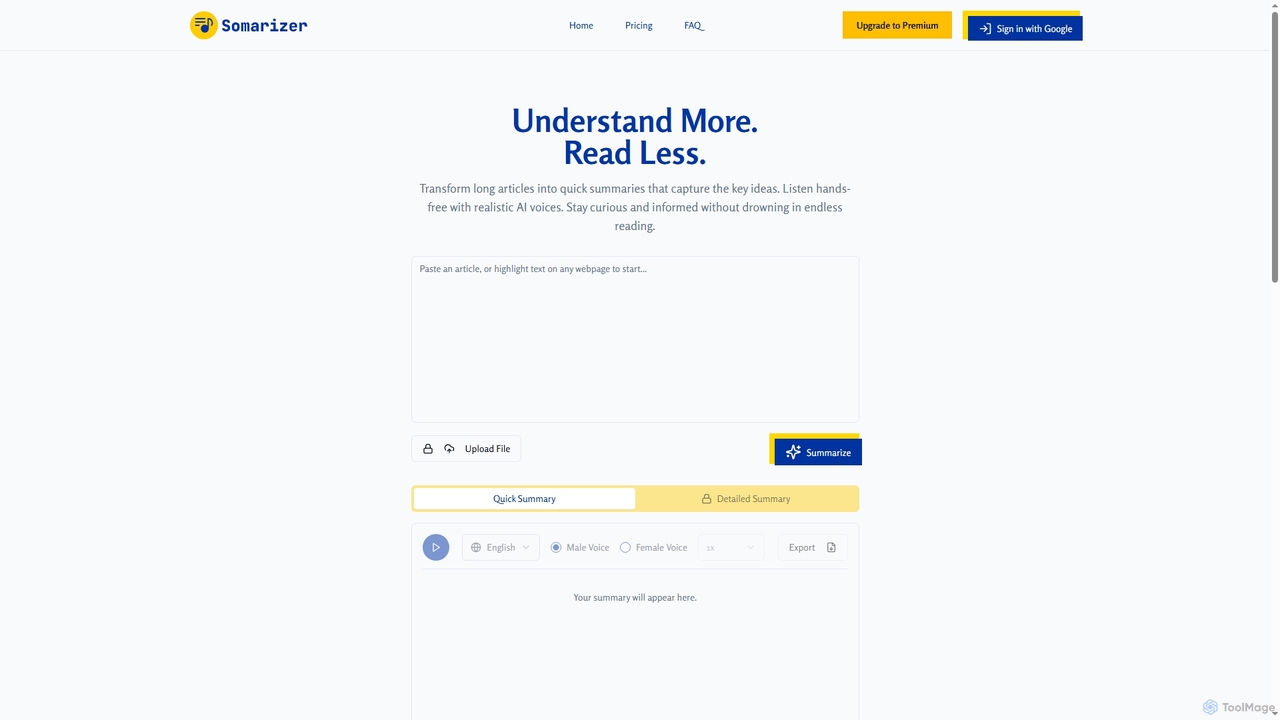
Somarizer
Somarizer ist ein KI-gestütztes Werkzeug, das lange Artikel und Dokumente in prägnante Zusammenfassungen umwandelt. Es bietet sowohl schnelle …
Somarizer ist ein KI-gestütztes Werkzeug, das lange Artikel und Dokumente in prägnante Zusammenfassungen umwandelt. Es bietet sowohl schnelle als auch detaillierte Zusammenfassungen, Text-to-Speech mit realistischen KI-Stimmen und unterstützt verschiedene Dateiformate wie PDF, Bild und Text. Ideal für Studenten, Forscher und Fachleute, um Zeit zu sparen und Informationen effizient aufzunehmen.
newsletter2podcast
Verwandeln Sie Ihre Lieblings-E-Mail-Newsletter mühelos in ansprechende Podcasts. Mit fortschrittlicher KI-gestützter Text-to-Speech-Technologie wandelt newsletter2podcast geschriebene Inhalte in hochwertiges, …
Verwandeln Sie Ihre Lieblings-E-Mail-Newsletter mühelos in ansprechende Podcasts. Mit fortschrittlicher KI-gestützter Text-to-Speech-Technologie wandelt newsletter2podcast geschriebene Inhalte in hochwertiges, natürlich klingendes Audio um, sodass Sie Ihre Abonnements unterwegs anhören können. Perfekt für vielbeschäftigte Berufstätige, Pendler und auditive Lerner.
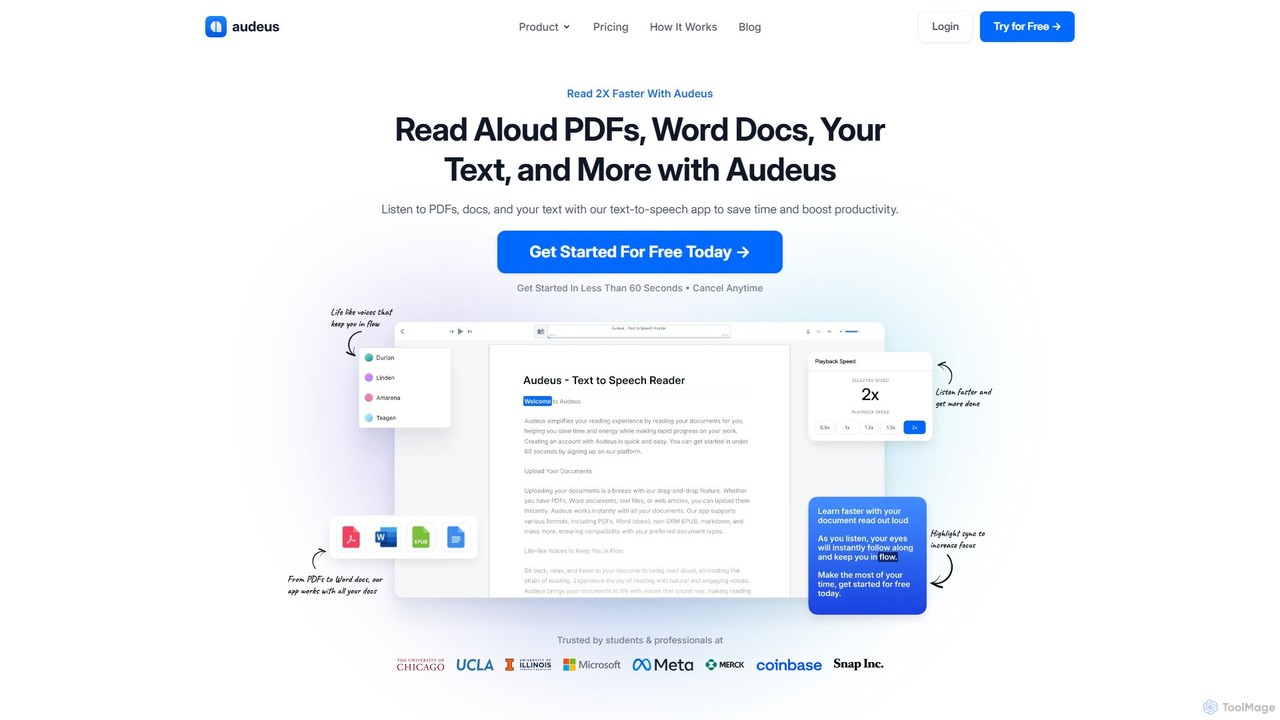
Audeus
Audeus ist ein fortschrittlicher KI-gestützter Text-to-Speech (TTS) Reader, der Dokumente, Webartikel und Texte in natürlich klingendes Audio umwandelt. …
Audeus ist ein fortschrittlicher KI-gestützter Text-to-Speech (TTS) Reader, der Dokumente, Webartikel und Texte in natürlich klingendes Audio umwandelt. Er ist für Studenten, Berufstätige und alle konzipiert, die ihre Produktivität steigern, den Fokus verbessern und Informationen effektiver aufnehmen möchten. Durch gleichzeitiges Hören und Lesen mit synchronisierter Hervorhebung können Benutzer ihre Lesegeschwindigkeit verdoppeln, die Augenbelastung reduzieren und das Verständnis verbessern. Es unterstützt verschiedene Formate wie PDF, Word und EPUB und funktioniert nahtlos auf allen Geräten.
Über Text zu Sprache
Text-zu-Sprache (TTS)-Tools sind eine Klasse von KI-Software, die geschriebenen Text in natürlich klingende gesprochene Audiodaten umwandelt. Sie nutzen fortschrittliche neuronale Netze und Deep-Learning-Modelle, um menschenähnliche Stimmen mit realistischer Intonation und Emotion zu synthetisieren. Diese Technologie ist grundlegend für die Erstellung barrierefreier Inhalte, die Produktion von Audiomaterialien wie Podcasts und Hörbüchern und die Integration von Sprachschnittstellen in Anwendungen. Moderne TTS-Systeme bieten eine breite Palette an Stimmen, Sprachen und Anpassungsoptionen und gehen weit über roboterhafte Monotonie hinaus.
Kernfunktionen
- Natürliche Sprachsynthese: Erzeugt menschenähnliche Sprache mit realistischem Tonhöhenverlauf, Klang und Tempo, die oft nicht von einem menschlichen Sprecher zu unterscheiden ist.
- Mehrere Sprachen & Akzente: Unterstützt eine riesige Bibliothek globaler Sprachen und regionaler Akzente, was die Erstellung von Inhalten für ein weltweites Publikum ermöglicht.
- Stimmenanpassung (SSML): Ermöglicht die Feinabstimmung von Aussprache, Geschwindigkeit, Lautstärke und Emotion mithilfe der Speech Synthesis Markup Language für präzise Kontrolle.
- Stimmenklonen: Erstellt eine digitale Nachbildung der Stimme einer bestimmten Person aus einer kurzen Audio-Probe, was personalisierte und konsistente Erzählungen ermöglicht.
- API-Zugriff: Bietet programmatischen Zugriff für Entwickler, um TTS-Funktionen direkt in Websites, Anwendungen und andere Software zu integrieren.
Anwendungsfälle
Diese Tools werden häufig von Content-Erstellern zur Produktion von Voiceovers für YouTube-Videos und Podcasts, von Pädagogen zur Erstellung ansprechender E-Learning-Materialien und von Entwicklern zum Bau von sprachgesteuerten Apps verwendet. Sie sind auch ein Eckpfeiler der Barrierefreiheit, der sehbehinderten Nutzern den Konsum digitaler Inhalte über Screenreader ermöglicht.
Wie man wählt
Bei der Auswahl eines Text-zu-Sprache-Tools sollten Sie die Natürlichkeit und Qualität der Stimmen, die Bandbreite der verfügbaren Sprachen und Akzente sowie den Grad der angebotenen Anpassung (z. B. SSML-Unterstützung) berücksichtigen. Bewerten Sie auch die Benutzerfreundlichkeit der Oberfläche, die Verfügbarkeit und Dokumentation der API für die Integration und das Preismodell (z. B. pro Zeichen, abonnementbasiert).
Text zu SpracheAnwendungsfälle
Erstellung von Voiceovers für Videoinhalte
Content-Ersteller wie YouTuber und Marketing-Teams verwenden Text-zu-Sprache-Tools, um hochwertige Voiceovers für ihre Videos zu generieren. Anstatt Sprecher zu engagieren oder ihre eigene Stimme zu verwenden, können sie einfach ein Skript eingeben, einen bevorzugten Stimmstil, ein Geschlecht und einen Akzent auswählen und die Audiodatei innerhalb von Minuten erstellen. Dieser Prozess reduziert die Produktionszeit und -kosten erheblich, ermöglicht einfache Skriptänderungen und Neugenerierungen und gewährleistet eine konsistente Audiomarke über alle Videoinhalte hinweg.
Produktion von Hörbüchern und E-Learning-Materialien
Verlage, Autoren und Unternehmenstrainer nutzen die TTS-Technologie, um langformatige Textinhalte wie Bücher und Schulungshandbücher in Audioformate umzuwandeln. Dies macht die Inhalte für sehbehinderte Personen zugänglich und spricht auditive Lerner an. Mit einem TTS-Tool können sie ein ganzes Hörbuch oder eine Reihe von E-Learning-Modulen mit einer konsistenten Erzählerstimme produzieren, ohne die logistischen Herausforderungen und hohen Kosten eines Aufnahmestudios und professioneller Sprecher. Erweiterte Funktionen ermöglichen Anpassungen von Tempo und Tonfall für verschiedene Kapitel oder Themen.
Entwicklung von interaktiven Sprachdialogsystemen (IVR)
Unternehmen und Callcenter nutzen TTS-APIs, um dynamische und natürlich klingende Sprachansagen für ihre IVR-Systeme zu erstellen. Anstatt jede mögliche Nachricht vorab aufzunehmen, was unflexibel und kostspielig ist, können Entwickler Antworten in Echtzeit generieren. Beispielsweise kann ein IVR den spezifischen Kontostand oder Bestellstatus eines Kunden vorlesen, indem diese Textdaten an die TTS-API übergeben werden. Dies ermöglicht hochgradig personalisierte Kundeninteraktionen und erleichtert die Aktualisierung von Systemnachrichten ohne neue Aufnahmen.
Verbesserung der Barrierefreiheit mit Screenreadern
Als Kernkomponente der Barrierefreiheit treibt die TTS-Technologie Screenreader für sehbehinderte Benutzer an. Diese Anwendungen lesen digitalen Text von Websites, Dokumenten und Anwendungsoberflächen laut vor und ermöglichen es den Benutzern, Computer und Smartphones selbstständig zu navigieren. Entwickler, die Barrierefreiheitsfunktionen in ihre Produkte integrieren, verwenden hochwertige TTS-Engines, um ein angenehmeres und weniger ermüdendes Hörerlebnis als ältere, roboterhafte Stimmen zu bieten. Diese Anwendung ist entscheidend für die digitale Inklusion und die Gewährleistung eines gleichberechtigten Zugangs zu Informationen für alle.
Prototyping von Sprachbenutzeroberflächen (VUI)
UX/UI-Designer und Entwickler, die an sprachgesteuerten Produkten wie intelligenten Lautsprechern, Auto-Assistenten oder mobilen Apps arbeiten, verwenden TTS für schnelles Prototyping. Anstatt Platzhalter-Audio aufzunehmen, können sie eine TTS-API verwenden, um sofort Sprachfeedback für Benutzerbefehle zu generieren. Dies ermöglicht eine schnelle Iteration von Konversationsflüssen, das Testen verschiedener Stimmpersönlichkeiten und die Durchführung von Benutzertests mit realistischen Interaktionen früh im Designprozess, was erhebliche Zeit und Ressourcen spart, bevor man sich auf endgültige Sprecher festlegt.
Echtzeit-Audioerzeugung für dynamische Inhalte
Nachrichtenorganisationen, Finanzdatenanbieter und Social-Media-Plattformen nutzen TTS, um dynamische, textbasierte Updates automatisch in Audiostreams umzuwandeln. Beispielsweise kann eine Nachrichten-App eine Funktion „Diesen Artikel anhören“ anbieten, die eine Audioversion spontan generiert. Eine Börsenanwendung kann Echtzeit-Audio-Updates von Preisänderungen bereitstellen. Dieser automatisierte Prozess ermöglicht die sofortige Erstellung von Audioinhalten für Informationen, die sich häufig ändern, und macht sie für Benutzer zugänglich, die Auto fahren, Sport treiben oder aus anderen Gründen nicht auf einen Bildschirm schauen können.