特性,能中止燒燙傷過程,防止污染,是急救人員、工業安全和家庭急救箱的必備品。提供多種尺寸以適應不同應用場景。
關於 安全
AI安全工具是一類旨在確保人工智能系統可靠、合乎道德且安全運行的軟體。它們利用先進演算法來識別、監控和緩解潛在風險,例如模型偏見、有毒內容生成、資料洩露和對抗性攻擊。這些工具對於開發者、企業和合規團隊建立可信賴的AI、遵守法規以及防止AI應用程式造成意外傷害至關重要。透過提供一個保護層,它們使得強大的AI技術能夠被負責任地部署。
核心功能
- 偏見與公平性稽核:分析模型和資料集,以偵測和衡量人口或社會偏見。
- 內容審核:掃描並過濾AI生成的文字和圖像中的有害、有毒或不當內容。
- 對抗性攻擊防禦:識別並保護模型免受旨在導致故障或洩露資料的惡意輸入。
- 資料隱私與匿名化:偵測並編輯訓練資料中的個人可識別資訊(PII),以確保合規。
- 可解釋性(XAI):提供關於AI模型如何做出決策的洞察,增加透明度和問責制。
適用場景
AI安全工具在各個行業都至關重要。在社交媒體領域,它們驅動內容審核系統,創造更安全的網路環境。金融機構用其稽核貸款模型的公平性,防止歧視性結果。在醫療保健領域,這些工具有助於確保AI驅動的診斷系統的可靠性和隱私。它們也是保護用於客戶服務的大型語言模型(LLM)免受操縱和濫用的基礎。
選擇要點
選擇AI安全工具時,首先評估與您的AI應用程式相關的特定風險(例如,內容毒性與模型偏見)。評估其與您現有MLOps管道和開發工作流程的整合能力。驗證其與您使用的模型類型(如LLM、擴散模型、分類器)的相容性。最後,考慮其是否符合相關法規標準,例如歐盟《AI法案》或GDPR,以確保合規。
安全應用場景
審核線上社群內容
社交媒體平台的信任與安全團隊整合了一款AI安全工具,用於即時自動掃描用戶生成的貼文、評論和圖片。該工具能夠識別並標記涉及仇恨言論、騷擾和暴力畫面的內容,從而大幅減少了需要人工審核員審查的有害材料數量。這使得平台能更快地回應違規行為,並有助於為用戶創造一個更安全的環境,保護平台的品牌聲譽。
審計招聘演算法的偏見
人力資源部門使用一款公平性審計工具來分析其新的人工智能履歷篩選模型。該工具使用一組多樣化的合成個人資料對模型進行測試,以確定其是否會因性別、種族或與年齡相關的語言而對候選人產生不公平的懲罰。生成的報告提供了可行的見解和視覺化圖表,使開發團隊能夠減輕已識別的偏見,並確保招聘流程更加公平,符合反歧視法律。
保護LLM免受提示注入攻擊
一家開發客戶服務聊天機器人的公司整合了一款安全工具,該工具充當其大型語言模型(LLM)的防火牆。此工具檢查所有傳入的用戶提示,以偵測並阻止提示注入和越獄企圖。透過阻止惡意用戶繞過安全過濾器,它確保聊天機器人不會生成有害回應、洩露敏感系統資訊或執行未經授權的操作,從而維護AI服務的完整性和安全性。
過濾不當的AI生成圖像
一個AI藝術生成平台部署了一個安全過濾器,以防止創建不適宜工作場所(NSFW)、暴力或仇恨的圖像。該工具分兩個階段工作:首先,它掃描用戶提示中的違禁關鍵詞和概念;然後,在向用戶顯示圖像之前,分析生成的圖像是否存在視覺上的違規內容。這種主動過濾有助於自動執行社群準則,降低法律和聲譽風險,並維持平台上的積極用戶體驗。
為醫療AI訓練匿名化資料集
一家研究機構在準備用於訓練診斷AI的大型病患記錄資料集時,使用了一款安全工具來確保資料隱私。該工具會自動掃描所有文件和結構化資料,以偵測並編輯超過15種類型的個人可識別資訊(PII),包括姓名、地址和病歷號。這個過程將資料匿名化,使研究人員能夠在完全遵守HIPAA和GDPR等嚴格隱私法規的同時,建構強大的模型。
驗證金融領域AI模型的穩健性
一家銀行的MLOps團隊使用一款AI安全工具,對其基於AI的詐欺偵測系統進行穩健性測試。該工具透過對交易資料進行微小而惡意的更改來模擬複雜的對抗性攻擊,以觀察模型是否會被欺騙從而做出錯誤的預測(例如,將詐欺交易分類為合法交易)。測試結果突顯了漏洞,使團隊能夠加固模型的防禦能力,並提高其在應對真實世界詐欺企圖時的可靠性。