Serpex
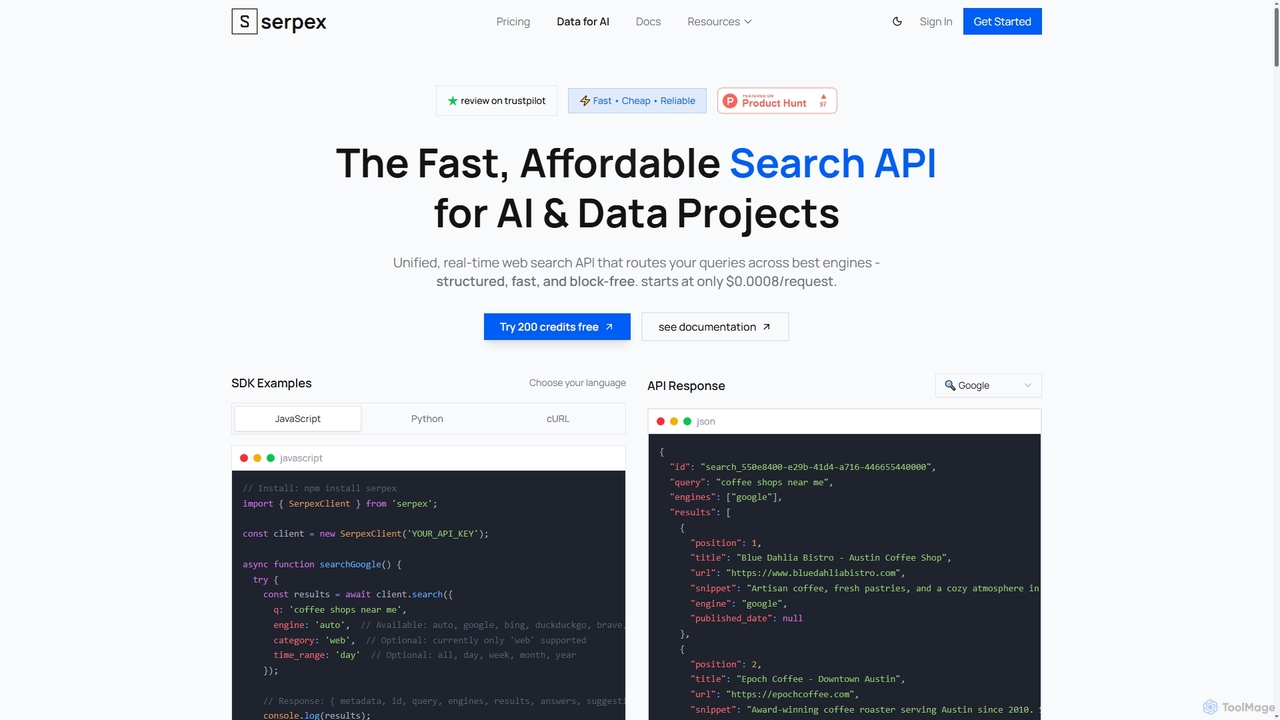
Serpex ist eine schnelle, erschwingliche und zuverlässige Such-API, die für KI- und Datenprojekte entwickelt wurde. Sie liefert strukturierte …
Serpex ist eine schnelle, erschwingliche und zuverlässige Such-API, die für KI- und Datenprojekte entwickelt wurde. Sie liefert strukturierte Web-Suchergebnisse in Echtzeit von mehreren großen Suchmaschinen und überwindet gängige Herausforderungen wie CAPTCHAs und Geoblocks.
Über Datenquelle
Datenquellen-Tools sind Plattformen und Dienste, die kuratierte, hochwertige Datensätze bereitstellen, die für das Training, die Validierung und das Testen von KI-Modellen unerlässlich sind. Diese Tools bieten Zugriff auf eine breite Palette von Datentypen, einschließlich Bildern, Text, Audio und strukturierten Daten, die oft vorverarbeitet und annotiert sind, um maschinelle Lernprozesse zu beschleunigen. Sie sind ein grundlegender Bestandteil der KI-Entwicklung und ermöglichen es Entwicklern und Forschern, robuste und genaue Systeme zu erstellen, ohne die unerschwinglichen Kosten und den Zeitaufwand für das Sammeln und Kennzeichnen von Daten von Grund auf. Durch die Bereitstellung von gebrauchsfertigen oder anpassbaren Datensätzen senken diese Tools die Eintrittsbarriere für die Erstellung anspruchsvoller KI-Anwendungen erheblich.
Kernfunktionen
- Vielfältige Datensatzbibliotheken: Zugriff auf umfangreiche Sammlungen von bereits vorhandenen, gekennzeichneten Datensätzen in verschiedenen Bereichen wie Computer Vision und NLP.
- Generierung synthetischer Daten: Fähigkeit, künstliche Daten zu erstellen, um reale Datensätze zu erweitern, Randfälle abzudecken oder die Privatsphäre zu schützen.
- Datenannotationsdienste: Integrierte oder Partnerdienste zur Kennzeichnung von Rohdaten, um sie für überwachte Lernmodelle geeignet zu machen.
- Datenqualität und Versionierung: Funktionen zur Gewährleistung der Datenkonsistenz, zur Verwaltung verschiedener Versionen von Datensätzen und zur Nachverfolgung der Datenherkunft für die Reproduzierbarkeit.
- API- und SDK-Zugriff: Programmatischer Zugriff zum Herunterladen, Streamen und Verwalten von Datensätzen direkt in Entwicklungsumgebungen.
Anwendungsfälle
Datenquellen-Tools sind für Machine-Learning-Ingenieure, Datenwissenschaftler und KI-Forscher von entscheidender Bedeutung. Sie werden zum Trainieren von Computer-Vision-Modellen zur Objekterkennung, zur Entwicklung von Anwendungen zur Verarbeitung natürlicher Sprache mit großen Textkorpora und zum Benchmarking der Leistung neuer Algorithmen im Vergleich zu etablierten Industriestandards verwendet. Diese Tools sind in Sektoren wie autonomen Fahrzeugen, dem Gesundheitswesen für die medizinische Bildanalyse und dem Finanzwesen für die Modellierung der Betrugserkennung von unschätzbarem Wert.
Wie man wählt
Bei der Auswahl eines Datenquellen-Tools sollten Sie die Relevanz und Qualität der Datensätze für Ihr spezifisches Problem berücksichtigen. Bewerten Sie die Lizenz- und Nutzungsrechte, um sicherzustellen, dass sie mit den kommerziellen oder Forschungszielen Ihres Projekts übereinstimmen. Beurteilen Sie die einfache Integration über APIs und die Datenverwaltungsfunktionen der Plattform, wie z. B. die Versionierung. Vergleichen Sie schließlich die Preismodelle, ob Open-Source, abonnementbasiert oder Pay-per-Use, um eine Lösung zu finden, die zu Ihrem Budget und Projektumfang passt.
DatenquelleAnwendungsfälle
Training eines Computer-Vision-Modells für autonomes Fahren
Ein KI-Startup, das Wahrnehmungssysteme für autonome Fahrzeuge entwickelt, benötigt einen riesigen und vielfältigen Datensatz von Straßenszenen. Anstatt Monate und erhebliches Kapital für das Sammeln und manuelle Annotieren von Bildern aufzuwenden, nutzt ihr ML-Team eine Datenquellen-Plattform. Sie greifen auf einen vor-gekennzeichneten Datensatz mit Millionen von Bildern zu, die Fußgänger, Fahrzeuge und Verkehrsschilder enthalten. Dies ermöglicht es ihnen, ihre Objekterkennungsmodelle schnell zu trainieren und zu iterieren, was ihren Entwicklungszyklus erheblich beschleunigt und die Modellgenauigkeit in kritischen Randfällen verbessert.
Feinabstimmung eines NLP-Modells für den Kundensupport
Ein Unternehmen möchte einen spezialisierten Chatbot für seinen technischen Support erstellen. Allzweck-Sprachmodelle fehlt der spezifische Fachjargon und der Kontext zur Problemlösung ihrer Branche. Ein Datenwissenschaftler im Team verwendet ein Datenquellen-Tool, um einen großen Korpus anonymisierter technischer Support-Gespräche und Dokumentationen zu erwerben. Durch die Feinabstimmung ihres Basis-Sprachmodells auf diese domänenspezifischen Daten erstellen sie einen Chatbot, der Benutzerprobleme mit hoher Genauigkeit versteht und relevante Lösungen bietet, wodurch die Arbeitsbelastung menschlicher Agenten reduziert wird.
Generierung synthetischer Daten für die medizinische Bildgebung
Ein Forschungsinstitut entwickelt ein KI-Modell zur Erkennung einer seltenen Krankheit aus MRT-Scans. Aufgrund des Patientenschutzes und der Seltenheit der Fälle haben sie einen sehr kleinen Datensatz, was zu einer Überanpassung des Modells führt. Das Forschungsteam verwendet ein Datenquellen-Tool mit Funktionen zur Generierung synthetischer Daten. Sie generieren Tausende von realistischen, aber künstlichen MRT-Scans, die verschiedene Stadien der Krankheit zeigen. Dieser erweiterte Datensatz ermöglicht es ihnen, ein robusteres und allgemeineres Modell zu trainieren, was die diagnostische Genauigkeit erheblich verbessert, ohne die Vertraulichkeit der Patienten zu beeinträchtigen.
Benchmarking eines neuen Empfehlungsalgorithmus
Das Data-Science-Team eines E-Commerce-Unternehmens hat einen neuartigen Empfehlungsalgorithmus entwickelt. Um seine Wirksamkeit zu beweisen, müssen sie ihn mit bestehenden Methoden auf einem standardisierten Datensatz vergleichen. Sie nutzen einen Datenquellen-Hub, um bekannte öffentliche Datensätze wie MovieLens oder Amazon Reviews herunterzuladen. Dies ermöglicht es ihnen, ein faires und reproduzierbares Experiment durchzuführen und Metriken wie Präzision und Recall zu messen. Die auf einem öffentlichen Datensatz gebenchmarkten Ergebnisse bieten eine glaubwürdige Grundlage für die Entscheidung, ob der neue Algorithmus in die Produktion überführt werden soll.
Training eines Betrugserkennungsmodells mit Transaktionsdaten
Ein Fintech-Unternehmen möchte sein Echtzeit-Betrugserkennungssystem verbessern. Ihre internen Daten sind begrenzt und decken möglicherweise aufkommende betrügerische Muster nicht ab. Sie abonnieren einen Datenquellen-Dienst, der große, anonymisierte und regelmäßig aktualisierte Transaktionsdatensätze bereitstellt. Durch das Training ihrer maschinellen Lernmodelle mit diesen umfangreichen Daten können sie subtile Korrelationen und Anomalien, die auf Betrug hindeuten, effektiver identifizieren. Dieser Zugang zu externen Daten ermöglicht es ihrem System, sich entwickelnden Bedrohungen einen Schritt voraus zu sein und finanzielle Verluste für ihre Kunden zu reduzieren.
Lokalisierung eines Sprachassistenten für neue Märkte
Ein Technologieunternehmen expandiert seinen KI-gestützten Sprachassistenten nach Südostasien. Um sicherzustellen, dass der Assistent lokale Akzente und Dialekte versteht, benötigen sie große Mengen hochwertiger Sprachdaten. Über einen auf Audio spezialisierten Datenquellen-Anbieter lizenzieren sie mehrsprachige Sprachdatensätze, die verschiedene Sprachen und regionale Akzente abdecken. Dies ermöglicht es ihrem Spracherkennungsteam, Modelle für jeden neuen Markt effizient zu trainieren und feinabzustimmen, was eine hohe Benutzererfahrung vom ersten Tag an gewährleistet und ihre globale Expansionsstrategie beschleunigt.